相比update和insert,一般查询应该是数据库中操作最频繁的。而在有些应用场景需要用到like模糊查询,那么对于大数据,查询的时候就要注意了。
现在来分析一下为什么like语句查询的效率会很低,测试数据共4000000条,如下图:
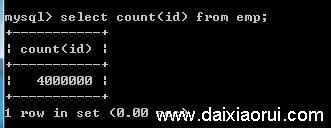
第一步:不使用索引
下图可以看出,不使用索引的时候普通查询与like查询的耗时相当,like略长,这也是必然的,因为它要进行额外的算法。
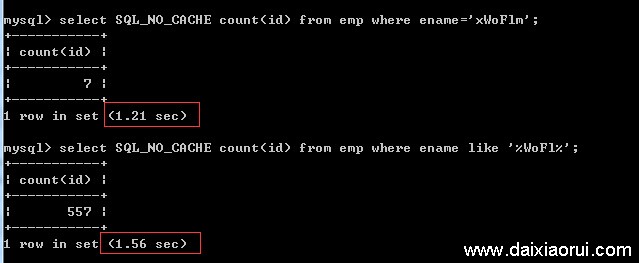
第二步:使用索引
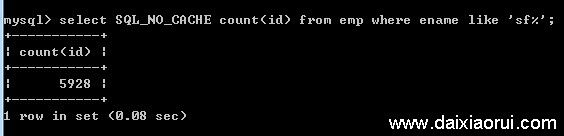
如下图,使用索引后,普通查询的耗时基本算是秒查,非常快;而like查询还是耗时一秒多。
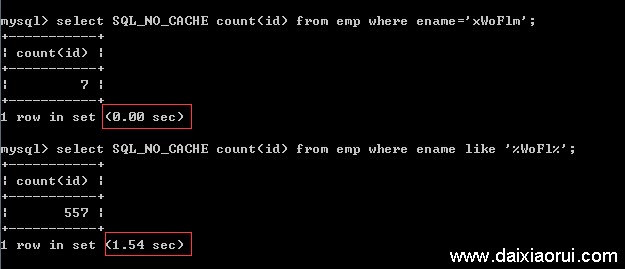
第三步:分析原因
如下图,用explain分析一下,此时我们立刻明白了,普通查询用到了索引,但是like语句没有用到索引。
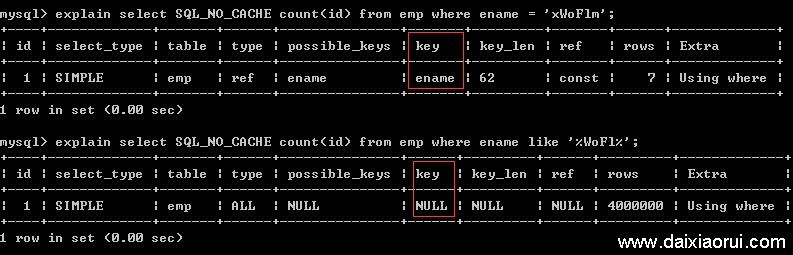
所以,照成mysql中like查询效率低下的原因是:在有些情况下,like查询使用不到索引,会扫描全表。
最后,补充一下,like语句有时候也是可以用到索引的,如下图,如果我们查询的时候写成“like 'dd_'或者like 'dd%'”,这样是可以用到索引的,此时的查询速度也会相对的快一点。虽然快了一点,但是还是比普通查询耗时要多很多。
因此,当表的数据量比较大的时候,尽量还是不要用like语句了。如果想做模糊搜索,建议用搜索引擎,比如solr,这样会比like强大n倍。