总结下Dnn、Cnn、Rnn、Lstm、Gru、Gan、Textcnn等常见深度学习网络的原理
DNN:
背景
DNN(Deep Neural Netword,深度学习网络),也叫多层感知机(Muiti-layer perception),有时也叫做多层神经网络,其实都是指的一个东西。它能模拟任意的函数关系(详情请见Universal approximation theorem定理)。所以在深度学习应用中,我们使用它去拟合任何想要的函数,通过bp算法,原则上我们就能得到任意的想要的函数关系
基本结构
输入层、隐藏层、输出层。如图所示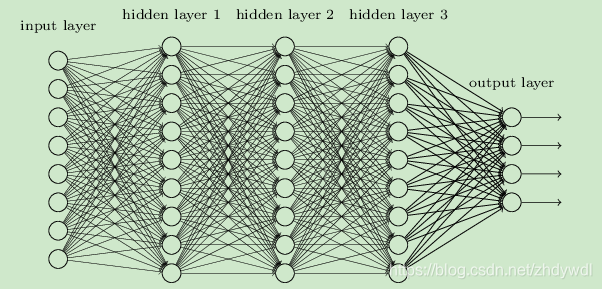
隐藏层可以用很多层。每相邻的两层之间是全连接的。然后输入经过一次FP前向传播到output layer计算损失获得BP的能量再进行一次BP将能量传播到每一个网络层,从而实现权值更新。
CNN(Convolution Neural Network):卷积神经网络
现在的CNN不仅应用于图像,也越来越多的应用于NLP领域。
基本原理:其实跟DNN原理有很多相似的地方,以图像为例。假设我们有一张32 * 32大小的图片,我们会用一个卷积窗口(比如2 * 2)去扫描这张图片,卷积窗口和它每一次所扫描到图像区域实际上就是一次全连接的过程,卷积矩阵就是我们所要更新的参数。