文章目录
含义
系统高可用,或者说系统的可用性,在计算机领域是一个相当久远并且重要的概念。小到CPU芯片、内存、硬盘等硬件组件,大到支付宝、微信等日常互联网服务,在设计、开发、维护的时候,都离不开对它的考量。
- 可用性度量和考核
所谓业务可用性(availability)也即系统正常运行时间的百分比,架构组最主要的 KPI (Key Performance Indicators ,关键业绩指标)。对于我们提供的服务(web,api)来说,更倾向用 N 个9 来量化可用性, 最常说的就是类似 “4个9(也就是99.99%)” 的可用性。
可用性的高低是使用不可用时间占总时间的比例来衡量。不可用时间是从故障发生到故障恢复的时间。比如,可用性 4 个 9 的系统(99.99%),它一年宕机时间不能超过53分钟。做到高可用系统,需要尽可能的降低故障发生的次数和减少故障持续的时间。
| 描述 | 可用性级别 | 年度停机时间 |
|---|---|---|
| 极高可用性 | 99.999% | 5分钟 |
| 具有故障自动恢复能里的可用性 | 99.99% | 53分钟 |
| 较高可用性 | 99.9% | 8.8小时 |
| 基本可用性 | 99% | 87.6小时 |
故障时间=故障修复时间点-故障发现(报告)时间点
服务年度可用时间%=(1-故障时间/年度时间)× 100%。
可用性KPI:以99.99%为例→53m=365*24*60*(1-0.9999)
- 服务可用性的级别划分
如果是一个分布式架构设计,系统由很多微服务组成,所有的服务可用性不可能都是统一的标准。如果所有服务都实现高等级可用性的话,那么成本就会增加,所以要根据服务的重要程度来进行可用性级别区分。
为了提高我们服务可用性,我们需要对服务进行分类管理并明确每个服务级别的可用性要求。
| 类别 | 可用性最低要求 | 描述 |
|---|---|---|
| 一级__核心服务 | 99.999%(全年5分钟不可用) | 系统引擎部分:一旦出现故障,整个系统瘫痪 |
| 二级__重要服务 | 99.99%(全年53分钟不可用) | 如外卖系统中的门店基础数据服务 |
| 三级__一般服务 | 99.9%(全年8.8小时不可用) | 如外卖系统中的智能推荐 |
| 四级__工具服务 | 99% | 非业务功能:比如后台管理系统、运维工具 |
ps:
平均无故障时间(MTTF)
MTTF(mean time to failure),指模块处在正常服务状态的平均时间。
平均修复时间(MTTR)
MTTR(mean time to repair),指模块处在服务中断状态的平均时间。
典型架构分层设计及各层实现高可用的原则
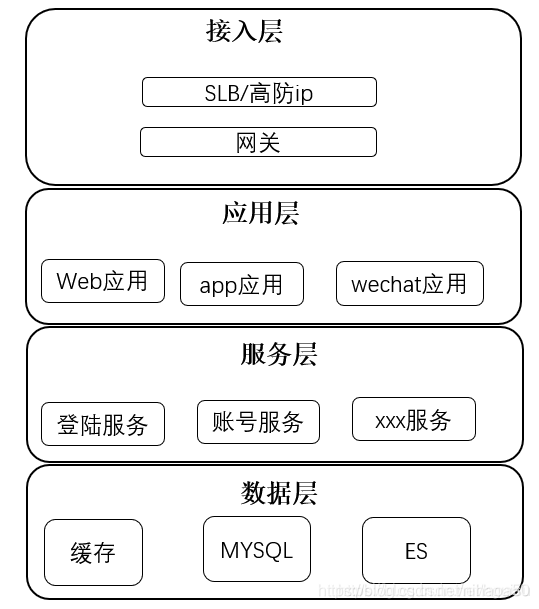
典型架构分层设计如下:按照功能处理顺序划分应用,这是面向业务深度的划分。架构分层图如下:
-
接入层:主要流量入口
-
应用层:直接对外提供产品功能,例如网站、API接口等。接入层不包含复杂的业务逻辑,只做呈现和转换。
-
服务层:根据业务领域每个子域单独一个服务。
-
数据层:数据库和NoSQL,文件存储、缓存等。
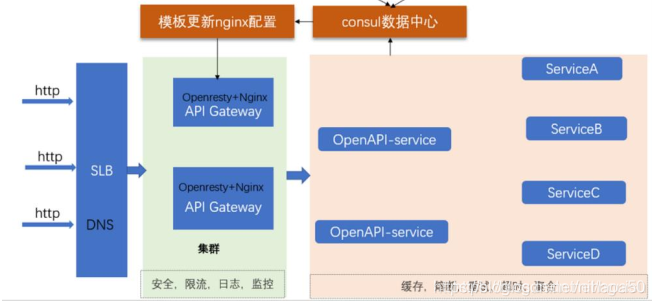
接入层高可用设计
接入层可能出现的问题:
- dns被劫持:域名是否使用https。
- 黑客攻击:是否有弱密,服务器权限,数据库权限
