这些东西见过很多遍,不少也用过很多遍,新年新开端,简单地系统总结一下吧。
目录
路径问题
宽度优先搜索
宽度优先搜索算法(又称广度优先搜索)系统地展开并检查图中的所有节点,以找寻结果。之所以称之为宽度优先算法,是因为算法自始至终一直通过已找到和未找到顶点之间的边界向外扩展。
算法首先搜索和s点距离为k的所有顶点,然后再去搜索和s点距离为k+1的其他顶点。自然界宽度搜索大概这样:

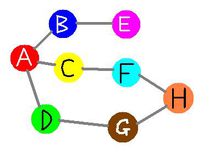
如下图,想从A到H,先看A-B,A-C,A-D,再看A-B-E,A-C-F,A-D-G,再看A-C-F-H,A-D-G-H。
深度优先搜索
深度优先搜索属于图算法的一种,英文缩写为DFS即Depth First Search.其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。
对于上图,想从A到H,先看A-B-E再看A-C-F-H,再看A-D-G-H。
A*算法
A*(A-Star)算法是一种静态路网中求解最短路径最有效的直接搜索方法,也是许多其他问题的常用启发式算法。
你想从绿点到红点,中间蓝色是墙,如果用宽搜索或深搜索,免不了要计算向左走(远离红点)的可能路径,所以引入运动步数和距红点距离进行启发判断。详见这个网址。

分类问题
K均值聚类算法(K-means)
K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
聚类中心迭代过程可如下所示:

邻近算法(kNN)
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。求出最合适的k并定义一个样本的类的过程为kNN。
下图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。

Adaboost
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。

支持向量机
支持向量机(Support Vector Machine, SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。如图,进行线性分类。
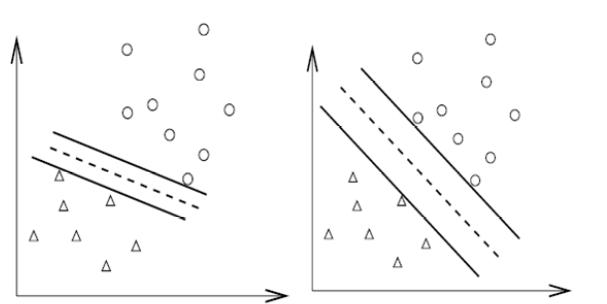
讲解见此。
寻优问题
模拟退火法
1.搜寻空间内一个任意点作起始,
2.每一步选择一个“邻居”,
3.然后再计算从现有位置到达“邻居”的概率,
4.根据概率到达周围“邻居”,到2循环,
5.到点循环稳定(或循环次数达到某值)停止
也可如图理解:

禁忌搜索
禁忌搜索(Tabu Search,TS,又称禁忌搜寻法)是一种现代启发式算法,是一个用来跳脱局部最优解的搜索方法。其先创立一个初始化的方案;基于此,算法“移动”到一相邻的方案。经过许多连续的移动过程,提高解的质量。和模拟退火一样,是基于个体的启发式算法。
给以禁忌表H,并选定一个初始解x;满足停止规则时,停止计算,输出结果;否则,在x的邻域N(x)中选出满足不受禁忌的候选集Can_N(x);在Can_N(x)中选一个评价值最佳的解x1,x=x1;更新历史记录H,重复STEP2。
更详细论述见此。
遗传算法
遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度大小选择个体,并借助于自然遗传学的遗传算子进行组合交叉和变异,产生出代表新的解集的种群。这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码,可以作为问题近似最优解。