这里有一张卷积过程的示意图,我觉得特别形象。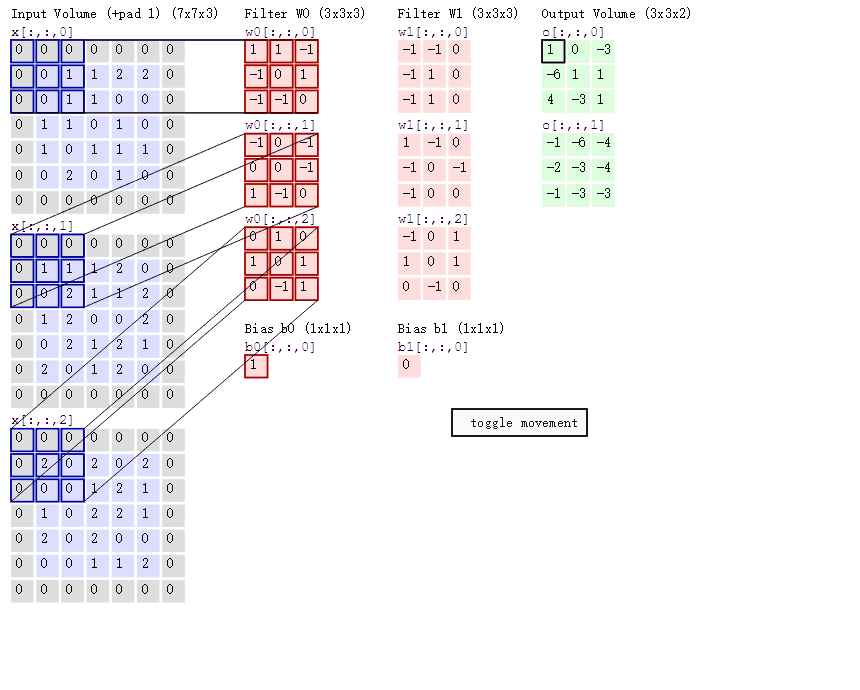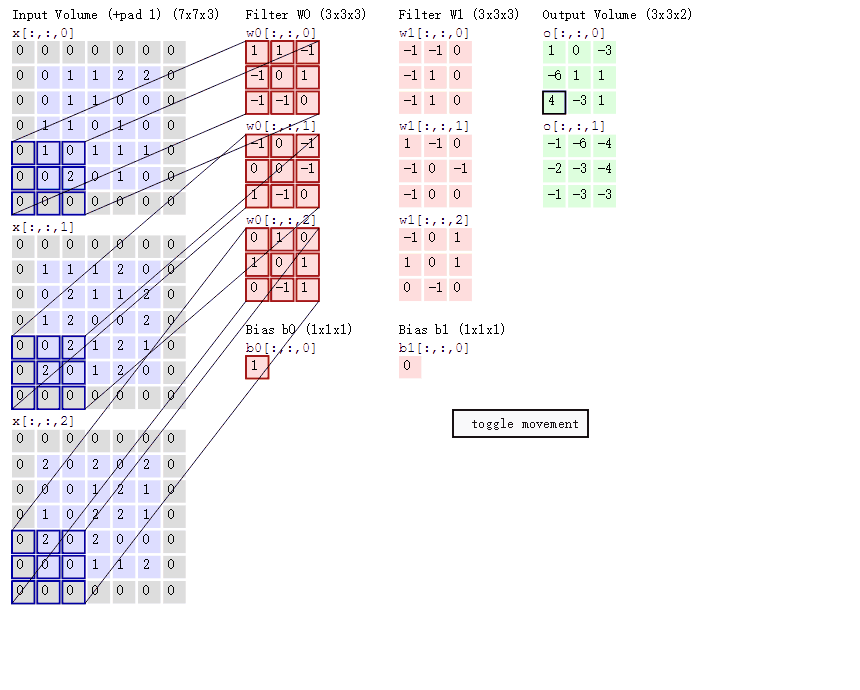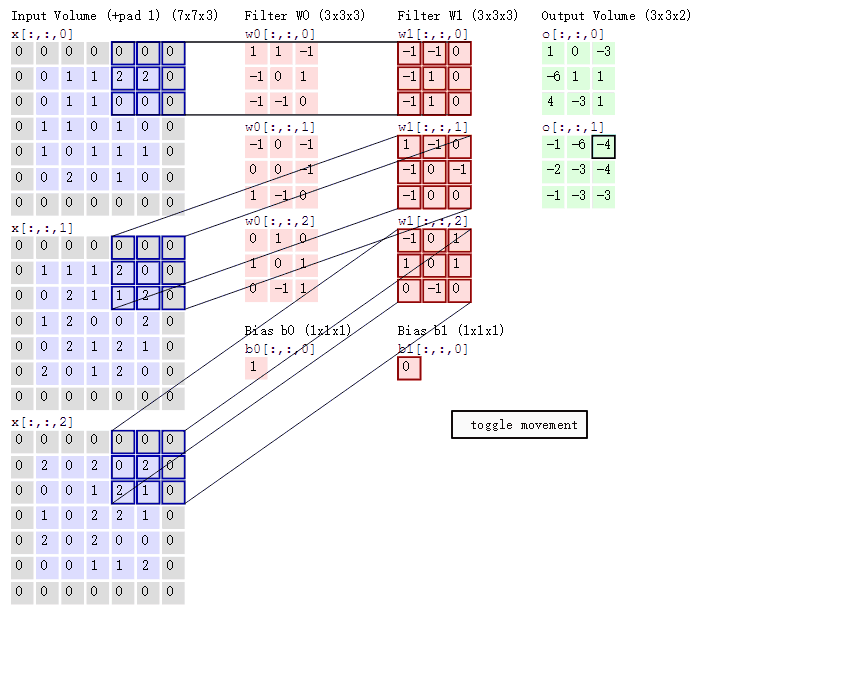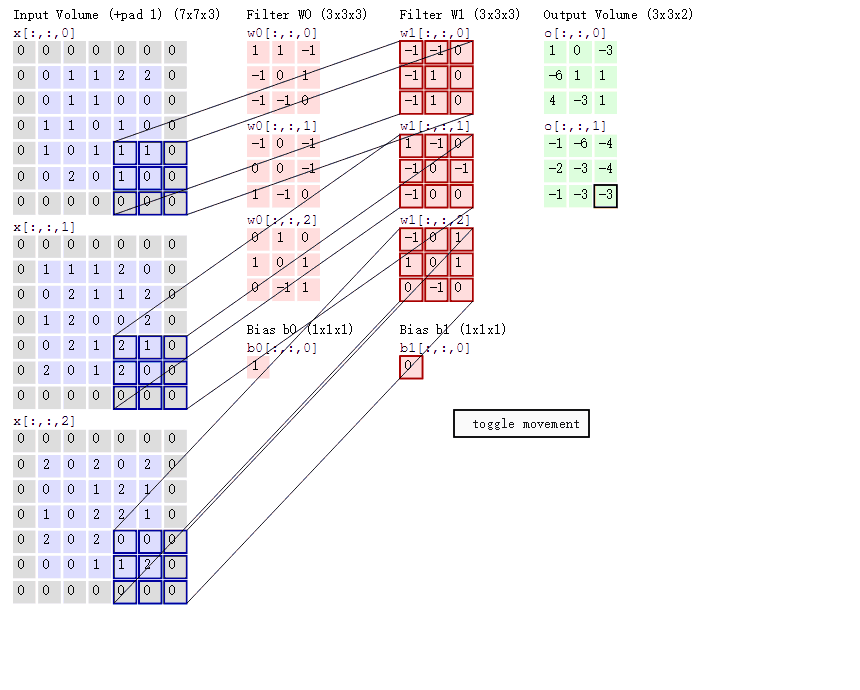
在这里需要注意:一般来说,进行卷积操作(现在高端的算法比如通道分离,群组卷积这里暂且不谈,仅仅限于一般的卷积操作):
1.输入图像通道数 = 卷积核的通道数(就是输入图片为多少通道的,卷积核就是多少通道的)
2.输出通道数 = 卷积核个数(就是用多少个卷积核去卷图片,最终得到的特征图就是多少通道的)
3.卷积核输出矩阵=(输入图像的尺寸-卷积核大小+2padding)/strides +1.比如输入图像是32 * 32, 卷积核大小为2 * 2, padding=None, strides=1,那么最终的输出矩阵的大小为(32-2+2 * 0)/1 + 1 = 31 * 31
4.在tensorflow或者pytorch中,
如果设置padding=‘SAME’,表示不够的部分后面填充0。那么卷积后的矩阵大小为:
输出=ceil(input/strides)。举个例子,如果设置padding=‘SAME’, 输入图像为32 * 32,卷积核大小为2 * 2, strides=2, 那么最终输出矩阵为ceil(32/2)=1616的矩阵
如果设置padding=‘VALID’,表示舍弃不够的部分。公式为:
输出=ceil((input-filter+1)/strides)。举个例子,如果设置padding=‘VALID’,输入图像为32 * 32,卷积核大小为2 * 2, strides=2, 那么最终输出为ceil((32-2+1)/2)=16*16
5.卷积网络相对全连接最大的优势是共享参数,能极大的减少参数量
RNN(Recurrent Neural Network):循环神经网络
RNN是一类处理序列数据(简而言之:序列数据就是后面的数据跟前面的数据有关系)的神经网络.RNN和CNN最大的不同是RNN不仅在层与层之间用权值相连,在相邻的神经元之间也会有权值相连。基本原理如图: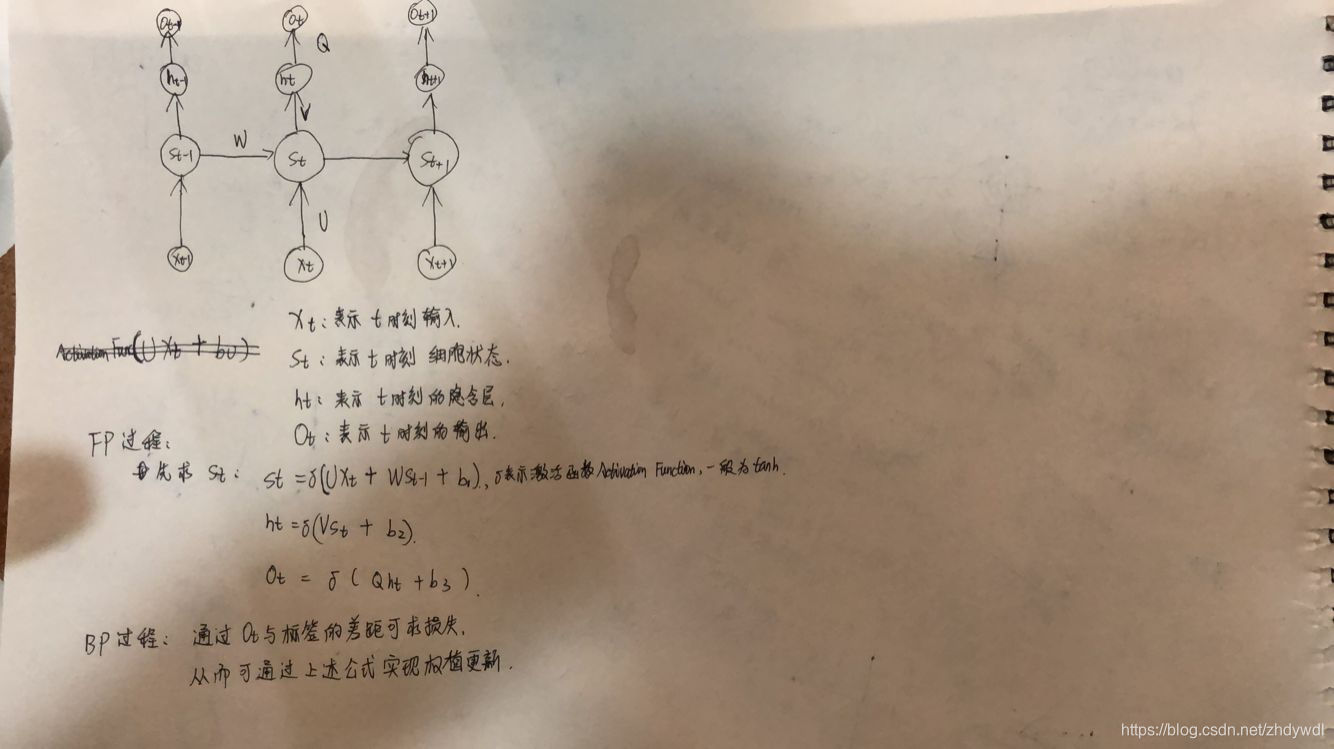 需要注意的是:W、U、V、Q等矩阵参数也都是共享的
需要注意的是:W、U、V、Q等矩阵参数也都是共享的
LSTM(Long Short-Term Memory):长短期记忆网络