- ddos攻击:是否有必要使用高防IP接入流量。
- CC攻击:免费和收费版域名分开,网关是否有限流和防刷措施。
高可用设计方案:
- 域名规范解析和规范化管理,应该制定《域名规范管理说明》,例如根据产品重要等级,制定使用高防ip的策略。
- 规范API管理。
- 明确各个API限流和防刷策略。
接入层高可用架构设计模式:
应用层高可用设计
接入层可能出现的问题:
- 应用服务器宕机。
- 应用服务bug。
- 第三方服务不可用。
应用层设计主要原则:
-
可以水平扩展:通过接入层的负载均衡,实现故障自动转移。
-
无状态设计:无状态的系统更利于水平扩展,更利于做负载均衡。
状态是系统的吞吐量、易用性、可用性、性能和可扩展性的大敌,要尽最大可能避免。
-
回滚设计 :确保系统可以向后兼容,如果应用服务上线后出现bug,可以紧急回滚。
-
灰度发布:结合接入层设计A/B 功能,实现灰度发布,比如按ip,请求参数等分发流量。
服务层高可用设计
服务层可能出现的问题:
- 服务不可用或者出现bug
- 第三方服务不可用。
- 服务压力过大,由于服务之间大规模的调用关系,会导致系统“雪崩”
服务层高可用设计方案:
服务层设计最主要原则:服务分级管理(核心服务、重要服务、一般服务、工具服务)
线上有很多服务,每个服务的可用性要求不一样,我们需要先这些服务做分级。
1、各级服务的部署原则:核心服务:独立服务器且N+1部署。三级和四级服务可以共享服务器部署。
2、各级服务上线发布原则:核心和重要服务:晚上12点上线。,三级和四级随时可上线
3、各级服务监控原则:
1、核心服务
核心服务设计满足以下原则:
-
冗余N+1部署:故障自动转移到多部署一个节点,避免单点问题。
-
可监控:服务流量预警、端口存活、进程占用的资源、服务接口功能逻辑是否正常,应用FGC等情况。
-
可回滚、灰度:灰度部署服务,部署的服务出现问题可快速回滚。
-
可独立部署:可以直接在运维平台打包部署,而不需要依赖其他服务部署完成后才能部署运行。
-
可独立测试:可以单独测试。
-
水平扩展:流量激增可快速扩容。
-
异步设计:服务需要通知第三方服务,必须通过消息队列进行异步方式完成。
-
幂等设计:服务可以重复调用,不影响结果。
幂等广义上一般指以相同参数调用同一个接口多次,对系统内部产生的影响是一致的。比如说进行支付时,如果一次扣款操作因为某种原因调用了两次,那么理论上应该只生效一次,否则就会出现一定的风险。
举例说明:
反例:
比如我们在购物网站选好东西后,进入支付页面点击支付,此时支付请求发送给银行后端,然后从数据库中成功扣除了金钱,并将成功扣钱的消息返回至前端,问题来了,如果在返回途中网络发生异常,消息丢失,那么前端将无任何反应,这体现在用户身上很可能就是再次点击“支付按钮”进行支付!按照正常逻辑,此时支付请求发送给银行后端后是不应该再次扣除金钱的,但由于HTTP协议的无状态性,它不关心前一次是否扣除了金钱这个条件,只一视同仁地认定这一次是要扣除金钱的,所以最终必然会多扣一次钱! -
可容错:自身有容错和修复能力:
1)、隔离手段:服务使用的资源(CPU、线程、IO等)隔离,使 用舱壁模式;
2)、自我保护手段:快速失败(failfast)、流控、超时、熔断;
3)、失效转移或恢复手段:失效检测、重试、转移(failover)、回退恢复(failback);
