1. 朝阳永续库是什么?
朝阳永续库是金融领域里面的一个数据库,它里面有所有A股上市公司的一些数据,包括基本的股票实时数据、基本的财务数据、各大券商对公司的预测数据。我在华泰做的就是股票的一致预期数据,一致预期数据就是每家金融机构了都会对个股进行预测,比如今天营收是多少,今年的净利润是多少,然后朝阳永续将这些数据汇总到数据库中供用户使用。
2.你对这些数据主要做了哪些处理?
首先朝阳永续中的数据有很多种,我需要根据研报的内容猜想他们使用的是哪种数据,再编写相应的python程序从数据库中拿数据,其中都是用sql语句来查找数据,他有一个Python的接口,我们将sql语句进行封装到Python当中,进行查找数据。
- 首先评估一下数据得缺失率(利用前期发出的的报告去补充后面的报告数值也是一种补充数据的方法)
- 计算数据的增长率,占比等信息
- 对于数据,有很多重复性属于时间序列的预测数据采用几种不同的方法去测验数据对于收益率的好处,如采用最新的数据,采用等权加权所有日期的数据,采用最新权重更重来加权得到新的数据。
- 标准化和去极值
- 去除行业和市值的影响
查找完的数据还需要做哪些处理才能变为真正的特征来使用?
写一个sql语句或者sql语句常见用法
SELECT * FROM collection1 when feature == "
(还要多写几个,查找,合并等等)
MongoDB和MySQL的区别
你在数据处理中遇到了哪些问题,都是怎样解决的?
-
缺失值问题
- 采用的最多的是用前期的报告数据进行填充
- 一般很少用中位数进行填充,因为基本的财务数据没家公司相差很大。
- 采用的是增长率填充法:相近的月份的财务数据增长比例应该是一样,采用相同的增长率来进行填充。比如某家公司2月份的数据缺失,我们知道前两个月的数据(1月和12月份),我们通过1月和12月能够算出一个增长率来,之后利用这个增长率和1月份的数据就能够算出2月份的数据来。
- 大量的数据全是零(分析师报告中上调的数量)
- 补0法:
-
大量的数据都为0
-
查找数据太慢,大量的数据需要下载
为什么当初想去金融领域实习,现在想找互联网相关的工作?
- 为了拿到数据,金融领域本来就是AI的一个比较大的场景,金融业存在大量的数据,但是这些数据并不是开源的,一些做的比较好的数据上的服务都是很贵的,像wind和朝阳永续,去券商和金融公司我能够拿到这些数据进行研究。
- 我本身对投资很感兴趣,因为我觉得投资是一个人回避不了的话题,我同时又对编程和人工智能很感兴趣,而量化是一个很好的结合点,能够让我既能够接触到投资方面的东西,而且能够做自己喜欢做的Al方向,做自己感兴趣的东西才是最大的乐趣。
- 之所以现在回到互联网,是因为我在券商实习的时候发现他们做的东西很虚,他们的主要工作是做发研究报告,有些东西我们明明没有做出来,但是却能够写得天花乱坠以为很厉害,这和我想真正做点东西的愿望不符。
- 慢慢接触了量化之后我发现虽然做的是金融方面的东西,但是本质上是计算机算法上面的工作,我们就是要把每天的各种交易思想能够用数据分析来进行解决,而去互联网公司做无疑是最好的选择。
分层回测、回归法、和IC值
- 分层回测: 这个是单个特征的分析方法,首先标准化和去极值,按照特征值的大小进行排序,按照排序的结果分为几层(一般为5-10层),去计算每层相对于收益率的大小的IC值,看是否存在正相关。
- 去极值的方法:
- 中位数去极值:首先取出特征中的中位数Xm,然后再取出|Xi - Xm|的中位数Dmad,将Xm减去n*Dmad得到处理后的值,n为倍数。去完极值之后再进行标准化。
- 因子载荷排序值标准化。
- IC值:IC值指的是特征与收益率的相关系数,使用的都是spearman相关系数,
- spearman相关系数和pearson相关系数的区别:
- person相关系数的要求需要连续,线性和正太分布,spearman不需要满足这些条件。
- 另外person需要在同一限度范围之内才能比较相关性,比如一个人的数学和语文成绩的相关性可以用person,因为都是100分,但是一个人的成绩排名和数学成绩就不能比较。
FDDC金融预测大赛
- 特征工程
- 特征工程主要处理步骤
- 将三张报表合并, 去除掉缺失率大于50%的特征
- 只选择最后发布的报表,如果最新财报有数据缺失则在前面的财报中填充
- 去除掉标签页缺失的的数据
- one-hot编码上市公司代码后缀
- 将偏斜度(skew)大于0.6的数值列做一个log转换,使之尽量符合正态分布,因为很多模型的假设数据是服从正态分布的
- Box-Cox变换后,残差可以更好的满足正态性、独立性等假设前提,降低了伪回归的概率(关于box_cox介绍可以看这里)
- 标准化和归一化处理
- 特征的增加
- 本身以有特征的增长率
- 特征工程主要处理步骤
mini-batch
为什么需要 Mini-batch 梯度下降,及 TensorFlow 应用举例
Batch-Normalization
- 什么是Batch-Normalization?