LSTM是RNN的改进,RNN因为无法处理长时序的问题限制了它的应用(因为会存在严重的梯度消失情况),所以就有人提出了LSTM单元。LSTM区别于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为cell。基本结构单元如下: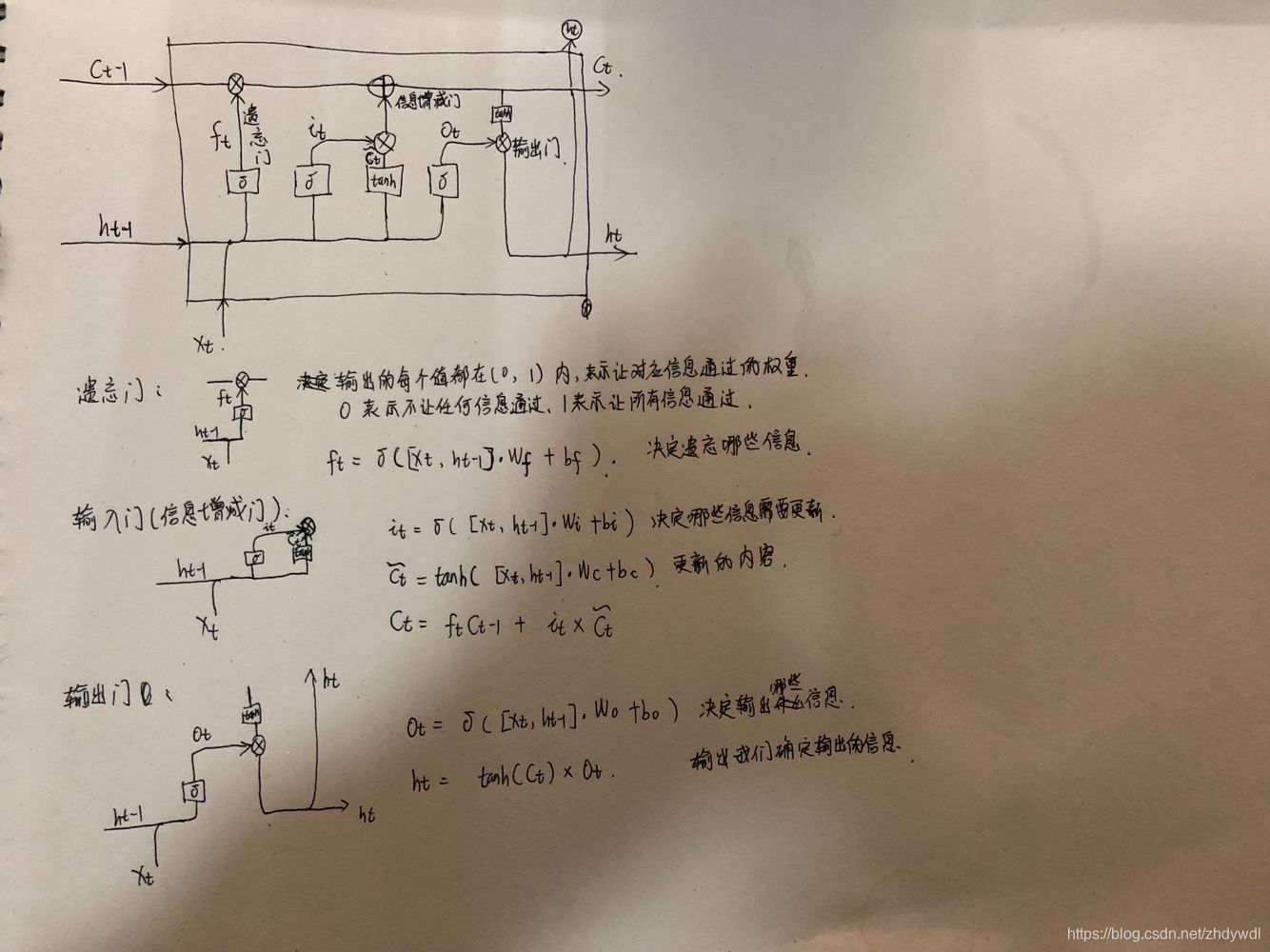 GRU(Gated Recurrent Unit ):门控循环单元
GRU(Gated Recurrent Unit ):门控循环单元
在 GRU 中,如下图所示,只有两个门:重置门(reset gate)和更新门(update gate)。同时在这个结构中,把细胞状态和隐藏状态进行了合并。最后模型比标准的 LSTM 结构要简单。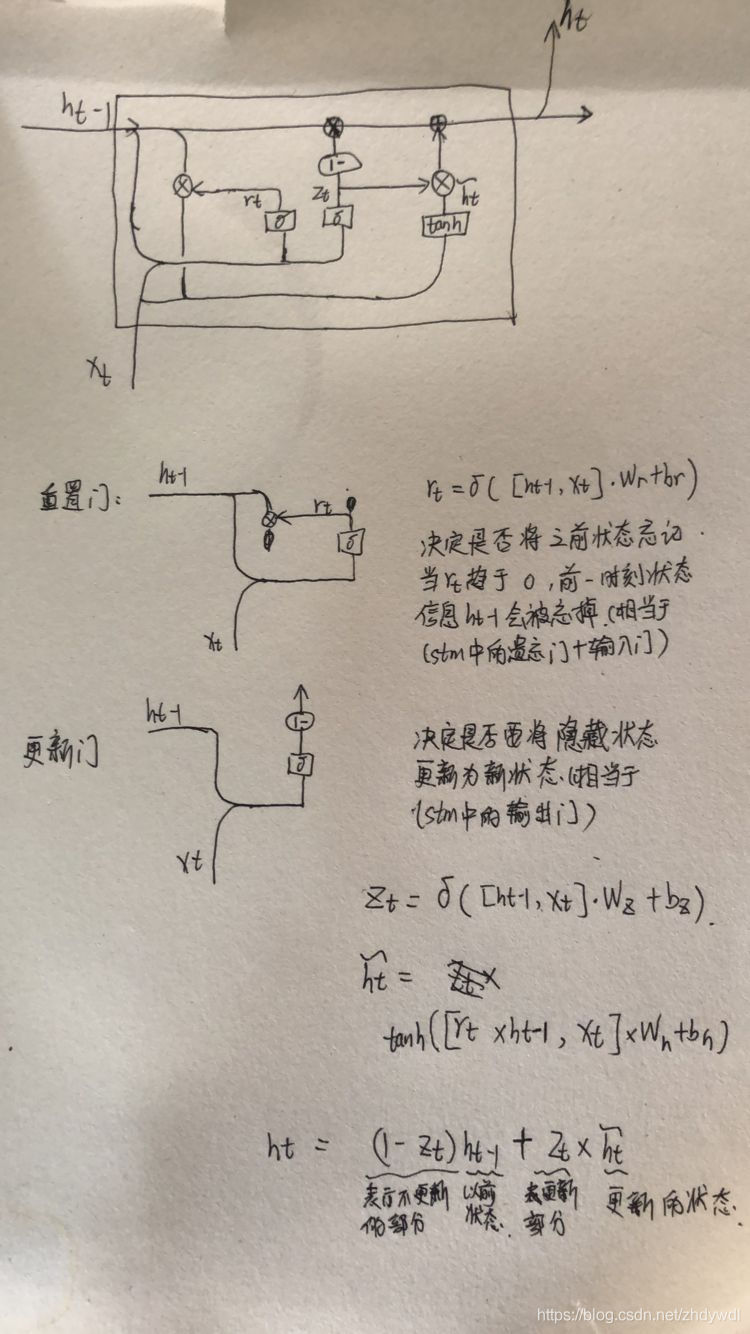
GAN(Generative Adversarial Networks):生成对抗网络
原理
GAN的思想是一种二人零和博弈思想。它有两个模型,一个是生成模型,一个是判别模型。生成模型的作用是生成数据,判别模型的作用是判别数据的真伪。那么这个网络是如何对抗的呢。首先。生成模型生成数据,然后将生成式模型生成的数据和真实的数据(当然我们会给真实数据标签1,给生成的数据标签0)一起放入判别式模型中。对于判别模型,我希望它能将真实数据和生成的数据判断出来,也就是说,我希望对于真实的数据,我要让他生成1的概率尽量大,对于生成的数据,我想让它生成0的概率尽量大。