概念:
sklearn: 全名Scikit-Learn,是基于python的机器学习模块,网址:http://scikit-learn.org/stable/index.html ,里面对一些常用的机器学习方法进行了封装,在进行机器学习任务时,并不需要每个人都实现所有的算法,只需要简单的调用sklearn里的模块就可以实现大多数机器学习任务。
机器学习任务通常包括分类(Classification)和回归(Regression),常用的分类器包括SVM、KNN、贝叶斯、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN。
常见的降维方法包括TF-IDF、主题模型LDA、主成分分析PCA等等
采用scikit-learn包进行tf-idf分词权重计算关键用到了两个类:CountVectorizer和TfidfTransformer。
关于TF-IDF的计算方法,详细内容参见上一篇博客。
代码:
sklearn的分词方法是基于标点符号和空格进行的,英文分词很容易,当进行中文分词时,需要在分词之间添加空格,举个例子
contents = [
'我 是 中国 人。',
'你 是 美国 人。',
'他 叫 什么 名字?',
'她 是 谁 啊?'
];
from sklearn.feature_extraction.text import CountVectorizer #该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
countVectorizer = CountVectorizer()
textVector = countVectorizer.fit_transform(contents) #.fit_transform()方法将文本转为词频矩阵
调用.todense()方法我们来查看一下这个矩阵:
textVector.todense()
Out[7]:
matrix([[1, 0, 0, 0],
[0, 0, 0, 1],
[0, 1, 1, 0],
[0, 0, 0, 0]], dtype=int64)
调用countVectorizer.vocabulary_属性查看一下每个列的分词结果:
countVectorizer.vocabulary_
Out[6]: {'中国': 0, '什么': 1, '名字': 2, '美国': 3}
我们可以发现长度为1的分词不见了,这样中文分词是不行的,我们需要保留长度为1的分词,在CountVectorizer()函数的初始化构造函数增加两个参数即可。
countVectorizer = CountVectorizer(
min_df=0,
token_pattern=r"\b\w+\b"
) #增加了min_df=0参数,保留最小长度为0的分词,和token_pattern,设置分词的正则表达式。
textVector = countVectorizer.fit_transform(contents)
textVector.todense()
countVectorizer.vocabulary_
结果,每一个分词都被保留了:
textVector.todense() #查看词频矩阵
Out[9]:
matrix([[1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0],
[0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0],
[0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1]], dtype=int64)
countVectorizer.vocabulary_ #查看分词结果
Out[8]:
{'中国': 0,
'人': 1,
'什么': 2,
'他': 3,
'你': 4,
'叫': 5,
'名字': 6,
'啊': 7,
'她': 8,
'我': 9,
'是': 10,
'美国': 11,
'谁': 12}
然后我们开始用sklearn进行得到tf-idf计算,得到tfidf矩阵:
#进行tf-idf计算
