java8是最快的JVM?对于Fork-Join的基准性能测试
今天,我想继续讨论java8中的各种可以帮更好构建程序的工具。java8在几周前刚发布,不过,在RebelLabs的 Java 工具 & 技术 调查的早期结果显示,接近5%的调查者已经开始使用java8了。在工具部分,我将要讲述java微基准测试工具(Java Microbenchmark Harness,下面简称JMH)项目,它可以运行你产生更好的标准检查程序并且以一种健全的方式来描述你程序的性能。
这篇文章也关注加入到最新版本jdk中的并发方面的更新。实际上,java.util.concurrent有很多更新,但是这里仅仅关注对于Fork-Join框架的改进介绍。我们先稍微讨论一下Fork-Join,然后尝试实现一个示例基准测试来比较这个框架在java7和java上的性能。
你可能关心的Foin/Join
ForkJoin 是一个并行计算框架,通常用来处理递归任务。他首先在java7中被提出,并且起到了很好的作用。究其原因是因为大量的原生任务(many large tasks in their nature)可以以递归的形式表示出来。 举个例子,考虑一下最常见的一个MapReduce的例子:从一篇文档中计算不同单词出现的个数。显然,可以将文档拆分成多个部分,然后一个个的计算单词个数,最后将结果合并。事实上,ForkJoin是普通MapReduce理论的一种实现方式,只不过所有的工作者是运行在同一个JVM的线程,而不是一个主机集群。
ForkJoin框架的核心点是FrokJoinPool,它是一个http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/ExecutorService.html,因此他可以接收异步任务然后返回一个Future 对象,于是你就可以记录当前要计算的问题处在什么状态了。
跟其他ExecutorService类不同的是,他的工作者线程在当时不做任何兄弟节点的检查,也不从他们中获取任务。这项技术被称作生产盗用,那么什么是生产盗用呢? 
生产盗用是一种非中心化管理负载的方式,它没有一个确定的人来对所有可用的工作者线程指定工作,相反每个人都维护了他们自己的一个任务队列。这里的窍门就是高效的管理这些队列。
每个工作者线程在处理其各自队列的时候会产生两个问题: - 从外部提交的任务去哪了? - 我们怎么组织生产调用以便高效的访问队列?
从本质上说,从外部提交的任务和工作者本身在处理大型任务时创建的任务是没有区别的,他们的需求都是被执行并获得结果。但是从技术细节上讲是不同的,他们最大的不同是由工作者创建的任务是可以被盗用的,也就是说尽管被放到了一个指定的工作者的队列中,但依然可以被其他工作者执行。
ForkJoin 框架的处理方式是很直截了当的,每个工作者拥有两个队列,一个处理外部任务,另一个实现盗用功能。当外部调用发生时,随机选择加入一个工作者队列,当一个任务被拆分成若干小副本,工作者将其加入自己的队列,并期待同辈工作者能够来协助处理。
整个盗用概念是基于,一个工作者将任务添加其队列末尾的基础上。在正常执行过程中,每个工作者试图从队列的开头获取一个任务,如果获取任务失败,那就说明当前私有的队列中没有任务,于是从其他的工作者的队列的末尾中盗用一个任务。这样就允许省去在大部分队列上的加锁操作并且能够改善性能。
另一个是ForkJoin池运行的更快的技巧是当一个工作者盗用任务时,他留下了哪个队列被盗用和这个队列的原本归属者的提示,以便查询和帮助这个工作者,于是父任务的进度被加快了
所有的这一切都是十分复杂处理需要在后台做大量的运算来保证其运行。同时,这个系统的性能要求的很严格,所以我怀疑在没有重大重构的情况下是否能够有重大的改进。
java7中ForkJoin的不足
ForkJoin是从java7引入的,并且表现不错。但是由于java8的并发更新,ForkJoin又得以改进。从线面的java改进报告中,我们可以找到哪些地方被改进:
添加并改进ForkJoinPools的功能和性能,以允许他们被更高效的、广泛的使用于用户所期待的日益增长的应用中。新增特性包括支持通常十分适合IO密集型的completion-based 设计等。
另一个关于改进作者的观点,比如说一个来自Doug Lea的比较老的更新:
Substantially better throughput when lots of clients submit lots of tasks. The idea is to treat external submitters in a similar way as workers — using randomized queuing and stealing. This also greatly improves throughput when all tasks are async and submitted to the pool rather than forked, which becomes a reasonable way to structure actor frameworks, as well as many plain services that you might otherwise use ThreadPoolExecutor for.