这样就能训练判别模型。而对于生成模型,我希望它生成的数据,能让判别式模型判断它为真。举个例子,假如我是一个卖莆田系AJ的商家(生成模型),我生产大量的仿品(生成数据),但是为了进入市场,我必须得将这些仿品经过有关部门(判别模型)的检测。对于部门来说,每次送来检测的鞋子(判别模型的输入)可能有真有假,它的任务就是尽量把每一双鞋的真假鉴别出来,而对于我来说,我的任务就是提高我的技术水平,让我生产的鞋子被部门检测为正品,这样我才能进入市场。在有关部门刚刚创立的时候,没什么经验,总是把仿品判断成正品,或者把正品判断为仿品。然后被投诉了很多次(和标签求损失),过了很久,部门有了足够的经验,就再也没被投诉过(判别模型收敛趋于稳定)。但是对我来说,部门这么牛x,那我生产出的仿品一眼就被看出来,不行,虽然我生产仿品,但我也是有梦想的。所以我自己严格要求自己,要把自己的产品当成正品去生产,如果当成仿品生产,没有动力,就没有改善的空间了。自己人都瞒不过,还能瞒得过部门吗?(生成模型的标签设置为1)。虽然我严格要求自己,但终究得经过部门的检测,检测过后,我知道了下一步改善的方向是哪里,这样就能促使我在实践中学习改善的方向(根据判别模型求损失,利用损失更新生成模型的参数)。这样过了很久,世界上除了我,没人知道我生产仿品。