对batch的数据做四步,1,获得mini-batch。2求均值和方差。 3,做标准化。4.线性变换。 - 为什么要用Batch-Normalization?
- 训练神经网络的时候我们需要把训练数据一批一批的导入,由mini-batch来控制,因为数据比较的少量,所以没批的数据的分布都是不一样的,保证每次rule都是相同分布的数据。(具体参考链接)
- Batch-Normalization怎么用?
用在卷积层之后,激活函数层之前。
如何选择优化器 optimizer
如何选择优化器 optimizer
机器学习:各种优化器Optimizer的总结与比较 四颗星
LRN层
- 主要的作用是对数据起到局部抑制的作用,对于金融数据来说,某只股票在某一天的暴涨暴跌并不是常态,我们选择的信息应该是在大多数时间中的存在的特征,不像图像,需要找出边缘特征,所以抑制局部响应这种方法可能在金融数据中比较有用。
- 这种方法是受到神经科学的启发,激活的神经元会抑制其邻近神经元的活动——侧抑制现象至于为什么使用这种正则手段,以及它为什么有效,查阅了很多文献似乎也没有详细的解释,可能是由于后来提出的batch normalization手段太过火热,渐渐的就把local response normalization掩盖了吧。
Q-learning算法和项目内容
项目参考文章——Deep Q-Learning with Keras and Gym
-
项目主要内容
- 这个项目是借鉴了一个github上面的一个强化学习玩游戏的例子,他原来的目标是让机器能够在游戏中不断的学习最终能够取得一个满意的成绩。我们的最终目标是希望机器能够在不断的训练中学习到股票的内在规律,能够取得很高的胜率,最后的胜率不是特别好,也就60%左右,但是对于股票来说,能够达到50%的概率那在多次买卖当中我们就一定能够获胜的