在大量客户端提交大量任务时有更好的吞吐量。当前想法是以和工作者相似的方式对待外部提交者——使用随机队列并且盗用。当所有的任务是异步的并且提交到池中,而不是被拆分(forked)时, 就能极大的改进吞吐量,这样构架角色框架(actor frameworks)就变成了一个合理的方式,同时一些普通服务也许可以使用ThreadPoolExecutor 替代。
但是,辨别哪些被确切的改动了,哪些细节被影响了,并不是一个容易的事情。相反,我们通过另外一个途径来解决这个问题。我将构造一个基准测试来模拟一个非常简单的FrokJoin运算,来衡量处理ForkJoin的开销和连续通过一个单独线程进行计算的开销。希望可以通过此来揭开具体的改进。
性能对比
于是,我构架了一个小的基础测试来找到java7和java8之间的不同。这里是一个github的仓库,如果你想自己尝试一下的话。
感谢oracle工程师们的最近的努力,OpenJDK现在包含了java微基准测试工具(JMH)项目,他专门用于创建基准测试,并且可以极尽可能的减少常见的微基准测试问题和错误。
现在我们通过Maven来将JMH引入项目,一切的配置比我们想象的都要简单。
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>0.4.1</version>
</dependency>
</dependencies>
写作本文时,最新版本的JMH内核是0.4.1,他包含了使用@param注解来使运行的基准测试拥有一些列的输入参数。这让我们远离了多次手动执行同一个基准测试的烦恼,别且可以方便的获得结果。
现在每个基准测试迭代都拥有其私有的ForkJoinPool 实例,这也帮助我们来比较java8中通用的ForkJoinPool和早期版本的不同。
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Warmup(iterations = 5, time = 3, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 20, time = 3, timeUnit = TimeUnit.SECONDS)
@Fork(1)
@State(Scope.Benchmark)
public class FJPBenchmark {
@Param({ "200", "400", "800", "1600"})
public int N;
public List<RecursiveTask<Double>> tasks;
public ForkJoinPool pool = new ForkJoinPool();
@Setup
public void init() {
Random r = new Random();
r.setSeed(0x32106234567L);
tasks = new ArrayList<RecursiveTask<Double>>(N * 3);
for (int i = 0; i < N; i++) {
tasks.add(new Sin(r.nextDouble()));
tasks.add(new Cos(r.nextDouble()));
tasks.add(new Tan(r.nextDouble()));
}
}
@GenerateMicroBenchmark
public double forkJoinTasks() {
for (RecursiveTask<Double> task : tasks) {
pool.submit(task);
}
double sum = 0;
Collections.reverse(tasks);
for (RecursiveTask<Double> task : tasks) {