训练过程:
因为这两个模型是完全独立的两个模型,没什么联系,所以训练采用的原则为单独交替迭代训练。一批数据,先训练判别模型,再训练生成模型。
判别模型的训练:
- 假设现在有了生成网络(可能不是最好的),那么给一堆随机数组,就会得到一堆假的样本集(因为不是最终的生成模型,现在生成网络可能处于劣势,导致生成的样本不太好,很容易就被判别网络判别为假)
- 现在有了这个假样本集(真样本集一直都有),我们再人为地定义真假样本集的标签,很明显,这里我们默认真样本集的类标签为1,而假样本集的类标签为0,希望真样本集的输出尽可能为1,假样本集为0。
- 现在有了真样本集以及它们的label(都是1)、假样本集以及它们的label(都是0)。这样一来,单就判别网络来说,问题变成了有监督的二分类问题了,直接送进神经网络中训练就好。
- 判别网络训练完了。
生成模型的训练:
- 对于生成网络,我们的目的是生成尽可能逼真的样本,而逼真与否只能通过判别网络才知道,所以在训练生成网络时,需要联合判别网络才能达到训练的目的,所以生成网络的训练其实是对生成-判别网络串接的训练。因为如果只使用生成网络,那么无法得到误差,也就没有损失来进行训练
- 当通过原始的噪声数组Z生成了假样本后,把这些假样本的标签都设置为1,即认为这些假样本在生成网络训练的时候是真样本。因为此时是通过判别器来生成误差的,而误差回传的目的是使得生成器生成的假样本逐渐逼近为真样本(当假样本不真实,标签却为1时,判别器给出的误差会很大,这就迫使生成器进行很大的调整;反之,当假样本足够真实,标签为1时,判别器给出的误差就会减小,这就完成了假样本向真样本逐渐逼近的过程),起到迷惑判别器的目的
- 现在对于生成网络的训练,有了样本集(只有假样本集,没有真样本集),有了对应的label(全为1),有了误差,就可以开始训练了
- 在训练这个串接网络时,一个很重要的操作是固定判别网络的参数,不让判别网络参数更新,只是让判别网络将误差传到生成网络,更新生成网络的参数
TextCNN:用卷积处理文本分类。基本结构图如下: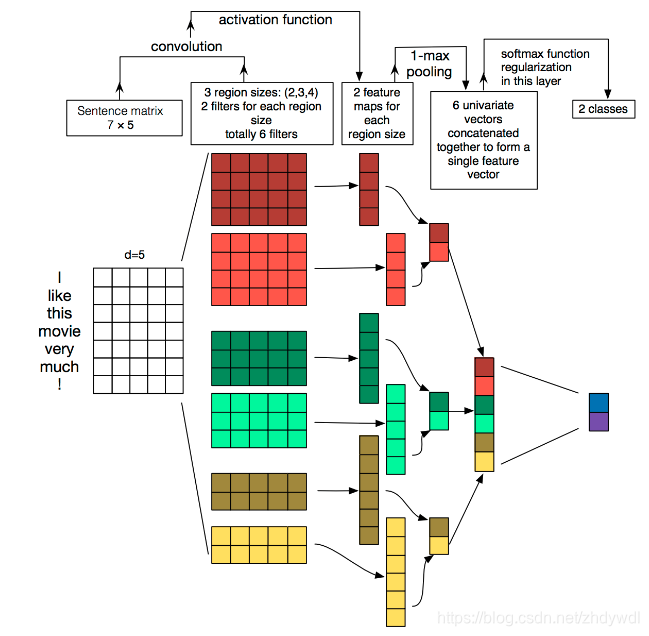
输入:每个文本的词向量。如果数据量比较多,可以用随机初始化的词向量,如果数据量少,可以用训练好的词向量
卷积+激活:用三种不同尺寸的卷积(2 * 5, 3 * 5, 4 * 5),其中每一种用两个卷积核去卷,这样每一个尺寸得到两个特征图,一共6个特征图(因为是一维卷积,需要设置不同的尺寸获取不同的视野)
池化:将每一个特征图进行1-max-pooling,每个特征图取个最大值。然后将6个特征图的最大值进行拼接形成最终的特征向量
分类:最后接一层全连接的 softmax 层,输出每个类别的概率