原文网址:https://blog.csdn.net/yonggeit/article/details/72857630
用户访问网站流程框架
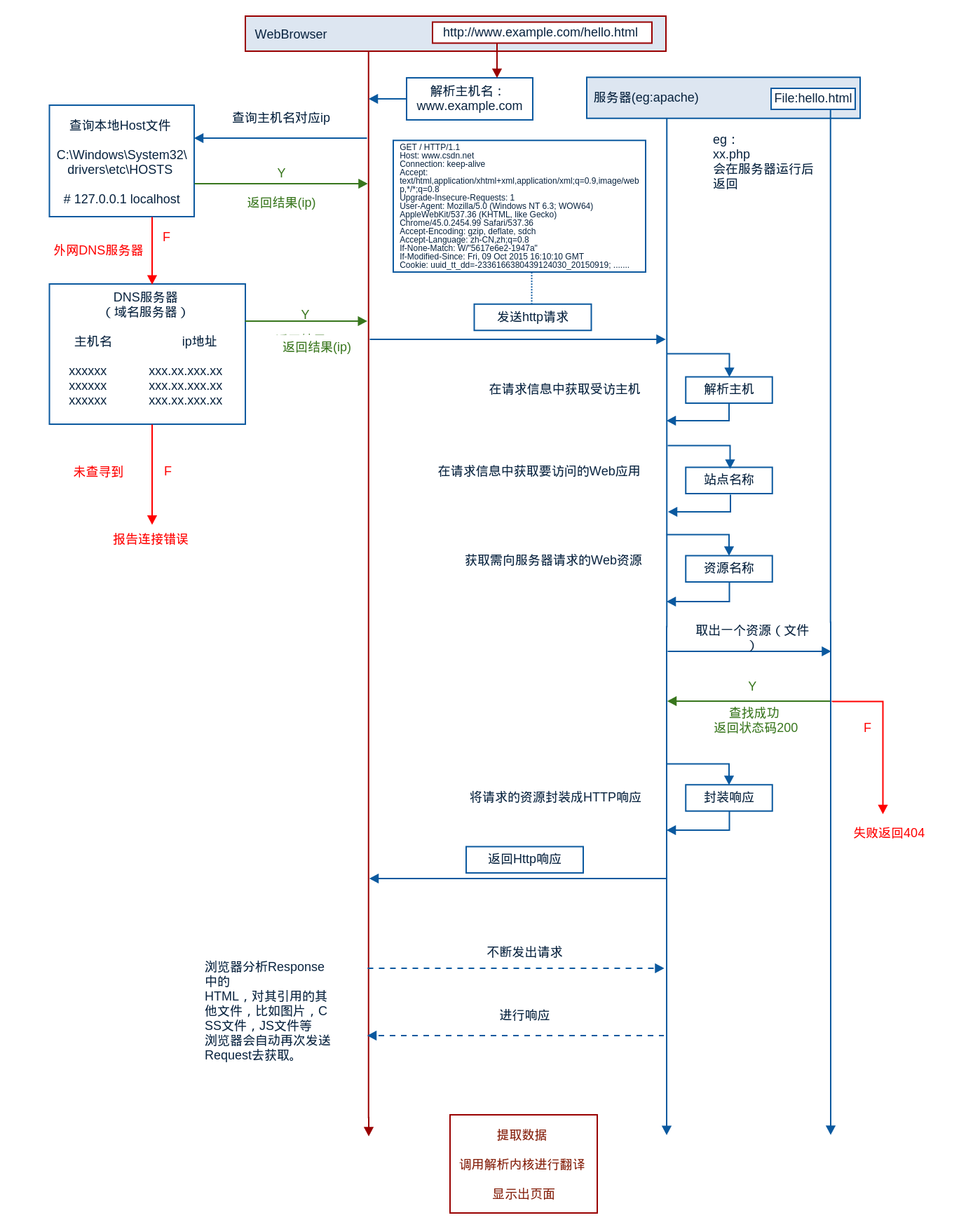
第一步:客户端用户从浏览器输入www.baidu.com网站网址后回车,系统会查询本地hosts文件及DNS缓存信息,查找是否存在网址对应的IP解析记录。如果有就直接获取到IP地址,然后访问网站,一般第一次请求时,DNS缓存是没有解析记录的;
第二步:如果客户端没有DNS缓存或hosts没有对应www.baidu.com网站网址的域名解析记录,那么,系统会把浏览器的解析请求,交给客户端本地设置的DNS服务器地址解析(此DNS为LDNS,即Local DNS),如果LDNS服务器的本地缓存有对应的解析记录,就会直接返回IP地址;如果没有,LDNS会负责继续请求其它的DNS服务器;
第三步:LDNS会从DNS系统的“.”根开始请求www.baidu.com域名的解析,经过一系列的查找各个层次DNS服务器,最终会查找到www.baidu.com域名对应的授权DNS服务器,而这个授权DNS服务器,正是该企业购买域名时用于管理域名解析的服务器。这个服务器有www.baidu.com对应的IP解析记录,如果此时都没有,就表示企业的运维人员么有给www.baidu.com域名做解析;
第四步:baidu.com域名对应的授权DNS服务器会把www.baidu.com对应的最终IP解析记录发给LDNS;
第五步:LDNS把收到来自授权DNS服务器关于www.baidu.com对应的IP解析记录发给客户端浏览器,并且在LDNS本地把域名和IP的对应解析缓存起来,以便下一次更快的返回相同的解析请求的记录;
第六步:客户端浏览器获取到了www.baidu.com的对应IP地址,接下来浏览器会请求获得的IP地址对应的Web服务器,Web服务器接收到客户的请求并响应处理,将客户请求的内容返回给客户端浏览器;
至此,一次访问浏览网页的完整过程就完成了。
DNS解析原理
dns解析的流程:计算机之间只能通过ip相互通信,因为ip不好记,于是才使用dns服务器把域名解析为相应的ip,这里以解析www.baidu.com为例,当我们输入这个网址回车的时候,浏览器会首先查询浏览器的缓存,这个缓存存活时间可能只有1分钟,如果没找到,则去查询本地的dns缓存和hosts文件,如果有www.baidu.com这个域名对应的ip,则直接通过这个ip访问网站服务器。如果本地的dns缓存和hosts文件没找到,这时候就会把请求发送给,网卡配置信息里的dns服务器,默认有两个,只有当dns1不能访问时,才会使用dns2。我们也称网卡配置信息里的dns为local dns,这时候local dns会先查询它的缓存,有没有www.baidu.com相应的记录,如果有,则返回给用户,如果没有,就会访问根域名服务器,世界一共有13台根域名服务器,根域名服务器一看,是找.com的,于是会把.com的顶级域名服务器的ip发送给local dns,这时local dns再次访问.com的顶级域名服务器,.com的顶级域名服务器一看,是找一级域名baidu.com的,于是再将baidu.com的ip发送给local dns,然后继续往下找,直到找到www.baidu.com的权威dns的A记录或者cname,这时候local dns会把找到的www.baidu.com的ip发送给客户端,并记录在缓存中,这样的话,下次如果有其他的用户访问www.baidu.com这个域名时,local dns的缓存中就有记录了。客户端收到local dns发送过来的ip就会通过ip去访问服务器,并将这个ip记录在dns缓存中。
tcp/ip三次握手