4)、降级手段:依据依赖服务的重要性或依赖程度(强、弱),同步变异步,降级开关、拒绝部分服务等。
2、重要服务
重要服务设计满足以下原则:
- 冗余N+1部署:故障自动转移到多部署一个节点,避免单点问题。
- 可监控:监控进程、端口存活、进程占用的资源,应用FGC等。
- 可回滚、灰度:灰度部署服务,部署的服务出现问题可快速回滚。
- 故障隔离:服务器只部署唯一该应用服务,该应用服务出现问题,只影响自身服务问题。
- 可独立部署:可以直接在运维平台打包部署,而不需要依赖其他服务部署完成后才能部署运行。
- 可独立测试:可以单独测试。
- 水平扩展:流量激增可快速扩容。
- 可容错:自身有容错和修复能力。
3、一般服务
一般服务设计满足以下原则:
- 可以接受单点部署。
- 可监控:可监控服务进程、端口存活是否正常。
- 可回滚、灰度:灰度部署服务,部署的服务出现问题可快速回滚。
4、故障隔离:一个服务器上可以部署多个应用,但保证服务器资源充足。
5、可独立部署:需要独立部署。
6、可独立测试:可以单独测试。
7、水平扩展:流量激增可快速扩容。
8、可容错:需要具备一般的容错能力。
4、工具服务
服务设计满足以下原则:
1、冗余N+1部署:可以单点部署,只要有个进程存活就可以。
2、可监控:不需要监控。
3、可回滚、灰度:只要部署成功就可以。
4、故障隔离:哪个服务器有资源就可以部署。
5、可独立部署:不用考虑。
6、可独立测试:不用考虑。
7、水平扩展:不用考虑。
8、可容错:不用考虑。
服务与设计原则关系表:
| 服务类别 | 部署 | 监控 | 回滚、灰度 | 故障隔离 | 独立部署 | 独立测试 | 水平扩展 | 容错 | 异步设计 | 幂等设计 |
|---|---|---|---|---|---|---|---|---|---|---|
| 核心服务 | 冗余N+1部署:故障自动转移到多部署一个节点,避免单点问题。 | 服务流量预警、端口存活、进程占用的资源、服务接口功能逻辑是否正常,应用FGC等情况。 | 灰度部署服务,部署的服务出现问题可快速回滚。 | 未提及 | 可以直接在运维平台打包部署,而不需要依赖其他服务部署完成后才能部署运行。 | 需要 | 需要 | 自身有容错和修复能力 | 需要 | 需要 |
| 重要服务 | ⚡⚡ | 监控进程、端口存活、进程占用的资源,应用FGC等 | ⚡⚡ | 服务器只部署唯一该应用服务,该应用服务出现问题,只影响自身服务问题 | ⚡⚡ | 需要 | 需要 | ⚡⚡ | 不用考虑 | 不用考虑 |
| 一般服务 | 可以单点部署 | 监控服务进程、端口存活是否正常 | ⚡⚡ | 一个服务器上可以部署多个应用,但保证服务器资源充足 | 需要独立部署 | 需要 | 需要 | 具备一般的容错能力 | 不用考虑 | 不用考虑 |
| 工具服务 | 单点部署,只要有个进程存活就可以 | 不用考虑 | 只要部署成功就可以 | 哪个服务器有资源就可以部署 | 不用考虑 | 不用考虑 | 不用考虑 | 不用考虑 | 不用考虑 | 不用考虑 |
数据层的高可用设计
数据层可能出现的问题:
- 数据库服务器磁盘损坏导致数据库不可用等
数据架构设计原则:

保障高可用系统的技术方案
| 技术 | 解决的问题 |
|---|---|
| 扩展 | 通过冗余部署,避免单点故障 |
| 隔离 | 避免业务之间的相互影响 。机房隔离避免单点故障 |
| 解耦 | 减少依赖,减少相互间的影响 |
