声明: 以下内容可能会引起某些读者不适, 请小心阅读. 有些内容并没有详细介绍, 可能简单理解也是错误的, 但是这都是为了尽量简单。
前言: 我自己认为, 对想要学习编程的人而言, C语言是一门必须要学习的语言, 但是其实就现在这个时代的话, 你没有学习C语言的绝对必要。使用别的高级语言(比如python)站在巨人的肩膀上很好, 也很爽。
推荐书目:
- 《C语言程序设计》
- 《C标准库》
- 《C primer plus》
- 《C缺陷和陷阱》
- 《C专家编程》
- 《linux程序设计》
链表是一种很有意思的数据结构,他是通过动态的申请内存和释放内存来得到的,通过链表的学习,我觉得可以强化我们对指针的理解,如果指针学的并不透彻的话。
单链表
单链表的每个节点里面有一个数据段和指针段。对比的看,int类型的变量只能存储int,而链表节点是结构体(一般情况下是), 是一种复合结构。 看下图: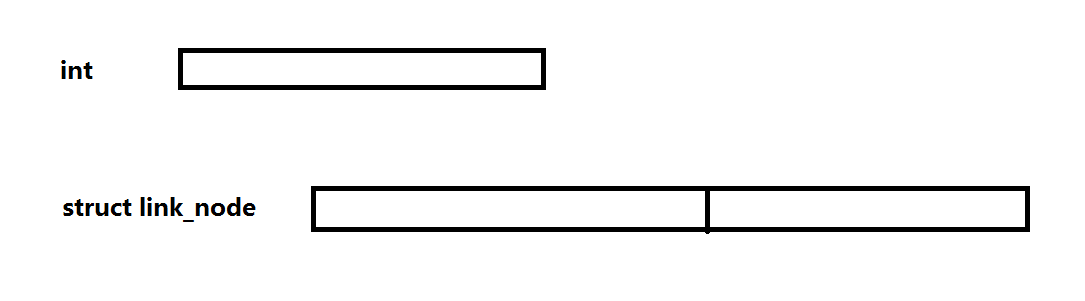
结构定义
链表节点的结构定义:
|
1
2
3
4
5
|
struct link_node
{
void *data;
struct link_node *next;
}
|
在这个链表节点的结构定义中,有一个空指针, 也有一个指向链表节点类型结构体的指针。
链表的结构定义
|
1
2
3
4
5
6
|
struct link
{
struct link_node *head;
int len;
struct link_node *tail;
};
|
在这个链表的定义中有头尾指针, 还有链表长度。
链表的初始化
|
1
2
3
4
5
|
void link_init(struct link *l)
{
l->head = l->tail = NULL;
l->len = 0;
}
|
我们在这里接受链表结构体指针。通过->访问符, 访问到指针所指向的结构体对象的各个段。包括头指针段,尾指针段,长度段,对它们的值进行了初始化。
链表的一些方法
增加链表节点, 这里是在链表后面增加节点的方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
void link_addnode(struct link *l, struct link_node *node)
{
if (l->head == NULL)
{
l->head = node;
l->tail = node;
l->len = 1;
}
else
{
node->next = l -> tail->next;
l->tail->next = node;
l->tail = node;
}
}
|
删除链表中的某个节点:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
void link_rmnode(struct link *l, struct link_node *node,
void (*link_node_free)(struct link_node *node))
{
assert(l != NULL && node != NULL);
if (node == l->head) // 如果要删除第一个节点
{
l->head = l->head->next; //将头结点设置为未删除时的第二个节点
link_node_free(node); // 释放第一个节点占用的内存
}
else // 否则的话
{
struct link_node *tmp = l->head; // 设置一个临时指针指向链表头结点
while (tmp->next != NULL && tmp->next != node) { tmp = tmp->next; } // 当临时指针的下一个节点不是node节点的话, 就向后移动指针。
if (tmp == l->tail) { return; } // 如果tmp到了结尾,说明node并不在l中
tmp->next = node->next; // 从链表中删除node
link_node_free(node); // 释放node节点占用
}
}
|
我们在这个函数的参数中加入了一个函数指针, 这个指针负责节点的内存释放, 因为我们每个结构体的内部还有一个data指针, 所以我们不能简单的把结构体指针直接free掉,而是应该使用自己写的对应的link_node_free函数。
查找链表中的某个节点:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
struct link_node* link_findnode(struct link *l, void *value, int value_size,
int(*find)(struct link_node *l1, void *value, int value_size))
{
struct link_node* p = l->head;
int found = 0;
while (p != NULL)
{
if (find(p, value, value_size))
{
found = 1;
break;
}
else
{
p = p->next;
}
}
return (found) ? p : NULL;
}
|
这个函数的参数需要一个被查找的链表,需要一个查找凭据的指针,需要知道这个凭据的长度,还需要自己设置一个查找函数并传入。
第四行,我们设置了一个链表节点指针p使他指向链表头结点。
第五行,我们设置了一个标志值,表示有没有查找到节点。
然后我们用一个循环来在每个节点中查找,如果找到就设置标志值并且退出循环。
最后我们返回查找结果。
双向链表
双向链表比单项链表多了一个向前指示的一个指针, 如下图: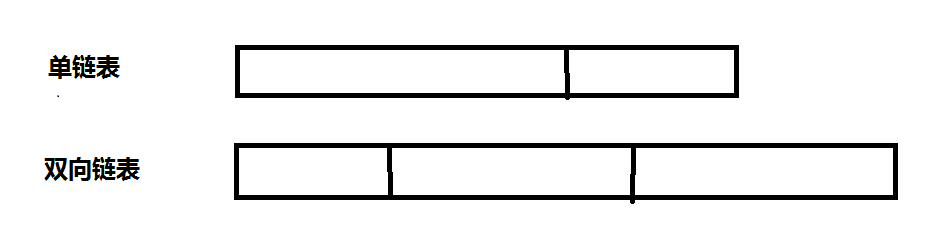
单链表只能向一个方向进行移动,而双向链表可以向两个方向移动。
双向链表的结构定义
这里是双向链表节点的定义:
|
1
2
3
4
5
|
struct link_node
{
void *data;
struct link_node *next, *prev;
}
|
这里是双向链表的结构定义:
|
1
2
3
4
5
|
struct link
{
struct link_node* head, *tail;
int len;
};
|
双向链表的一些方法
双向链表的初始化:
|
1
2
3
4
5
|
void link_init(struct link *l)
{
l->head = l->tail = NULL;
l->len = 0;
}
|
链表小结
链表是一种特别的链式数据结构,他通过C语言提供的指针功能来实现数据之间的链接。因为指针可以达到间接访问的目的,所以当使用malloc得到一块内存,并且进行合理类型转换之后,我们就可以用指针来对这块内存进行访问。当然,我们要承担对相应内存的释放工作。程序员至少要知道自己在做什么,这是C语言要求的。
注意:
指针指向一块内存(指针变量的值存储那块内存的首地址),然后你就可以通过\r解引用符号对那块内存进行操作(像这样: (pointer)->member_var),你也可以通过这样的方法 pointer->member_var 来访问pointer所指向的内存空间里面 member_var 所对应的内存区域。指针变量p存储了a的地址,那么*p就可以被当作是a使用,同理,如果p存储的是结构体变量的地址,那么*p就可以当做是哪个结构体变量来使用。
而malloc这个函数可以返回一片你指定大小的内存的首地址,而如果没有供你使用的大小的内存存在的时候
如果你是非常新的小白,你可能还不懂这到底是怎么回事。但这并不是我所关心的。