通过dns解析之后,拿到了ip,就可以通过ip向服务器发送http请求了,因为http是工作在第七层应用层,tcp是工作在第四层传输层,所以发生http请求之前,还会进行tcp的三次握手。
tcp的三次握手是:客户端首先向服务器发送一个带有SYN标识和一个seq的随机数,服务端收到后,需要给客户端回应一个ack,ack的值就是刚才的seq随机数的值+1,在回应包里,还包含一个SYN的标识和一个seq随机数。客户端收到服务端发过来的回应包之后,再给服务端发送一个ack,ack的值就是刚才服务端发过来的seq的值+1。上面三步完成之后,三次握手就完成了,下面就可以开始传数据了
osi参考模型

TCP/IP模型处理过程

以太网的数据链路大致流程

路由解析:

静态路由

动态路由

路由算法

http协议原理(www服务请求过程)请求细节,报文细节
这里就是开始发送http请求报文了
http的请求报文,主要包括,请求行,请求头部,空行,请求主体

而请求行又包括,请求方法,url,协议版本,请求方法主要有GET、HEAD、POST、PUT、DELETE、MOVE,url就是统一资源定位符,通过这个能在服务器上找到唯一的网页资源,协议版本,目前主流的是http1.1,开始流行的协议版本是http1.0,相对应http1.0,http1.1主要从可扩展性、缓存处理、带宽优化、持久连接、host头、错误通知、消息传递、内容协商等多方面做了一些优化,以上是请求行的内容
再来说一些,请求头部,请求头部主要有媒体类型,语言类型、支持压缩、客户端类型、主机名等,媒体类型主要有文本文件,图片文件,视频文件等,语言类型就是告诉服务器客户端的接受的语言,支持压缩的话,可以节省带宽,客户端类型,会显示客户端浏览器的版本信息,操作系统信息等
空行,代表请求头部的结束,也代表着请求主体的开始
请求报文主体,只有使用POST提交表单的时候才有
大规模网站集群架构细节
常见的网页资源有三种,分别是静态网页,动态网页,伪静态
静态网页就是没有后台数据库,不含php,jsp,asp等程序,不可交互的,开发者编写的是啥,显示的就是啥,不会有任何改变
动态网页,有后台数据库,支持更多的功能,如用户注册,登录,发帖,订单,博客等,动态网页并不独立存在于服务器上的网页文件,而是当用户请求服务器上的动态程序时,服务器解析这些程序,并调用数据库来返回一个完整的网页内容,它跟静态网页的url不同,它的url中包含?、&等特殊符号,搜索引擎收录的时候存在一定的问题。动态网页为了方便收录,常常会利用rewrite技术,把动态网页的URL伪装成静态网页URL,这就是伪静态。
