程序化交易入门(二)强化学习DQN及其衍生体
众所周知,强化学习在程序化量化交易里面已经扮演者愈来愈重要的角色,那么我们可以知道,Google的Alpha Go已经是强化学习中战胜人类的一个重要的 weapon,这里我们不得不提及强化学习,强化学习有以下三种
based的方法,这三种方法分别是
policy-based,
value-based以及
model-based的方法,这三种方法分别代表着三种不同的模型,那么google的
Alpha Go正是基于以上这三种方法的融合:
policy-based+value-based+model-based,这三种方法仅仅较适用于围棋。

1. 引入
1.1 Machine Learning在做什么?
Machine Learning就是在寻找一个可以拟合的损失函数,
1.2 DQN在寻找什么?
下面我们以一个简单的DQN的方式来做。
1.2.1 Step1. Neural Network as Actor

Actor就是一个Function,通常我们记为
,那么我们的输入输出维度是什么呢?Function的input就是机器看到的observation,他的output就是machine要采取的action。如果我们的Actor是Neural Network,那么我们这个过程就是一个Deep Reinforcement Learning,那么这个过程的observation就是一堆pixel,我们可以将其当成一个vector来进行描述或者是用一个matrix来描述,那么output就是我们的action,如果我们的input是一张image,那么我们的Actor就是CNN,那么我们到底有多少种output方式,那么我们的output就有多少种dimension。如下图打游戏图示所示:

但是在做Policy Gradient的时候,我们通常会假设Policy是stochastic,所谓stochastic就是说我们的outputs就是一个几率,如果你的分数是0.7,0.2,0.1,那么就是0.7的几率是left,0.2是right,0.1是fire。那么使用NN做一个action的好处是什么?
传统就是使用表来进行所有动作的存储,但是ANN就很好的解决了我们这个问题。
1.2.2 Goodness of function
我们要来决定一个Neural Network的好坏。在传统的监督学习中,我们会给定一个Neural Network一些参数,类似
,如果输出NN越类似我们的方程,那么我们就说这个网络是拥有越加的表现。
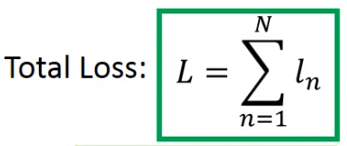
那么对于强化学习来说,我们怎么说其有着更好的表现呢?一个Actor的好坏也是非常的好坏,假设我们现在有一个NN了,那么一个Actor我们就用
来表示,这个网络的参数我们使用
来表示,同样的,我们可以使用s来表示这个网络所看到的observation,定义如下
,那么怎么知道我们的actor的表现好坏呢?那么我们就需要使用我们的actor来玩下游戏,假设其做了如下步骤:
- 1.Start with observation
- 2.Machine decides to take
- 3.Machine obtains reward
- 4.Machine sees observation
- 5.Machine decides to take
- 6.Machine obtains reward
- 7.Machine sees observation
- …
- n.Machine decides to take
- n+1.Machine obtains reward
这就是上面的整个过程,那么我们可以将完成整个游戏的total reward是R,那么这个R就是我们在这个episode索要最大化的对象,这个对象我们记为 。但是我们即使采用了相同的对象来玩这个游戏,但是玩这个游戏的时候,也会得到不同的结果,首先Actor如果是stochastic看到同样的场景也会采取不同的action,每次得到的 也是不一样,同样的,我们的游戏也是会有一个随机性,那么我们希望做的时候不是去max每次的 ,而是每次 ,也就是我们的 的一个期望值。我们希望这个期望值越大越好,这里衡量模型的好坏。我们假设一场游戏就是一个 ,那么 是一个sequence,这里面包含了observation,以及看到这个observation后得到的reward、还有新的observation、所采取的action以及得到的reward等等,这里组合形成一个sequence。下面我们定义 的符号:
那么我们来玩这个游戏,我们选择Actor的时候就会有一些 特别容易出现,也就是某些游戏过程特别容易出现,当我们Actor的参数是 的时候, 这个过程容易出现的几率。那么我们的R的期望值:
,当然这个值是一个连续的,有非常多的可能,可以穷举它,每一个 都有一个reward ,在累加所有的 即可得到期望的奖励。那么我们就需要把游戏玩n场游戏,玩了 次,得到了 ,后取平均,就可以得到我们的期望值。
1.2.3 pick the best function
这一步我们就要选择我们最好的Actor,这里我们就使用我们的Gradient Ascent,因为我们已经有我们的目标函数了,这里我们要最大化
,因为我们要max我们的某一个值。