| 限流 | 遇到突发流量时,保证系统稳定 |
| 降级 | 牺牲非核心业务,保证核心业务的高可用 |
| 熔断 | 减少不稳定的外部依赖对核心服务的影响 |
| 自动化测试 | 通过完善的测试,减少发布引起的故障 |
| 灰度发布 | 灰度发布是速度与安全性作为妥协,能够有效减少发布故障 |
扩展
扩展是最常见的提升系统可靠性的方法,系统的扩展可以避免单点故障,即一个节点出现了问题造成整个系统无法正常工作。换一个角度讲,一个容易扩展的系统,能够通过扩展来成倍的提升系统能力,轻松应对系统访问量的提升。
一般地,扩展可以分为垂直扩展和水平扩展:
-
垂直扩展:是在同一逻辑单元里添加资源从而满足系统处理能力上升的需求。比如,当机器内存不够时,我们可以帮机器增加内存,或者数据存不下时,我们为机器挂载新的磁盘。
垂直扩展能够提升系统处理能力,但不能解决单点故障问题。
优点:扩展简单。
缺点:扩展能力有限。 -
水平扩展:通过增加一个或多个逻辑单元,并使得它们像整体一样的工作。
水平扩展通过冗余部署解决了单点故障,同时又提升了系统处理能力。
优点:扩展能力强。
缺点:增加系统复杂度,维护成本高,系统需要是无状态的、可分布式的。
隔离
对系统、业务所占有的资源进行隔离,限制某个业务对资源的占用数量,避免一个业务占用整个系统资源,对其他业务造成影响。
隔离级别按粒度从小到大,可以分为线程池隔离、进程隔离、模块隔离、应用隔离、机房隔离。在数据库的使用中,还经常用到读写分离。
- 线程池隔离:不同的业务使用不同的线程池,避免低优先级的任务阻塞高优先级的任务。或者高优先级的任务过多,导致低优先级任务永远不会执行。
- 进程隔离:Linux 中有用于进程资源隔离的 Linux CGroup,通过物理限制的方式为进程间资源控制提供了简单的实现方式,为 Linux Container 技术、虚拟化技术的发展奠定了技术基础。
- 模块隔离、应用隔离:很多线上故障的发生源于代码修改后,测试不到位导致。按照代码或业务的易变程度来划分模块或应用,把变化较少的划分到一个模块或应用中,变化较多的划分到另一个模块或应用中。减少代码修改影响的范围,也就减少了测试的工作量,减少了故障出现的概率。
- 机房隔离:主要是为了避免单个机房网络问题或机房电源故障。
- 读写分离:一方面,将对实时性要求不高的读操作,放到 DB 从库上执行,有利于减轻 DB 主库的压力。另一方面,将一些耗时离线业务 sql 放到 DB 从库上执行,能够减少慢 sql 对 DB 主库的影响,保证线上业务的稳定可靠。
解耦
在软件架构设计中,模块之间的解耦或者说松耦合有两种,假设有两个模块A、B,A依赖B:
- 模块A和模块B只通过接口交互,只要接口设计不变,那么模块B内部细节的变化不影响模块A对模块B服务能力的消费。
- 将同步调用转换成异步消息交互
比如在买机票系统中,机票支付完成后需要通知出票系统出票、代金券系统发券。如果使用同步调用,那么出票系统、代金券系统宕机是会影响到机票支付系统。如果我们将同步调用替换成异步消息,机票支付系统发送机票支付成功的消息到消息中间件,出票系统、代金券系统从消息中间件订阅消息。这样一来,出票系统、代金券系统的宕机也就不会对机票支付系统造成任何影响了。
限流
一个系统的处理能力是有上限的,当服务请求量超过处理能力,通常会引起排队,造成响应时间迅速提升。如果对服务占用的资源量没有约束,还可能因为系统资源占用过多而宕机。因此,为了保证系统在遭遇突发流量时,能够正常运行,需要为你的服务加上限流。