sum += task.join();
}
return sum;
}
@GenerateMicroBenchmark
public double computeDirectly() {
double sum = 0;
for (RecursiveTask<Double> task : tasks) {
sum += ((DummyComputableThing) task).dummyCompute();
}
return sum;
}
}Sin,Cos和Tan是RecursiveTask的实例,Sin和Cos实际上没有被拆分成递归操作,Math.sin(input)和Math.cos(input)会被单独调用。Tan任务会被拆分一对Sin和Cos操作,然后返回拆分后的结果。
JMH解析代码,并且根据方法上标记的@GenerateMicroBenchmark注解生成基准测试。其他在类头部定义的注解指定了基准测试的选项:预热次数,计算入最终结构的次数,是否生成其他的JVM进程来运行基准测试,还有那些需要测量的数据,代码吞吐量,单位时间内函数运行了多少次。
@Params描述了要传递给基准测试的各种输入参数。总之,JMH很直接明了,创建基准测试不需要手动维护循环次数,时间,计算结果。
分别用java7和java8运行基准测试并生成结果。我分别使用了1.7.0_40和1.8.0
shelajev@shrimp ~/repo/blogposts/fork-join-blocking-perf » java -version
java version "1.7.0_40"
Java(TM) SE Runtime Environment (build 1.7.0_40-b43)
Java HotSpot(TM) 64-Bit Server VM (build 24.0-b56, mixed mode)
Benchmark (N) Mode Samples Mean Mean error Units
o.s.FJPB.computeDirectly 200 thrpt 20 27.890 0.306 ops/ms
o.s.FJPB.computeDirectly 400 thrpt 20 14.046 0.072 ops/ms
o.s.FJPB.computeDirectly 800 thrpt 20 6.982 0.043 ops/ms
o.s.FJPB.computeDirectly 1600 thrpt 20 3.481 0.122 ops/ms
o.s.FJPB.forkJoinTasks 200 thrpt 20 11.530 0.121 ops/ms
o.s.FJPB.forkJoinTasks 400 thrpt 20 5.936 0.126 ops/ms
o.s.FJPB.forkJoinTasks 800 thrpt 20 2.931 0.027 ops/ms
o.s.FJPB.forkJoinTasks 1600 thrpt 20 1.466 0.012 ops/ms
shelajev@shrimp ~/repo/blogposts/fork-join-blocking-perf » java -version
java version "1.8.0"
Java(TM) SE Runtime Environment (build 1.8.0-b132)
Java HotSpot(TM) 64-Bit Server VM (build 25.0-b70, mixed mode)
Benchmark (N) Mode Samples Mean Mean error Units
o.s.FJPB.computeDirectly 200 thrpt 20 27.680 2.050 ops/ms