粒子群算法(PSO)
PSO中,每个优化问题的解都是搜索空间中的一只鸟。我们称之为“粒子”。所有的粒子都有一个由被优化的函数决定的适应值(fitness value),每个粒子还有一个速度决定他们飞翔的方向和距离。然后粒子们就追随当前的最优粒子在解空间中搜索。
PSO 初始化为一群随机粒子(随机解)。然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个"极值"来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值pBest。另一个极值是整个种群目前找到的最优解,这个极值是全局极值gBest。另外也可以不用整个种群而只是用其中一部分作为粒子的邻居,那么在所有邻居中的极值就是局部极值。
在找到这两个最优值时,粒子根据如下的公式来更新自己的速度和新的位置:
v[] = w * v[] + c1 * rand() * (pbest[] - present[]) + c2 * rand() * (gbest[] - present[]) (a)
present[] = present[] + v[] (b)
v[] 是粒子的速度, w是惯性权重,present[] 是当前粒子的位置. pbest[] and gbest[] 如前定义. rand () 是介于(0, 1)之间的随机数. c1, c2 是学习因子. 通常 c1 = c2 = 2.
蝙蝠算法
蝙蝠算法( BA) 是一种启发式搜索全局最优解的有效方法。和PSO极像。
对于目标函数为minf(x),目标变量为X=(x1,x2,……,xd)T的优化问题,BA算法的实施过程描述如下:
Step1: 种群初始化,即蝙蝠以随机方式在D维空间中扩散分布一组初始解。最大脉冲音量A0,最大脉冲率R0, 搜索脉冲频率范围[fmin,fmax],音量的衰减系数α,搜索频率的增强系数γ,搜索精度ε或最大迭代次数iter_max。
Step2: 随机初始化蝙蝠的位置xi,并根据适应度值得优劣寻找当前的最优解x*。
Step3: 蝙蝠的搜索脉冲频率、速度和位置更新。种群在进化过程中每一下公式进行变化:
fi=fmin+(fmax-fmin)xβ (1)
vi^t=vi^(t-1)+(xi^t-x*)xfi (2)
xi^t=xi^(t-1)+vi^(t) (3)
式中:β属于[0,1]是均匀分部的随机数;fi是蝙蝠i的搜索脉冲频率,fi属于[fmin,fmax];vi^t、vi^(t-1)分别表示蝙蝠i在t和t-1时刻的速度;xi^t、xi^(t-1)分别表示蝙蝠i在t和t-1时刻的位置; x*表示当前所有蝙蝠的最优解。
Step4:生成均匀分布随机数rand,如果rand>r,则对当前最优解进行随机扰动,产生一个新的解,并对新的解进行越界处理。
Step5:生成均匀分布随机数rand,如果rand<Ai且f(xi)<f(x*),则接受步骤4产生的新解,然后按如下公式对和进行更新:
Ai^(t+1)=αAi^(t) (4)
ri^(t+1)=R0[1-exp(-γt)] (5)
Step6:对所有蝙蝠的适应度值进行排序,找出当前的最优解和最优值。
Step7:重复步Step2~Step5直至满足设定的最优解条件或者达到最大迭代次数。
Step8:输出全局最优值和最优解。
蛙跳算法
蛙跳算法(SFLA)是一种全新的启发式群体进化算法。
步骤l 初始化。确定蛙群的数量、种群以及每个种群的青蛙数。
步骤2 随机产生初始蛙群,计算各个蛙的适应值。
步骤3 按适应值大小进行降序排序并记录最好解Px,并且将蛙群分成族群。把F个蛙分配到m个族群Y,Y,Y…,Y中去,每个族群包含n个蛙,从而使得Yk=[X(j),f(j)|X(j)=X(k+m*(j-1), f(j)=f(k+m*(j-1),j=1,…,n,k=1,…,m].这里X(j)表示蛙群中的第j蛙,f(j)表示第j个蛙的目标函数值。
步骤4根据SFLA算法公式,在每个族群中进行元进化。
步骤5将各个族群进行混合。在每个族群都进行过一轮元进化之后,将各个族群中的蛙重新进行排序和族群划分并记录全局最好解Px。
步骤6检验计算停止条件。如果满足了算法收敛条件,则停止算法执行过程,否则转到步骤3。通常而言,如果算法在连续几个全局思想交流以后,最好解没有得到明显改进则停止算法。某些情况下,最大函数评价次数也可以作为算法的停止准则。
人工蜂群算法
初始时刻,蜜蜂以侦察蜂的身份搜索。其搜索可以由系统提供的先验知识决定,也可以完全随机。经过一轮侦查后,若蜜蜂找到食物源,蜜蜂利用它本身的存储能力记录位置信息并开始采蜜。此时,蜜蜂将成为“被雇用者”。蜜蜂在食物源采蜜后回到蜂巢卸下蜂蜜然后将有如下选择:
(1)放弃食物源而成为非雇佣蜂。
(2)跳摇摆舞为所对应的食物源招募更多的蜜蜂,然后回到食物源采蜜。
(3)继续在同一个食物源采蜜而不进行招募。
对于非雇佣蜂有如下选择:
(1)转变成为侦察蜂并搜索蜂巢附近的食物源。其搜索可以由先验知识决定,也可以完全随机。
(2)在观察完摇摆舞后被雇用成为跟随蜂,开始搜索对应食物源邻域并采蜜。

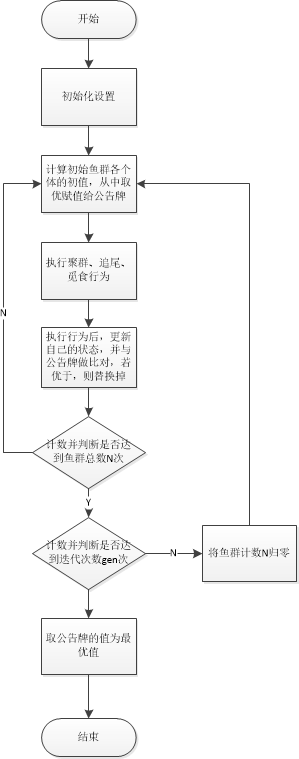
人工鱼群算法
鱼生存数目最多的地方一般就是本水域中营养物质最多的地方,人工鱼群算法就是根据这一特点,通过构造人工鱼来模仿鱼群的觅食、聚群及追尾行为,从而实现寻优。
(1)觅食行为:一般情况下鱼在水中随机地自由游动,当发现食物时,则会向食物逐渐增多的方向快速游去。
(2)聚群行为:鱼在游动过程中为了保证自身的生存和躲避危害会自然地聚集成群,鱼聚群时所遵守的规则有三条:分隔规则:尽量避免与临近伙伴过于拥挤;对准规则:尽量与临近伙伴的平均方向一致;内聚规则:尽量朝临近伙伴的中心移动。
(3)追尾行为:当鱼群中的一条或几条鱼发现食物时,其临近的伙伴会尾随其快速到达食物点。
(4)随机行为:单独的鱼在水中通常都是随机游动的,这是为了更大范围地寻找食物点或身边的伙伴。