版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/doudouzhang123/article/details/84997210
python爬虫学习爬虫(爬取指定网站数据)
- Python实现对主要城市及其周边地区天气数据的爬取,关键步骤已经做了注释此版本仅是初学者的学习版,不喜勿喷
#coding: utf-8
import re
from urllib import request
from bs4 import BeautifulSoup
#将要爬取的城市及其对应的链接存于不同的列表
cityLink=['http://www.weather.com.cn/weather1d/101270101.shtml#input',
'http://www.weather.com.cn/weather1d/101010100.shtml#input',
'http://www.weather.com.cn/weather1d/101020100.shtml#input',
'http://www.weather.com.cn/weather1d/101280101.shtml#input',
'http://www.weather.com.cn/weather1d/101210101.shtml#input',
'http://www.weather.com.cn/weather1d/101200101.shtml#input',
'http://www.weather.com.cn/weather1d/101190101.shtml#input',
'http://www.weather.com.cn/weather1d/101280601.shtml#input',
'http://www.weather.com.cn/weather1d/101190401.shtml#input',
'http://www.weather.com.cn/weather1d/101230201.shtml#input',
'http://www.weather.com.cn/weather1d/101220101.shtml#input',
]
cityName=['成都','北京','上海','广州','杭州',
'武汉','南京','深圳','苏州','厦门','合肥']
#获得链接对应的网页内容
def getSoup(url):
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content,'html.parser')
return soup
#获取地区
def getArea(Soup):
Area_list=[]
UL_Tag=Soup.find_all('ul',class_="clearfix city")
for each_LI in UL_Tag:
txtLI=each_LI.find_all('li')
for eachA in txtLI:
txtArea=eachA.find_all('span')
for eachs in txtArea: #筛选出地方
aroundArea=eachs.string
Area_list.append(aroundArea)
return Area_list
#获取温度字符串
def getTemprature(Soup):
Temprature_list=[]
UL_Tag=Soup.find_all('ul',class_="clearfix city")
#从包含周边城市地区及其温度的ul标签逐层向里,获取地区名和温度
for each_LI in UL_Tag:
txtLI=each_LI.find_all('li')
for eachA in txtLI:
txtTemperature=eachA.find_all('i')
for eachsI in txtTemperature:
Temprature=eachsI.string
Temprature_list.append(Temprature)
return Temprature_list
def Main():
# 从字符串找获得数字的正则表达,可以匹配整数,负数
pattern = re.compile(r'[\-|0-9][0-9]*')
print("城市 周边地区 最低温度 最高温度")
#将城市链接列表的每个城市,做爬取信息操作
for i in range(0,len(cityLink)):
soup=getSoup(cityLink[i])
Area_list=getArea(soup) #得到地区列表
Temprature_list=getTemprature(soup) #得到温度字符串列表
Max_temprature=[]
Mini_temprature=[]
for j in range(len(Temprature_list)):
#将获得的最高温度和最低温度存于列表中
temp_list=pattern.findall(Temprature_list[j])
#由于网页在夜间和白天的数据显示格式不同,
#用small和min函数消除网页内容变化对爬取数据的影响
big=max(int(temp_list[0]),int(temp_list[1]))
small=min(int(temp_list[0]),int(temp_list[1]))
Max_temprature.append(big)
Mini_temprature.append(small)
#打印输出
for k in range(len(Area_list)):
print("{:^}\t{:<}\t\t{:^}\t{:^}".format(cityName[i],
Area_list[k],Mini_temprature[k],Max_temprature[k],))
#运行主函数-----程序入口
Main()
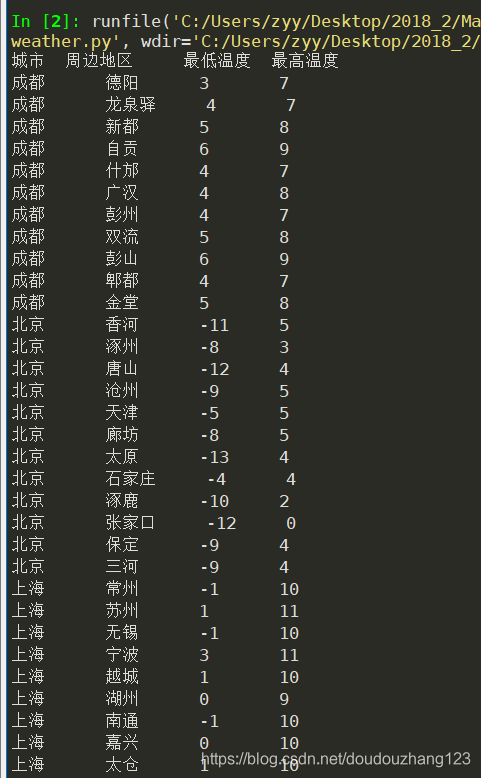
2.爬取结果如下(部分截图):