使用这个方法我们就可以得到我们的最大值,这里我们仅仅需要对
来做微分,不需要对
做任何微分,即使其是一个黑盒。


 ### 1.2.4 Natural DQN以及其改进方式
### 1.2.4 Natural DQN以及其改进方式
- Stabilization:
- Doubel DQN
- Prioritized relay
- Modeling additional prior:
- Duelling network
- Exploration
- NoisyNet
- Large-scale implementation
1.4 几种假设
1.4.1 状态价值函数
我们有了上述的一个描述状态过程 的表示方式的时候,我们需要做一个很重要的假设后,我们需要做一个假设上帝不掷筛子!。在强化学习领域,我们相信输入是确定的,那么输出也就一定是确定的,那么有了时间和确定性的假设,MDP(Markov Decision Process)便是为了描述这个世界而提出的概念。
MDP(Markov Decision Process)马尔可夫决策过程就是基于这样的一种假设:未来仅取决于当前!也就是用数学的话来描述就是,一个状态
是一个Markov,那么当且仅当
其中,
为概率,简单的说就是下一个状态当前的动作注意,这里的状态是完全可观察的全部的环境状态(也就是所谓的上帝视角)。一个基本的MDP可以用(S,A,P)来表示,S代表状态,A代表动作,P代表状态转移概率。也就是根据当前的状态
以及
转移到
以及
的概率。如果我们知道了状态转移概率P,也就称我们获得了模型Model,有了模型,未来就是可以求得的,那么获取最优的动作也就是有了可能,这种通过模型来获取最优动作的方法也称为Model-Based的方法,但是在这种情况下,很多问题很难以获得准确的模型,因此有了Model-Free的方法来寻求最优的动作。关于具体的方法这里不具体讨论。
既然一个状态回应一个动作,那么我们就可以根据这个动作得到一个奖励,通过求这个奖励的期望来优化我们的模型参数,这里我们要引入一个价值函数以及一个Bellman Function。
由于每个状态时刻的状态是确定的,因此我们可以使用Value Function价值函数来描述这个状态的价值,从而来确定我们的决策方式,这里我们来用一个例子来说明Value Function价值函数。这里举一个投资的问题:
假设我们现在有一笔X美金的资金,我们眼前有3种选择方式来投资这笔资金,买卖或者原地不动放入银行,并且我们只能选择一种方式来执行我们的过程。Policy的意思就是我们有一套的Policy策略,我们基于这个策略进行操作:
if 股票跌: 我们就买入股票
else if 股票升:我们就卖出股票
else:我就是什么都不干,我就想放银行
这上面的伪代码就是表示一种极为简单的策略,那么我们把Policy策略看作是一个黑箱,那么基于策略的方法就是

那么好像这么做没有毛病,但是这里有一个巨大缺陷就是,基于上面的策略完全不考虑每一种选择对未来的价值影响,我们做决策是有目的的,那么就是为了最大化我们未来的投资汇报,那么对于这个闲钱的投资回报问题,我们的目标就是评估下每一种选择的潜在性价值。那么怎么评估?那我们有什么方式呢?
如下所示,我们可以换一种思维,使用状态或者动作+状态输入来获取我们的价值函数:

我们就评估每种状态(选择+股票涨跌)的价值,然后选择价值最高的作为最后的决策。比如说:
if 股票涨了:
因为未来几天内可能会有税率影响,价值为-100
if 股票跌了:
华为5g可期,虽然目前受美帝影响,但是以后股票必涨,价值+500
if 放入银行:
我可以先着,买车买房呀,很棒棒的选择,价值+300
…(更多的评估价值方法)
从数学的角度,我们常常会使用一个函数 来表示一个状态价值,也可以用 来表示状态及某一个动作的价值。我们上面例子就是评估某个状态下动作的价值,然后根据价值来做判断,实际上,我们这里是有策略的,我们仅仅是让我们的策略更加的简单:
if 某一个决策的价值最大:选择这个决策
这就是价值函数的意义。在后面的文章中,其实我们还可以同时使用策略加价值评估的方法来联合给出决策,这种方法就是所谓的Actor Critic算法。
1.4.2 Bellman方程
上面我们介绍了Value Function,那么我们就需要引入一些数学公式来完善这个函数,也就是一个回报 Result,也就是所有Reward的累加(带衰减系数discount factor)
也就是将Bellman方程展开可得:
上面这个公式就是Bellman方程的基本形态,从公式上看,当前状态的价值和下一步的价值以及当前反馈的Reward有关。
1.4.3 Action-Value function动作价值函数
前面我们引入了价值函数,考虑到每个状态之后都有很多动作可以选择,每个动作之下的状态又多不一样,我们更关心在某个状态下的不同动作的价值。显然,如果知道每个动作价值,就可以选择价值最大的一个动作去执行。有了上面的定义,动作价值函数就可以表示如下:
这里要说明的是动作价值函数的定义,加了
,也就是在策略下的动作值,对于每个动作,都需要策略根据当前的状态生成,因此必须有策略支撑。前面的价值函数不一定依赖于策略,当然,如果定义
则表示在策略
下的价值。
事实上我们会更多使用动作价值函数而不是价值函数,因为动作价值函数更直观,更方便应用于算法当中。
1.4.4 Optimal value function 最优价值函数
首先是要求出我们根据输入的状态以及价值要得到动作价值函数,并最大化我们的动作价值函数
也就是最优的动作价值函数就是所有策略下的动作价值函数的最大值,通过这样的定义就可以使最优的动作价值唯一性,从而可以求解整个MDP。
因为最优的Q值必然为最大值,所以,等式右侧的Q值必然为使a’取得最大的Q值。
1.4.5 策略迭代 Policy Iteration
本质上就是利用当前的策略产生新的样本,然后使用新的样本更好的估计策略的价值,然后利用策略的价值更新策略,然后不断反复。理论可以证明最终策略将收敛到最优。

这里要注意policy evaluation部分,这里迭代最重要一点就是需要state状转移概率p,也就是说依赖于model模型。而且按照算法要反复迭代直到收敛为止。所以一般需要做限制。比如到达某一个比率或者次数就停止迭代。
1.4.6 Value Iteration 价值迭代

问题来了:
- Policy Iteration和Value Iteration有什么本质区别?
- 为什么一个叫Policy Iteration另一个叫Value Iteration?
原因很好理解,Policy Iteration使用bellman方程来更新value,最后收敛的是value。最后收敛的value即是 当前policy下的value(所以叫做对policy方法进行评估),目的是为了后面的policy improvement得到新的policy。
而value iteration是使用bellman最优方程来更新value,最后收敛得到的value即是 局势当前state状态下最优的value值。因此,只要最后收敛,那么最优的policy也就得到。因此这个方法是基于更新value的,所以叫value iteration。
若我们使用动作-价值函数,也是同样的,仅仅是将value换成了Q值,怎么能有下一个Q值呢?没有错,所以我们只能使用之前的Q值,也就是每次根据新的得到的reward和原来Q值来更新现在的Q值。理论上可以证明这样的value iteration能够使Q值收敛到最优的action-value function。
1.4.7 Q-Learning
Q-Learning思想完全就是根据value iteration得到,但是要明确一点是value iteration每次都对所有的Q值更新一遍,也即是所有的动作状态。但事实上,在实际情况下我们没有办法遍历所有的动作状态,我们只能采取有限样本进行操作,那么Q-Learning提出了一种新的更新方法。
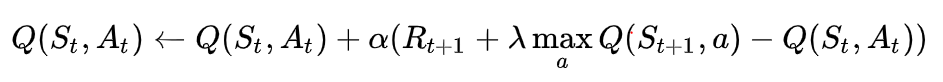
具体算法如下:

1.4.8 Exploration and Exploitation 探索与利用
在上面的算法中,我们可以看到需要使用某一个policy来生成动作,也就是说,这个policy不是优化的那个policy,所以Q-Learning算法叫做Off-policy算法。另外,因为Q-Learning完全不考虑model模型也就是环境的具体情况,只考虑看到的环境及reward,因此是model-free的方法。
回到policy问题,那么要选择怎样的policy来生成action呢?有两种做法:
- 随机生成一个动作
- 根据当前的Q值计算出一个最优的动作,这个policy 称之为greedy policy贪婪策略。也就是
- 使用随机的动作就是
exploration,也就是探索未知的动作会产生的效果,有利于更新Q值,获得更好的policy。而使用greedy policy也就是target policy则是exploitation,利用policy,这个相对来说就不好更新出更好的Q值,但可以得到更好的测试效果用于判断算法是否具有效果。
将两者结合起来就是所谓的e-greedy策略,e一般是一个很小的值,作为选取随机动作的概率值。可以更改e的值从而得到不同的exploration和explotiation的比例。
2. DQN
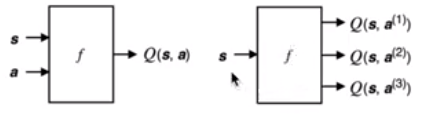
有了上面的一个经验,我们就可以得到我们两种DQN的输入方式,第一种,就是:
1.使用我们的state以及action作为输入,来得到我们的Q(s,a)
2.仅仅使用我们的state来作为输入,最后来得到我们的Q(s,a)
上述两种方法如下图所示:
2.1 Nature DQN
基本的DQN算法,也就是NIPS 2013版本,Deep Mind团队就不断对DQN进行改进,2015年首先于Nature上发布文章,提出了Nature版的DQN,接下来就提出了Double DQN,Prioritied Replay,还有Dueling Network三种方法,极大提升DQN的性能,目前很多改进型DQN算法在Atari游戏的平均得分是Nature版DQN的三倍多。
NIPS DQN在基本的Deep Q-Learning算法基础上使用了Experience Relay经验池。通过将训练得到的数据存储起来然后随机采样的方法降低数据相关性。接下来,Nature DQN做了一个改进,就是增加Target Q网络。也就是我们在计算目标Q值时使用专门的一个目标Q网络来计算,而不是直接使用预更新的Q网络。这样做的目的是为了减少目标计算与当前值的相关性。
如上面的损失函数公式所示,计算目标Q值的网络使用的参数是
,而不是
。就是说,原来NIPS版本的DQN目标网络Q网络是动态变化的,跟着Q网络的更新而变化,这样不利于计算目标Q值,导致目标Q值和当前的Q值相关性较大。因此提出单独使用一个目标Q网络。那么目标Q网络的参数如何来呢?还是从Q网络中来,只不过是延迟更新。也就是每次等训练了一段时间再将当前Q网络的参数值复制给目标Q网络。从Nature论文来看:

2.1.1 DQN是否有什么问题?应该如何改进?
Nature-DQN提出来后,很多人思考如何改进,那么DQN有什么问题吗?
- 目标Q值的计算准确吗?全部通过
max Q来计算有没有问题? - 随机采样的方法好吗?按道理不同样本的重要性是不一样的
- Q值代表状态,动作的价值,那么单独动作价值评估是否会更加准确?
- DQN中使用e-greedy的方法来探索局部空间,有没有更好的做法?
- 使用卷积神经网络结果是否有局限?加入RNN呢?
- DQN无法解决一些维度较高的
Atari游戏例如Montezuma's Revenge,如何处理这些游戏? - DQN训练时间太慢?跑一个游戏需要好几天,有没有更快的更新方法?
- DQN训练是单独的,也就是一个游戏弄一个网络进行训练,有没有办法弄一个网络同时掌握多个游戏,或者训练某一个游戏后将知识迁移到新的游戏?
2.1.2 Double DQN, Prioritised Replay, Dueling Network三大改进
大幅度提升DQN玩Atari性能的主要就是Double DQN,Prioritised Relay还有Dueling Network三大方法。David Silver在ICML 2016中的Tutorial上做了介绍:

- Double DQN:目的是减少因为max Q值计算带来的计算偏差,或者称为过度估计(over estimation)问题,用当前的Q网络来选择动作,用目标Q网络来计算目标Q。
- Prioritised replay:也就是优先经验的意思。优先级采用目标Q值与当前Q值的差值来表示,优先级越高,那么采样的概率就高。
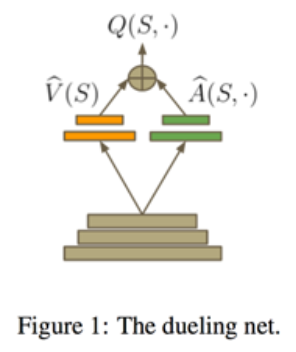
- Dueling Network:将Q网络分成两个通道,一个输出v,一个输出A,最后两个合起来得到Q,如下图所示,这个方法主要是idea很简单但是很难想到,后效果很好,因此也成了ICML的best paper。