- 首先,每次选取10天的股票数据作为一个state,对于每10天的一个数据,刚开始是随机的选择一个action,不过随着迭代的次数增多,会慢慢使用全连接神经网络来尽心预测,得到的action来进行股票买卖,将买卖得到的盈利作为reward,盈利越多reward也会越大,当没有训练完成的时候取reward加上下一个state时通过神经网络预测的盈利结果的和作为目标;当全部训练完成的时候取reward作为此时的目标。
xgboost
关于GBDT的介绍,可以看这里
wepon大神关于GBDT的ppt
- 树模型的优缺点



正则化
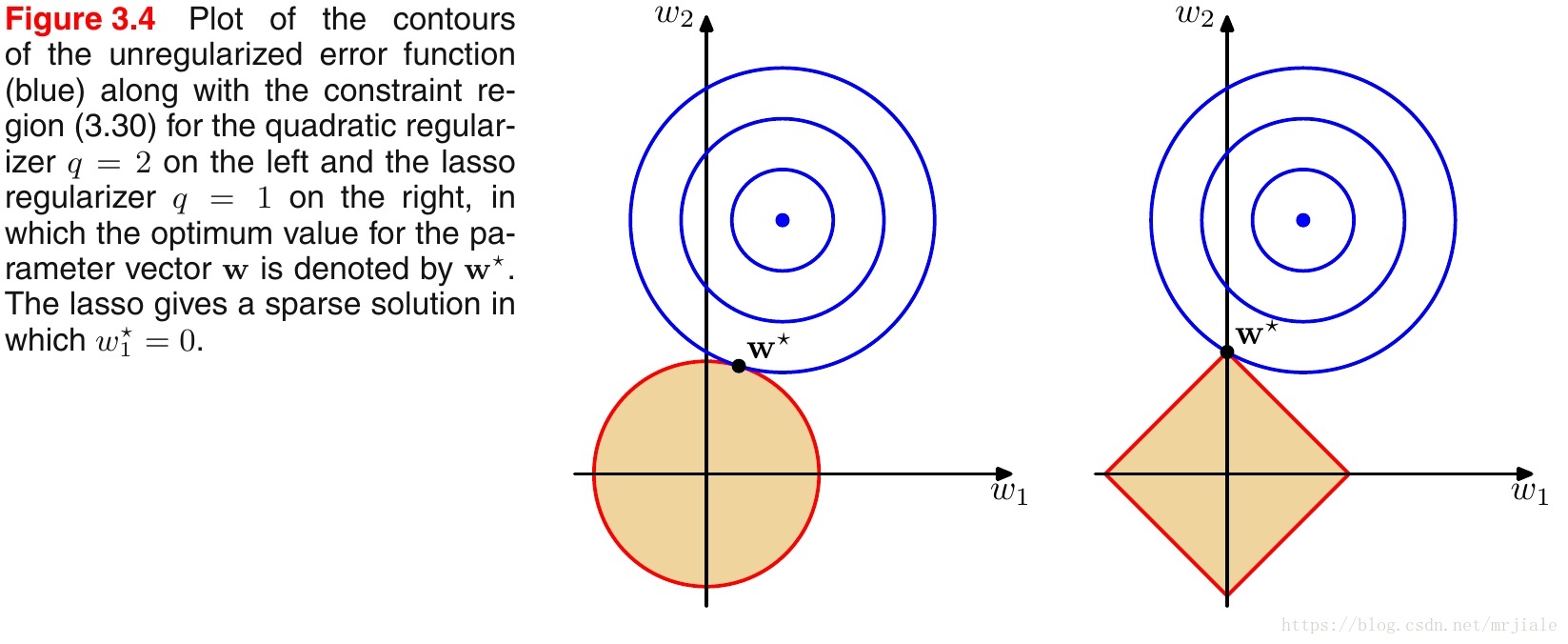
如上图所示,蓝色的圆圈表示问题可能的解范围,橘色的表示正则项可能的解范围。而整个目标函数(原问题+正则项)有解当且仅当两个解范围相切。从上图可以很容易地看出,由于L2范数解范围是圆,所以相切的点有很大可能不在坐标轴上,而由于L1范数是菱形(顶点是凸出来的),其相切的点更可能在坐标轴上,而坐标轴上的点有一个特点,其只有一个坐标分量不为零,其他坐标分量为零,即是稀疏的。所以有如下结论,L1范数可以导致稀疏解,L2范数导致稠密解。
从贝叶斯先验的角度看,当训练一个模型时,仅依靠当前的训练数据集是不够的,为了实现更好的泛化能力,往往需要加入先验项,而加入正则项相当于加入了一种先验。
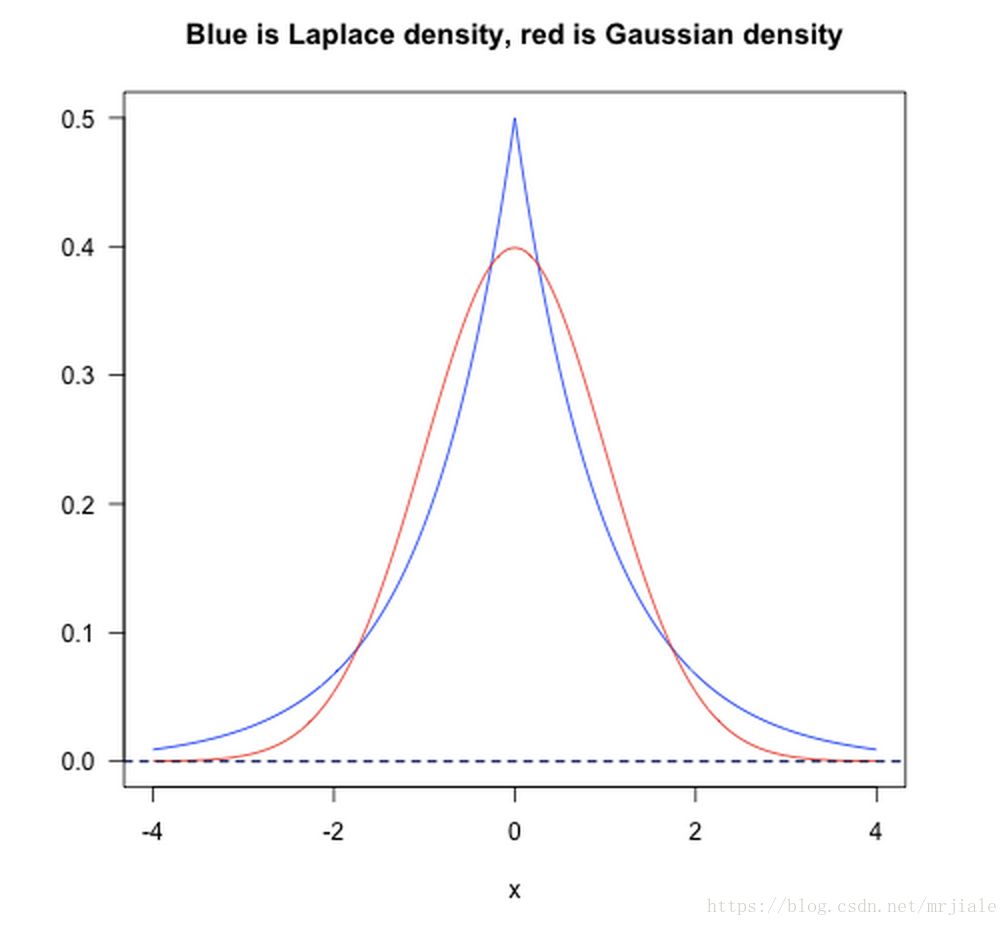
L1范数相当于加入了一个Laplacean先验,可以保证模型的稀疏性,也就是某些参数等于0;
L2范数相当于加入了一个Gaussian先验,可以保证模型的稳定性,也就是参数的值不会太大或太小;
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归。
如下图:
利用cnn和全连接来预测股票市场行情
- cnn需要注意的点:卷积层,卷积核的运算,权重和参数的个数
- 关于inception可以看这个Inception简介