o.s.FJPB.computeDirectly 400 thrpt 20 13.690 0.994 ops/ms
o.s.FJPB.computeDirectly 800 thrpt 20 6.783 0.548 ops/ms
o.s.FJPB.computeDirectly 1600 thrpt 20 3.364 0.304 ops/ms
o.s.FJPB.forkJoinTasks 200 thrpt 20 15.868 0.291 ops/ms
o.s.FJPB.forkJoinTasks 400 thrpt 20 8.060 0.222 ops/ms
o.s.FJPB.forkJoinTasks 800 thrpt 20 4.006 0.024 ops/ms
o.s.FJPB.forkJoinTasks 1600 thrpt 20 1.968 0.043 ops/ms
下面将结果以表格的形式给出,为了方便,使用图标的形式展现。 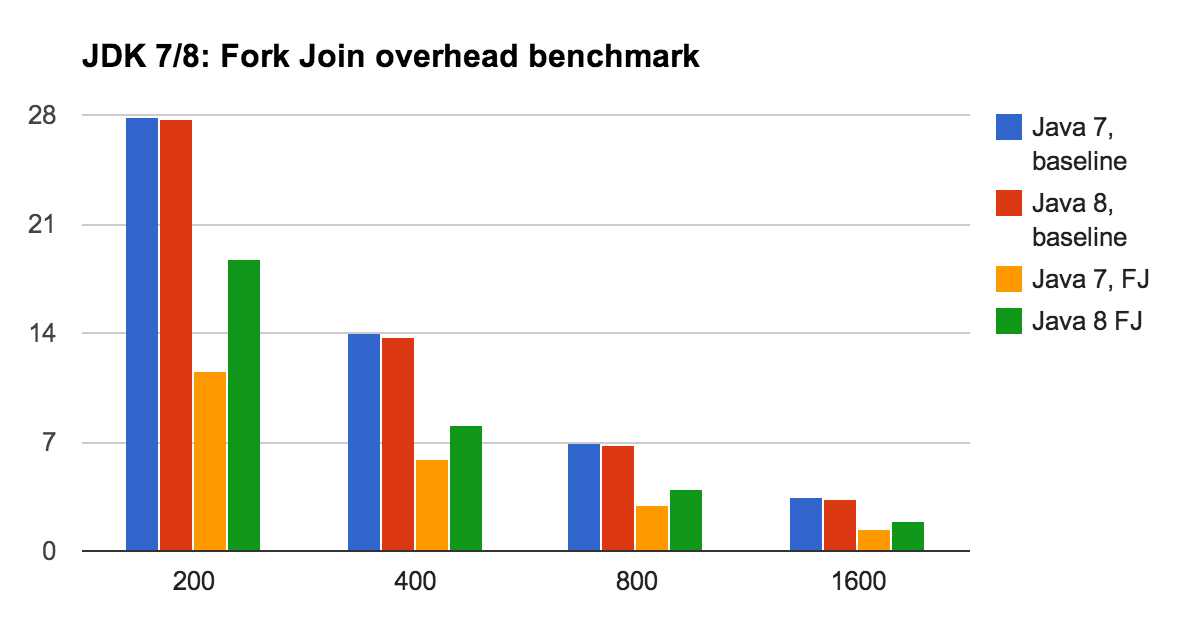
从基准结果可以看出,使用单线程的数学运算吞吐量在java7和java8中没有区别。但是当我们加入管理递归任务和运行ForkJoin的损耗后,Java8会快很多。从上面简单的基准测试可以看出管理ForkJoin任务的损耗在最新版本的java中要快接近35%。
之所以直接运算和ForkJoin运算的差别能够出来,是由于我们精心设计的递归任务非常轻量。除了一个单独的函数来调用数学类外它没有做其他任何多余的事情,也正由于此,直接使用数学函数的操作会更快。一个更重量级的任务会改变上述图片,不过他会减轻ForkJoin的管理损耗,这也会我们起初想要测量的地方。换句话说,你想让递归任务做的比一个函数调用要多。
同时,java7和8之间,直接调用测试产生的结果差异很小。这个差异很小,很有可能不是由于java7和8的数学函数实现的上不同造成的。也可能是JMH试图去均衡和避免两者之间的差异。
声明:当然结果是人为产生的,你可能对此持有怀疑态度。但是,在讨论java性能的同时,我也希望向你展示JMH允许你创建基准测试来避免普通基准测试中出现的问题,比如说JVM没有被预热。当你的基准测试是有缺陷的时候,他并不能拯救你,但是确实能够帮你解决很多事情。所以说,如果你发现代码中有逻辑上的缺陷的话,请告诉我,我喜欢变得更聪明。
总结
首先,我想说ForkJoin,ForkJoinPool.WorkQueue和ForkJoinTask的源码很难读懂,它里面标记了大量的Unsafe实现,也不可能在15分钟之内让人理解ForkJoin框架到底怎么实现的。

还好,这些类的文档很友好,并且在内部提供了大量的注释。当你闲暇下来的时候,你可以研究一下这个,这也许是JDK中最有趣的部分之一。
另外一个有意义的发现是,ForkJoin池在java8中的性能要更好,至少在现有的测试用例中是这样。虽然我不能确切的指出这背后的原因是什么,如果我将map/reduce在ForkJoin中使用,我可以碰碰运气试一下。
如果你发现逻辑上的错误或者能够对结果提供另外一种解释,或者能提供测试程序,请不要犹豫给我下面的@shelejev评论或者留言。

OLEG SHELAJEV
产品工程师
Oleg是一名java开发者,是在ZeroTurnaround公司Evangelist和RebelLabs部门的作家,关注可持续集成和交付。他还喜欢花时间在clojure,github和google docs上。他现在正在读动态系统更新和系统移植的博士学位,是一个塔尔图大学的兼职老师。作为一个RebelLabs的技术作家,Oleg经常写博客和流行报告。在他业余时间,他还是一个大师级的国际象棋玩家,喜欢填字游戏,乐于解决问题。他虽然不善交流,但是喜欢和大家相处。