限流分类:
- 按照计数范围,可以分为:单机限流、全局限流。单机限流,一般是为了应对突发流量,而全局限流,通常是为了给有限资源进行流量配额。
- 按照计数周期,可以分为:QPS、并发(连接数)。
- 按照阈值设定方式的不同,可以分为:固定阈值、动态阈值。
常见的限流算法有:漏桶算法、令牌桶算法、滑动窗口计数法。
降级
业务降级,是指牺牲非核心的业务功能,保证核心功能的稳定运行。要实现优雅的业务降级,需要将功能实现拆分到相对独立的不同代码单元,分优先级进行隔离。在后台通过开关控制,降级部分非主流程的业务功能,减轻系统依赖和性能损耗,从而提升集群的整体吞吐率。
简单的说:当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
降级的重点是:业务之间有优先级之分,保证核心业务的执行。降级的典型应用是:电商活动期间关闭非核心服务,保证核心买买买业务的正常运行。
业务降级通常需要通过开关工作,开关一般做成配置放在专门的配置系统,配置的修改最好能够实时生效,毕竟要是还得修改代码发布那就太 low 了。开源的配置系统有阿里的diamond、携程的Apollo、百度的disconf。
降级往往需要兜底方案的配合,比如系统不可用的时候,对用户进行提示,安抚用户。提示虽然不起眼,但是能够有效的提升用户体验。
熔断
在电力学中,当电流会不断升高,负载过大,保险丝会熔断切断电流,从而起到保护电路安全运行的作用。此处熔断的意思跟电力学的熔断差不多。
在分布式系统中,如果调用的远程服务或者资源由于某种原因无法使用时,没有这种过载保护,就会导致请求阻塞在服务器上等待从而耗尽服务器资源。很多时候刚开始可能只是系统出现了局部的、小规模的故障,然而由于种种原因,故障影响的范围越来越大,最终导致了全局性的后果。而这种过载保护就是大家俗称的熔断器(Circuit Breaker)。
自动化测试
为什么自动化测试是构建高可用系统的技术方案 ?
众所周知,一个项目上线前需要经历严格的测试过程,但是随着业务不断迭代、系统日益复杂,研发工程师、产品经理、测试工程师等都在测试过程中投入了大量精力,而一个个线上故障却表明测试效果并不是那么完美。究其原因,目前的测试工作主要存在两方面问题:
- 测试范围难以界定:随着业务逻辑的不断迭代、系统的不断拆分与细化,精确评估项目改动的影响范围变得越来越困难,从而很难梳理出覆盖全面的测试点。
- case验证成本过高:验证一个case需要构造测试场景,包括数据的准备和运行环境的准备,当case量较大或者存在一些涉及多个系统模块且触发条件复杂的case时,这一过程也将花费大量的时间。
解决上述问题可以使用模块级自动化测试。具体方案是:针对某一模块,收集模块线上的输入、输出、运行时环境等信息,在离线测试环境通过数据mock模块线上场景,回放收集的线上输入,相同的输入比较测试场景与线上收集的输出作为测试结果。
灰度发布&回滚
-
回滚。
一般在线上出现故障后,第一个要考虑的就是刚刚有没有代码发布、配置发布,如果有的话就先回滚。线上故障最重要的是快速恢复,如果等你细细看代码找到问题,没准儿半天就过去了。 -
灰度发布基础知识
灰度发布: 是指在黑与白之间,能够平滑过渡的一种发布方式。在其上可以进行A/B testing,即让一部分用户继续用产品特性A,一部分用户开始用产品特性B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