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer() #该类会统计每个词语的tf-idf权值
tfidf = transformer.fit_transform(textVector) #.fit_transform()方法得到tf-idf矩阵
但tfidf并不单纯是一个矩阵,我们需要利用pandas把它的矩阵抽取出来:
import pandas;
tFIDFDataFrame = pandas.DataFrame(tfidf.toarray())#.toarray()方法将tf-idf矩阵抽取出来并生成一个数据框,元素a[i][j]表示j词在i类文本中的tf-idf权重
tFIDFDataFrame.columns = countVectorizer.get_feature_names()#获取词袋模型中的所有词语(格式为list) ,作为数据框的columns
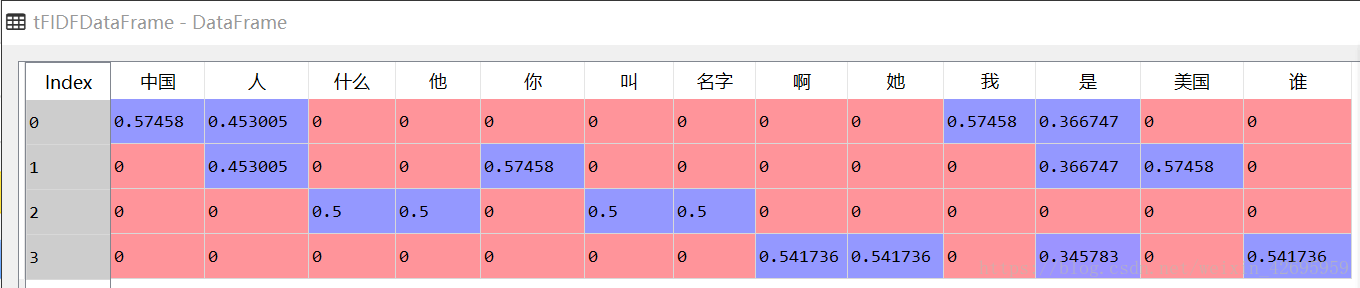
就得到了tf-idf矩阵了,结果如图:
接下来我们要根据tf-idf的值挑选关键字,已知tf-idf值越大,关键字的权重越大,对所有的行进行排序,取关键字:
import numpy
tFIDFSorted = numpy.argsort(tfidf.toarray(), axis=1)[:, -2:] #numpy.argsort()方法,设置axis=1对每行进行排序,然后取前两位
tFIDFDataFrame.columns[TFIDFSorted].values #提取前两位对应的索引的分词
Out[21]:
array([['中国', '我'],
['你', '美国'],
['叫', '名字'],
['她', '谁']], dtype=object)
这个numpy.argsort()方法我还是第一次见,去查了查,做一下补充:
argsort(a, axis=-1, kind=’quicksort’, order=None) Returns the indices
that would sort an array.Perform an indirect sort along the given axis using the algorithm
specified by the kind keyword. It returns an array of indices of the
same shape as a that index data along the given axis in sorted order.
从中可以看出argsort函数返回的是数组值从小到大的索引值
举个例子:
>>> x = np.array([[0, 3], [2, 2]])
>>> x
array([[0, 3],
[2, 2]])
>>> np.argsort(x, axis=0) #按列排序
array([[0, 1],
[1, 0]])
>>> np.argsort(x, axis=1) #按行排序
array([[0, 1],
[0, 1]])
然后就可以根据位置索引提取对应的分词了
到这,采用scikit-learn包进行tf-idf分词计算和关键词提取就完成了,以上是一个完整的示例,接下来开始真正的实战操作,和之前的代码一样:
首先构建语料库:
import os;
import os.path;
import codecs;
#构建语料库
filePaths = [];
fileContents = [];
for root, dirs, files in os.walk(
"D:\\PDM\\2.8\\SogouC.mini\\Sample"
):
for name in files:
filePath = os.path.join(root, name);
filePaths.append(filePath);
f = codecs.open(filePath, 'r', 'utf-8')
fileContent = f.read()
f.close()
fileContents.append(fileContent)
#语料库生成数据框格式