不同的网页资源,打开的流程不一样,下面假设我们访问的是一个静态网站:
客户端会通过http协议,下载服务器上的html文件,然后去读这个html文件,根据html页面中的链接,自上而下的请求,每一个请求是一个链接,如果是图片的话,会下载边渲染,遇到js,就会加载js,当js比较内容较复杂时,浏览器就会等待,鼠标在转圈,我们称这个为js阻塞,当js下载完毕并执行完成之后,才会显示我们看到的网页。
当我们访问的是一个动态网页时,首先用户发出一个请求,服务器收到这个请求之后,这里假设服务器使用的是nginx,nginx会把这个请求转给php,php就会去查询数据库,根据数据库返回的值,生成一个完整的网页内容,发送给用户,用户收到之后,也是边下载边渲染,加载js,执行完毕之后,才会显示我们看到的网页
当服务器的访问量达到亿级PV时,这个访问的过程就更复杂了,用户的请求会先访问全国的CDN节点,通过CDN挡住全国80%的请求,当CDN上没有时,在访问服务器集群,这个集群一般都有一个4层的代理,这个4层的代理,使用软件来完成的话,就是LVS,使用硬件就是F5,4层的代理,后面才是7层的负载均衡,常用的是haproxy,nginx,然后才是多台web服务器,web服务器比较多的时候,就有两个问题,一个是用户数据的一致性,不能因为不同的web服务器提供服务,而导致数据不同步,这时候,我们就需要使用NFS共享存储,第二个问题是session,不能因为不同的web服务器提供服务,session找不到了,这时候,我们就需要使用memcached来存放并共享session。由于用户访问量太大,这时候的瓶颈就是数据库的压力,我们一般都是使用分布式缓存memcache,redis等,另外数据库还需要做读写分离等优化,后面的过程与访问动态网页类似
http协议原理(www服务响应过程)响应细节,报文细节
对应的,服务器收到请求报文之后,就会给出响应报文
响应报文主要包含起始行、响应头部、空行、响应报文主体
起始行一般包含http版本号,数字状态码,状态情况
而数字状态码,常见有以下几种
200 代表ok
301 永久跳转
403 没权限
404 没有这个文件
500 未知的错误
502 网关错误
503 服务器超载,停机维护
504 网关超时
响应头部,主要包括,服务器的web软件版本,服务器时间,长连接还是短连接,设置字符集等等
这里的空行和请求报文空行一样
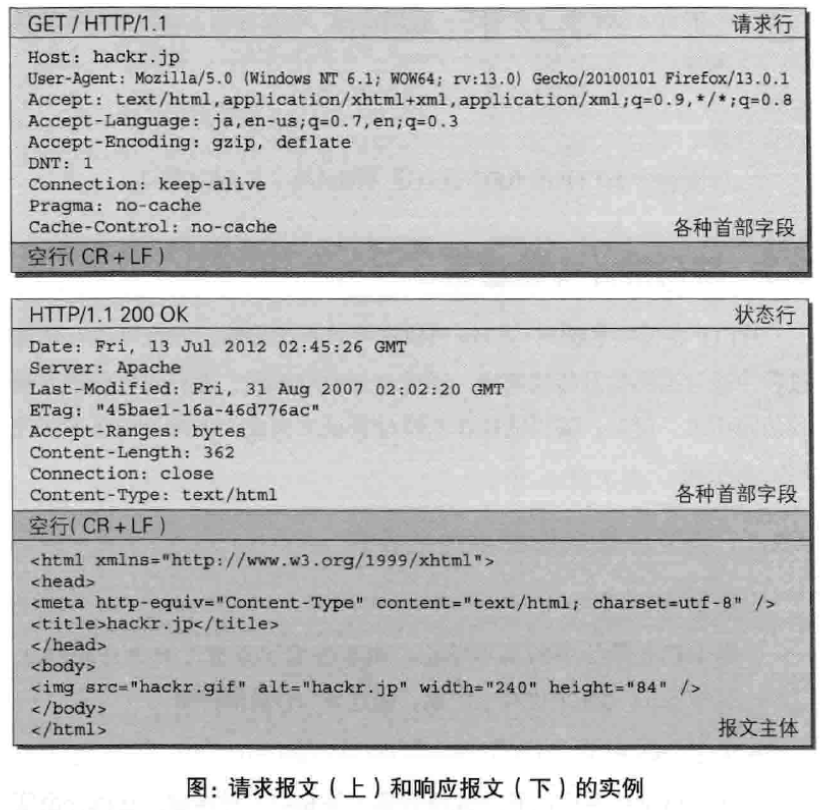
HTTP报文结构
(1)HTTP报文大致可以分为报文首部和报文主体两块

