本章内容
索引操作
赋值操作
排序
- DataFrame
- Series
数据准备
首先,为了更好的理解这些基本操作,我们将读取一个真实的股票数据。关于文件操作,后面在介绍,这里只先用一下API
stock_day.csv文件下载链接:
链接:https://pan.baidu.com/s/1P8dfFl5FF64yfm1i6GGTuw
提取码:wbcs
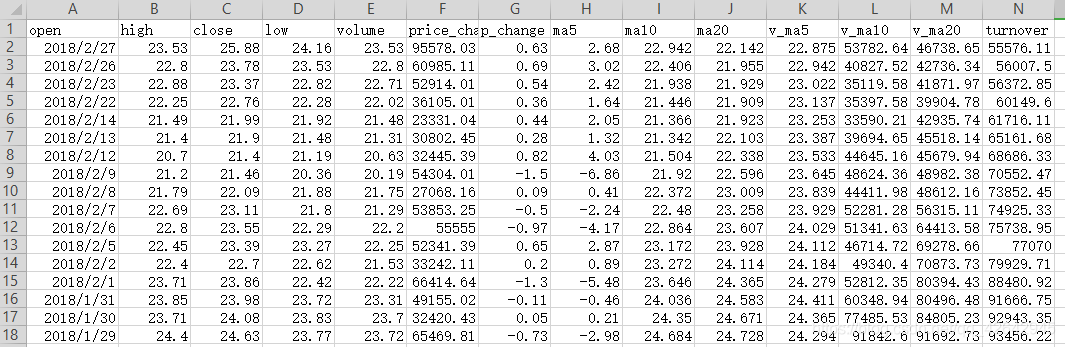
#导入pandas模块
import pandas as pd
#读取csv数据文件
data = pd.read_csv('./stock_day.csv')
data.head()
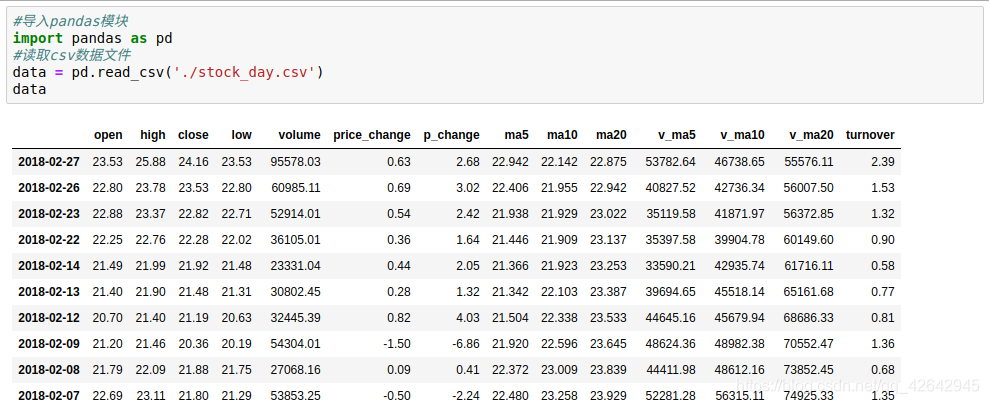
#删除一些列,使得数据简单些,再去做后面的操作
data = data.drop(['ma5','ma10','ma20','v_ma5','v_ma10','v_ma20'],axis = 1)
data.head()
第一节 索引操作
Numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似的操作,也可以直接使用列名、行名称,甚至组合使用。
直接使用行列索引(先列后行)
data[‘open’] <-- 通过key来索引一个列
data.open <-- 通过属性的形式索引一个列, 当列的名称是一个Python关键字时,不能用这种方法
添加class列:
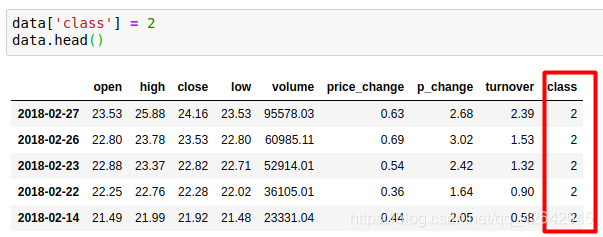
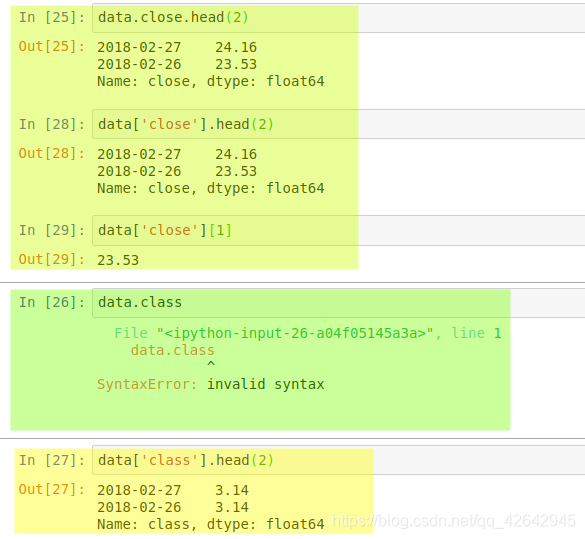
直接使用行列索引(先列后行)
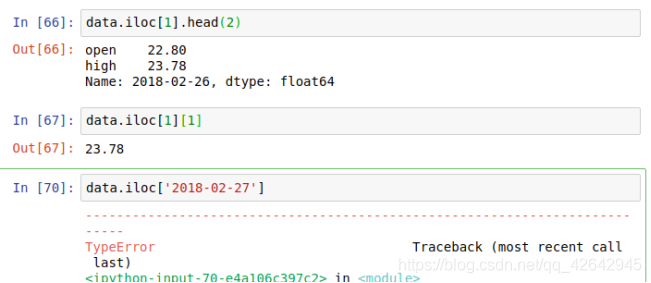
获取’2018-02-27’这天的’close’的结果
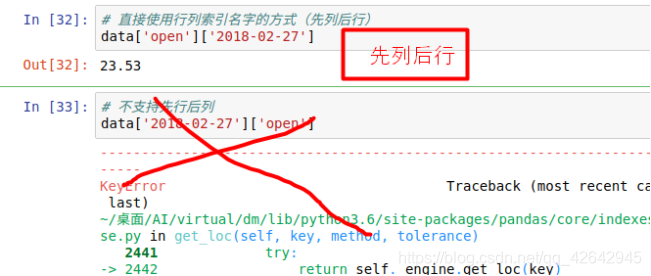
结合loc或者iloc使用索引
api 简介
loc: label-based location,基于标签的索引
- data.loc[‘2018-02-23’, ‘close’] <-- 基于标签索引
iloc: integer-based location,基于行列数的索引
- data.iloc[1, 0] <-- 索引第1行第0列
使用ix组合索引
ix能混合使用整数和标签型索引,但是已经过期,不建议使用
推荐使用loc/iloc配合的方式:
data.loc[data.index[:4], [‘open’, ‘high’, ‘low’, ‘close’]]
loc:
- 只能通过标签名来取数据
- 不能通过索引(第0行,第1行等)来取数据
- 取列数据也一样,要通过标签名,不能直接取行数据
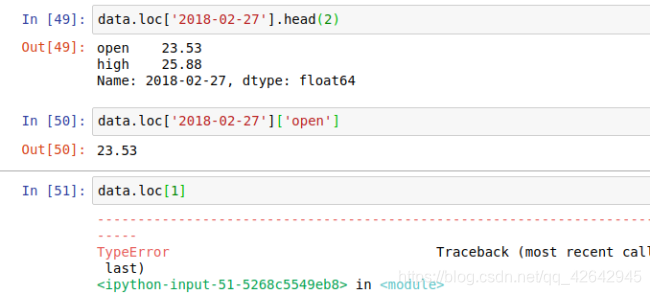
iloc:
- 只能通过索引(第0行,第1行等)来取数据
- 使用标签名则发生错误
- 取列数据
ix:(不建议使用)(过期)
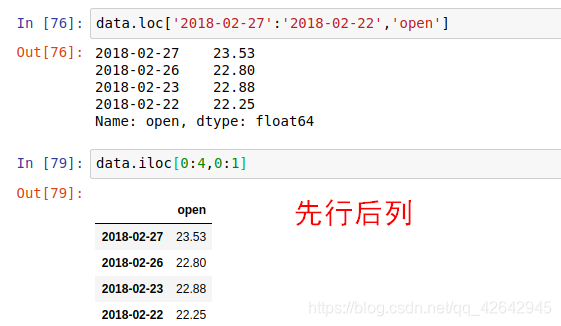
获取从’2018-02-27’:‘2018-02-22’,'open’的结果
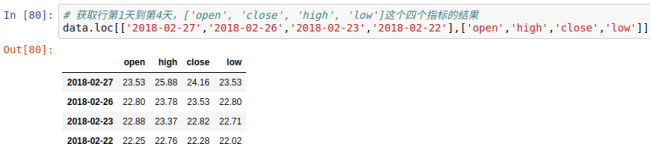
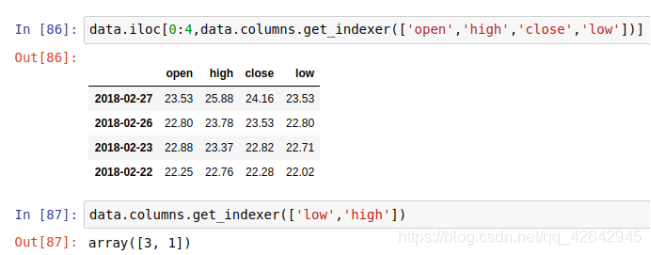
获取行第1天到第4天,[‘open’, ‘close’, ‘high’, ‘low’]这个四个指标的结果

第二节 赋值操作
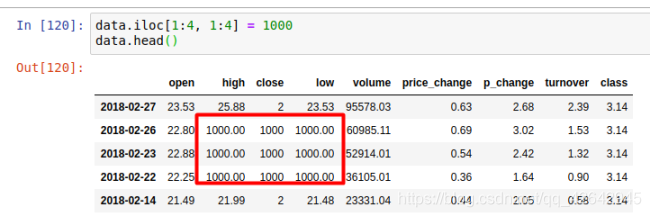
可以对一整列整体赋值,也可以对选定的某个/某些单元格赋值,data.iloc[1:4, 1:4] = 1000
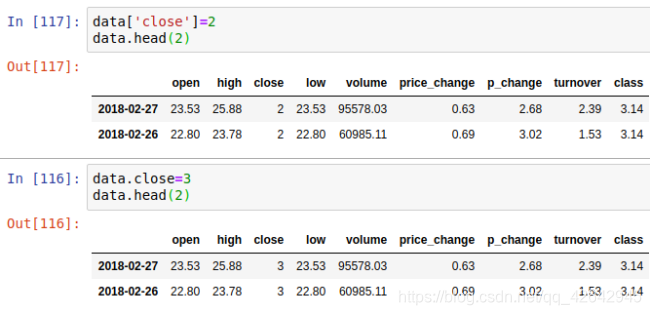
对DataFrame当中的close列进行重新赋值为2,3
直接修改原来的值
第三节 排序
排序有两种形式,一种对内容进行排序,一种对索引进行排序
data.sort_index(), 按照行索引的值来排序,默认是升序排列,通过参数ascending=False可以设置为降序排列
data.sort_values(),按照DataFrame的值来排序,可以按照某一列或者某几个列来排序
DataFrame排序
- 使用
df.sort_values(key=, ascending=)对内容进行排序- 单个键或者多个键进行排序,默认升序
- ascending=False:降序
- ascending=True:升序

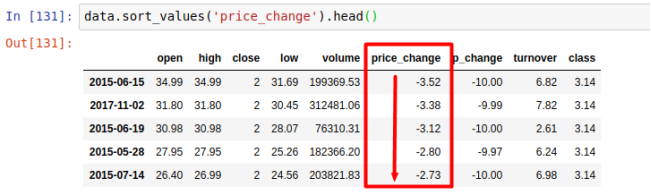
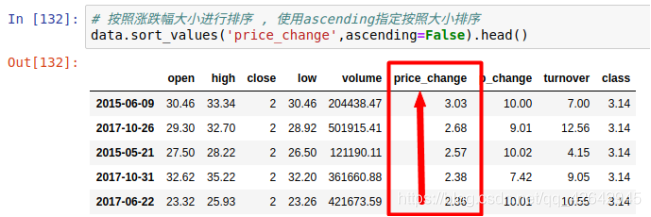
按照涨跌幅大小进行排序 , 使用ascending指定按照大小排序
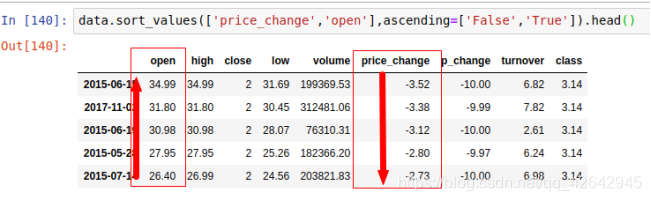
按照多个键进行排序
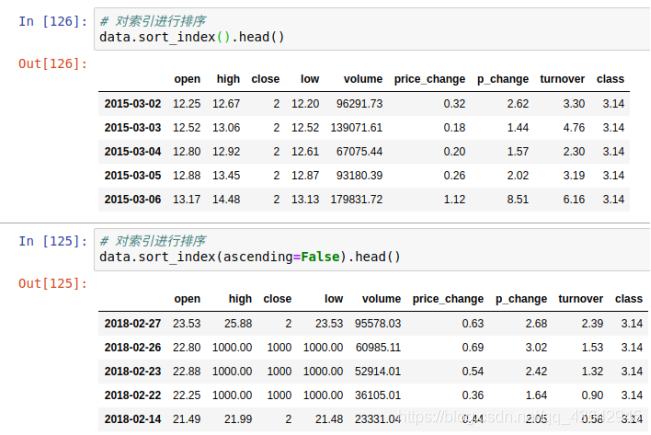
- 使用df.sort_index对索引进行排序
这个股票的日期索引原来是从大到小,现在重新排序,从小到大
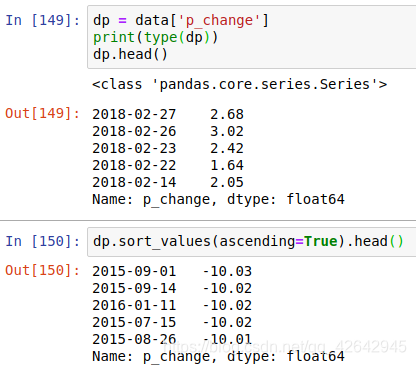
Series排序
- 使用series.sort_values(ascending=True)对内容进行排序
series排序时,只有一列,不需要参数
- 使用series.sort_index()对索引进行排序
与df一致,对索引进行排序
版权声明:
笔者博客文章主要用来作为学习笔记使用,内容大部分整理自互联网,如有侵权,请联系博主删除!