import pandas;
corpos = pandas.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
})
然后进行分词处理,需要注意一下,这里的分词方法和之前有些不一样:
import re
zhPattern = re.compile(u'[\u4e00-\u9fa5]+')
#分词
import jieba
segments = []
filePaths = []
for index, row in corpos.iterrows():
segments = []
filePath = row['filePath']
fileContent = row['fileContent']
segs = jieba.cut(fileContent)
for seg in segs:
if zhPattern.search(seg): #查找中文
segments.append(seg) #过滤掉非中文
filePaths.append(filePath)
row['fileContent'] = " ".join(segments) #按照sklearn的分词方式添加空格
处理停用词:
导入需要的类
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
stopwords = pandas.read_csv( #读取文件,并将停用词传递给stopwords变量
"D:\\PDM\\2.8\\StopwordsCN.txt",
encoding='utf8',
index_col=False,
quoting=3,
sep="\t"
)
#过滤停用词
countVectorizer = CountVectorizer(
stop_words=list(stopwords['stopword'].values), #这里将stopwords作为一个变量传递给stop_words这个参数,就可以直接过滤掉停用词了
min_df=0, token_pattern=r"\b\w+\b" ) #保留长度大于0的分词
将分词结果转换为词频矩阵:
textVector = countVectorizer.fit_transform(
corpos['fileContent']
)
然后计算tf-idf矩阵:
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(textVector)
最后获取关键词,和上面的代码一样:
import numpy;
sort = numpy.argsort(tfidf.toarray(), axis=1)[:, -5:] #对tf-idf矩阵每行的值进行排序,输出对应索引,并取每行前五,得到sort,格式为numpy.ndarray
names = countVectorizer.get_feature_names() #names是一个list,包含所有的分词
keywords = pandas.Index(names)[sort].values #将names包含的所有分词作为index,根据sort里返回的的每一行索引对所有分词进行筛选,每一行筛选都得到一列表示该篇文档关键词前五的数组,总列数为文档总数
tagDF = pandas.DataFrame({
'filePath':corpos.filePath,
'fileContent':corpos.fileContent,
'tag1':keywords[:, 0], #提取第一行,得到包含所有文档的第1个关键词的数组
'tag2':keywords[:, 1], #提取第二行,得到包含所有文档的第2个关键词的数组
'tag3':keywords[:, 2],
'tag4':keywords[:, 3],
'tag5':keywords[:, 4]
})
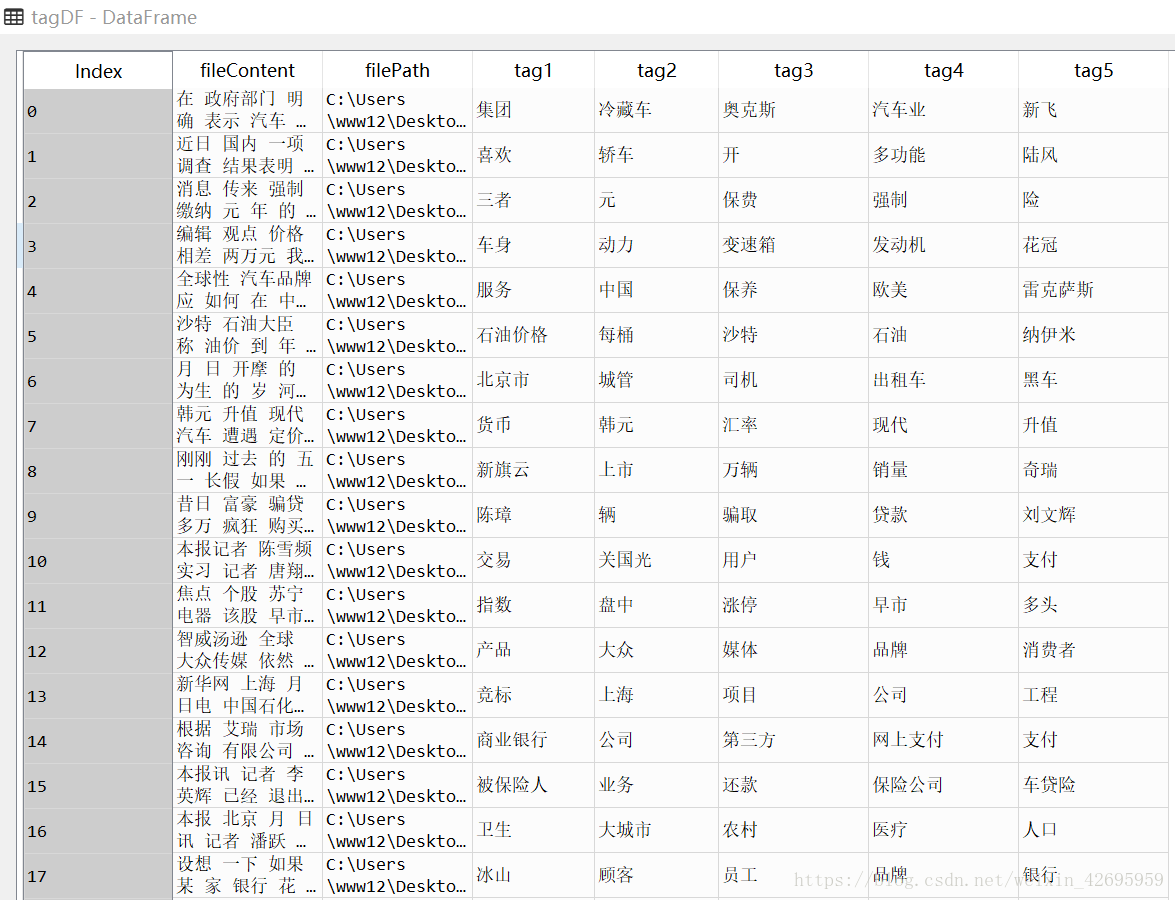
#最后得到所有文档的前五个关键词数组
结果如图所示:
到这里就完成了整个流程,代码很长,里有很多小细节我也有点模糊,还需要反复琢磨,理解,如果哪里有不对的地方,希望大神多多指正,感谢。