(2)请求报文和响应报文的结构实例
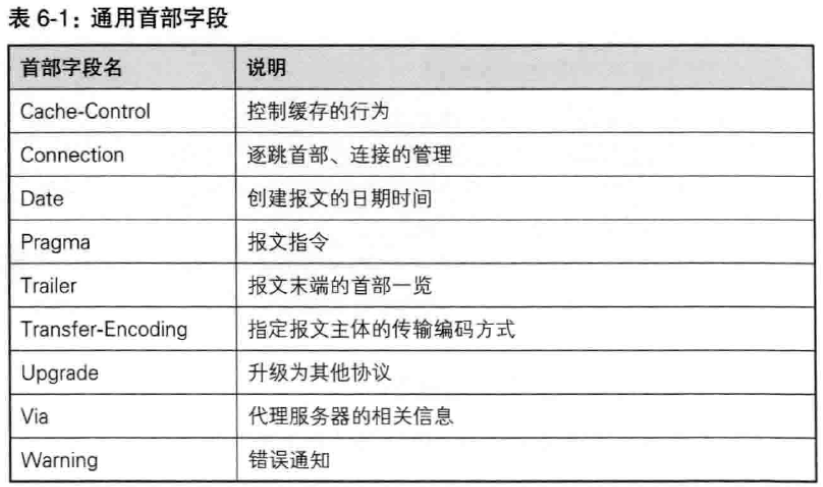
HTTP/1.1规范定义了如下47种首部字段
(1)通用首部字段
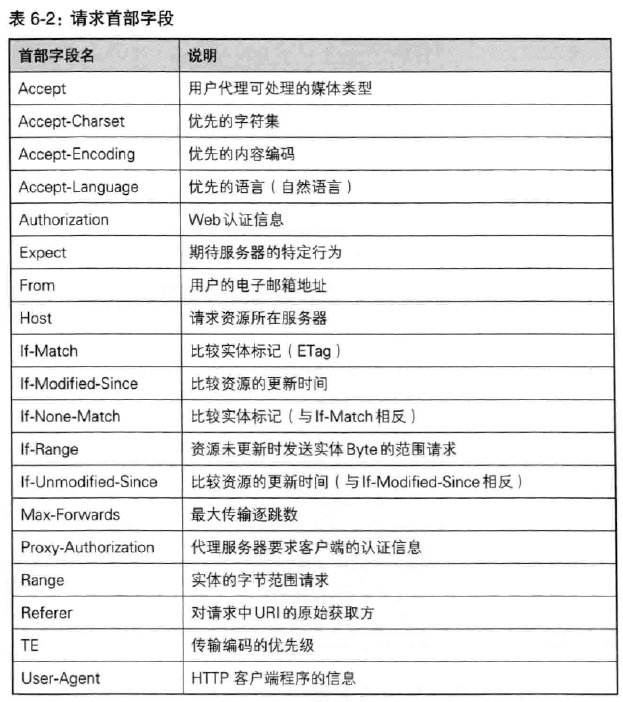
(2)请求首部字段
(3)响应首部字段


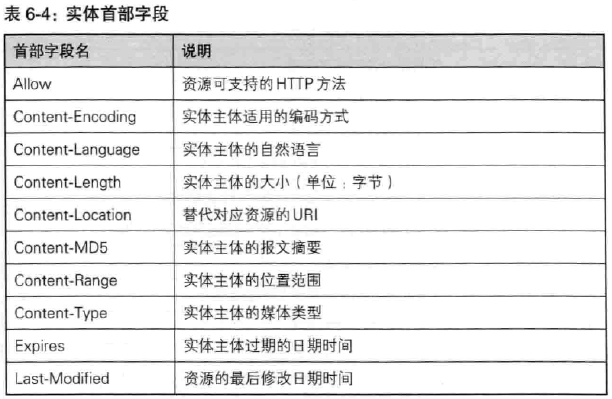
(4)实体首部字段
tcp/ip四次挥手过程
当浏览器加载一个完整的页面时,还需要与服务器断开连接,这个过程就是tcp的四次挥手
首先客户端会发送一个带有FIN标识和一个seq随机数,服务端收到之后,会回应一个ack,ack的值等于刚才的seq的值+1,发送之后,服务器会再发一个包,这个包里面也带有FIN标识和一个seq随机数,客户端收到之后,回应一个ack,ack的值等于刚才的seq值+1,以上完成之后,服务器和客户端的4次挥手就完成了!
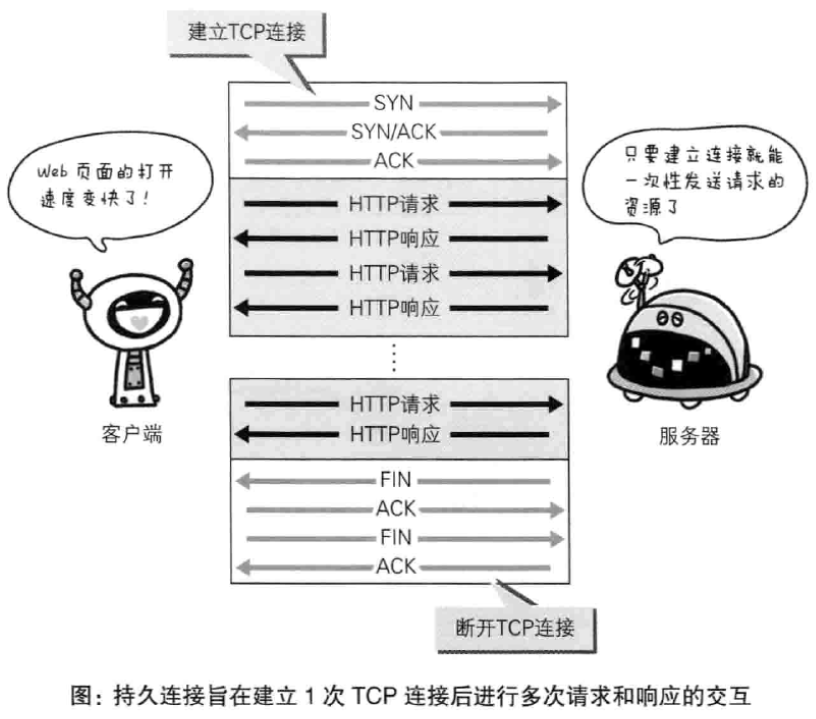
持久连接
在HTTP协议的初始版本中,每进行一次HTTP通信就要断开一次TCP连接。因此,每次的请求都会造成无谓的TCP连接建立与断开,增加通信量的开销。为了解决这个问题,HTTP/1.1想出了持久连接(也称为HTTP keep-alive),其特点是:只要任意一端没有明确提出断开连接,则保持TCP连接状态。