灰度期: 灰度发布开始到结束期间的这一段时间,称为灰度期。
好处:- 提前获得目标用户的使用反馈;
- 根据反馈结果,做到查漏补缺;
- 发现重大问题,可回滚“旧版本”;
- 补充完善产品不足;
- 快速验证产品的 idea。
背景监控&报警
监控系统,处于整个服务可靠度层级模型的最底层,是运维一个可靠的稳定系统必不可少的重要组成部分。
为了保障全链路业务和系统高可用运行,需要在用户感知问题之前发现系统中存在的异常,离开了监控系统,我们就没有能力分辨客户端是不是在正常提供服务。
按照监控的领域方向,可以分成系统监控与业务监控:
- 系统监控,主要用于基础能力如端到端成功率,服务响应时长,网络流量,硬件性能等相关的监控。 系统监控侧重在无业务侵入和定制系统级别的监控,更多侧重在业务应用的底层,多属于单系统级别的监控。
- 业务监控,侧重在某个时间区间,业务的运行情况分析。业务监控系统构建于系统监控之上,可以基于系统监控的数据指标计算,并基于特定的业务介入,实现多系统之间的数据联合与分析,并根据相应的业务模型,提供实时的业务监控与告警。
按照业务监控的时效性,可以继续将其细分成实时业务监控与离线业务监控。
- 实时业务监控,通过实时的数据采集分析,帮助快速发现及定位线上问题,提供告警机制及介入响应(人工或系统)途径,帮助避免发生系统故障。
- 离线的业务监控,对一定时间段收集的数据进行数据挖掘、聚合、分析,推断出系统业务可能存在的问题,帮助进行业务上的重新优化或改进的监控。
拆分
-
水平拆分
如本文提到的架构分层设计就是水平拆分。架构分层 -
垂直拆分
根据功能垂直划分,拆成相对独立的模块。有的仅是服务层做了拆分,存储层共用。更为彻底的是,拆分与该系统的业务领域模型关联,一个领域模型划分成一个模块。在数据库层面,还可以分库分表拆分,这样一个库的损坏,不会影响到其他库。分库分表需要增加路由逻辑,及保证路由规则的一致性。
缓存
在高并发应用中,肯定避免不了数据的频繁读写,这时候缓存就能够起到很大作用了,一般会使用像Redis集群这样的高性能缓存,减少数据库的频繁读取,以提高数据的查询效率。
容灾备份
容灾系统,对于IT而言,就是为计算机信息系统提供的一个能应付各种灾难的环境。当计算机系统在遭受如火灾、水灾、地震、战争等不可抗拒的自然灾难以及计算机犯罪、计算机病毒、掉电、网络/通信失败、硬件/软件错误和人为操作错误等人为灾难时,容灾系统将保证用户数据的安全性(数据容灾),甚至,一个更加完善的容灾系统,还能提供不间断的应用服务(应用容灾)。可以说,容灾系统是数据存储备份的最高层次。
划重点(∩_∩)
本人程序媛一枚,因为离港澳较近,周末兼职港澳人肉代购。
欢迎各位大佬添加本人微信,还会经常有点赞活动送价值不菲的小礼品哦。
即使现在不需要代购,等以后有了女(男)朋友、有了宝宝就肯定会需要的喽。
动动手指头,扫码一下,就当是对本博文的支持嘛,也是对一个平凡、勤劳、勇敢、秀外慧中等等优点的程序媛莫大的支持哈。
参考文献(侵删):
高可用架构设计
高可用系统的一些技术方案
漫画:什么是服务熔断
微服务架构—服务降级
美团2000万日订单背后,如何保障系统的高可用?
实现系统高可用,常用的解决手段
高可用系统设计建议简介
高并发&高可用系统应对策略的一些思考
如何保障高并发系统的稳定性与高可用