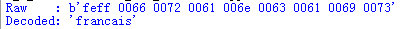6.10.3 字节序
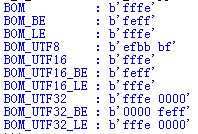
在不同计算机系统之间传输数据时(可能直接复制一个文件,或者使用网络通信来完成传输),多字节编码(如UTF-16和UTF-32)会带来一些问题。不同系统中使用的高字节和低字节的顺序不同。数据的这个特性被称为字节序(endianness),这取决于硬件体系结构等因素,还取决于操作系统和应用开发人员做出的选择。通常没有办法提前知道给定的一组数据要使用哪一个字节序,所以多字节编码还包含一个字节序标志(Byte-Order Marker,BOM),这个标志出现在编码输出的前几个字节。例如,UTF-16定义0xFFFE和0xFEFF不是合法字符,可以用于指示字节序。codecs定义了UTF-16和UTF-32所用字节序标志的相应常量。
import codecs
from codecs_to_hex import to_hex
BOM_TYPES = [
'BOM','BOM_BE','BOM_LE',
'BOM_UTF8',
'BOM_UTF16','BOM_UTF16_BE','BOM_UTF16_LE',
'BOM_UTF32','BOM_UTF32_BE','BOM_UTF32_LE',
]
for name in BOM_TYPES:
print('{:12} : {}'.format(
name,to_hex(getattr(codecs,name),2)))
取决于当前系统的原生字节序,BOM、BOM_UTF16和BOM_UTF32会自动设置为适当的大端(big-endian)或小端(little-endian)值。
运行结果:
可以由codecs中的解码器自动检测和处理字节序,也可以在编码时显式地指定字节序。
import codecs
from codecs_to_hex import to_hex
# Pick the non-native version of UTF-16 encoding.
if codecs.BOM_UTF16 == codecs.BOM_UTF16_BE:
bom = codecs.BOM_UTF16_LE
encoding = 'utf_16_le'
else:
bom = codecs.BOM_UTF16_BE
encoding = 'utf_16_be'
print('Native order :',to_hex(codecs.BOM_UTF16,2))
print('Selected order:',to_hex(bom,2))
# Encode the text.
encoded_text = 'francais'.encode(encoding)
print('{:14}: {}'.format(encoding,to_hex(encoded_text,2)))
with open('nonnative-encoded.txt',mode='wb') as f:
# Write the selected byte-order marker. It is not include
# in the encoded text because the byte order was given
# explicitly when selecting the encoding.
f.write(bom)
# Write the byte string for the encoded text.
f.write(encoded_text)
codecs_bom_create_file.py竖线得出原生字节序,然后显式地使用替代形式,以便下一个例子可以在展示读取时自动检测字节序。
运行结果:

codecs_bom_detection.py打开文件时没有指定字节序,所以解码器会使用文件前面两个字节中的BOM值来确定字节序。
import codecs
from codecs_to_hex import to_hex
# Look at the raw data.
with open('nonnative-encoded.txt',mode='rb') as f:
raw_bytes = f.read()
print('Raw :',to_hex(raw_bytes,2))
# Reopen the file and let codecs detect the BOM.
with codecs.open('nonnative-encoded.txt',
mode='r',
encoding='utf-16',
) as f:
decoded_text = f.read()
print('Decoded:',repr(decoded_text))
由于文件的前两个字节用于字节序检测,所有它们并不包含在read()返回的数据中。
运行结果: