Introduction to Computer Vision
参考:Ubuntu 16 安装TensorFlow及Jupyter notebook 安装TensorFlow。
本篇博客翻译来自 Introduction to TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning
仅供学习、交流等非盈利性质使用!!!
文章目录
1. 机器视觉
给定如下的一组图片,计算机会如何识别(鞋子是鞋子)?

本次实例就是使用类似这样的图片数据来进行识别。
数据使用:fashion-mnist
使用TensorFlow加载数据:
fashion_mnist - keras.datasets.fashion_mnist
(train_images, train_labels), (test_images,test_labels) = fashion_mnist.load_data()
原始数据如下:
![]()

训练集大概有60k条记录、测试集有10k条记录。
每条记录是一个28*28的一个图形,像素点从0~255.
- 使用这么小像素是因为存储空间较小,同时这也的像素也能区分不同的物品;
- 数据加载后,train_images中的一个类似:

而这个图片其类别是9, 这里为什么用数字9,而不是类似一个字符串:“鞋子”、“Ankle boot”是因为,使用这样的数字,计算机更好识别。
数据加载完成后,就可以构建模型了。
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax),
])
上面代码包含下面信息:
- 神经网络有3层,其中第一层使用Flatten构建;
- 第一层的input_shape是(28,28)是因为数据是2828,而Flatten则是把2828的矩阵转换为一个向量,也就是1*784的向量;
- 最后一层有10个神经元,因为最终有10个类别;
中间层,也称为隐藏层,如下;
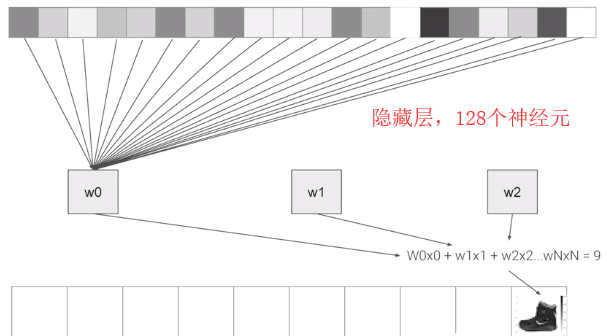
中间层的神经元会负载参数W,通过W的调整就可以得到所有数据都满足给定的,比如给定的数据是一个鞋子,那么要通过调整所有W参数,直到得到其值是9.
2. Fashion Mnist识别完整代码
2.1 导入包
import tensorflow as tf
print(tf.__version__)
由于Fashion Mnist数据已经在tf.keras中,所以可以直接加载:
mnist = tf.keras.datasets.fashion_mnist
调用load_data函数可以得到2份数据集,分别包含训练、测试集以及其对应的类别:
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
数据加载后,可以通过下面的代码来看一下:
# %matplotlib
import matplotlib.pyplot as plt
plt.imshow(training_images[0])
print(training_labels[0])
print(training_images[0])
其输出结果为:

从输出结果可以看出,测试数据其中的一个样本是一个28*28的矩阵,其数据从0~255,当然你也可以换个index,查看其它数据。
一般情况下,在神经网络中使用01的数据,更易于进行训练,所以这里需要把0255的数据进行归一化,使用如下代码:
training_images = training_images / 255.0
test_images = test_images / 255.0
构建模型:
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
- Sequential: 定义一个序列化的神经网络模型;
- Flatten:把矩阵数据转换为向量数据;
- Dense:添加一个神经元层;
- activation function: 告诉神经元如何视输入数据情况进行输出;
- Relu: if x>0 return x else return 0 ;
- Softmax:找到输入x集合中最大的一个,并把其值置为1,其他值设置为0;
接下来,定义优化器和损失函数,然后就可以训练模型了。
model.compile(optimizer = tf.train.AdamOptimizer(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)
模型训练结果:
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/ops/resource_variable_ops.py:435: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
Epoch 1/5
60000/60000 [==============================] - 15s 248us/sample - loss: 0.4982 - acc: 0.8243
Epoch 2/5
60000/60000 [==============================] - 14s 232us/sample - loss: 0.3716 - acc: 0.8655
Epoch 3/5
60000/60000 [==============================] - 13s 209us/sample - loss: 0.3370 - acc: 0.8772
Epoch 4/5
60000/60000 [==============================] - 12s 198us/sample - loss: 0.3112 - acc: 0.8857
Epoch 5/5
60000/60000 [==============================] - 13s 212us/sample - loss: 0.2944 - acc: 0.8913
模型训练完成后,可以看到这个模型正确率大概是89%左右,当然这个数据是针对训练集的。
如果要针对测试集进行测试,那么使用如下代码:
model.evaluate(test_images, test_labels)
10000/10000 [==============================] - 1s 114us/sample - loss: 0.3627 - acc: 0.8668
从上面的结果可以看出,正确率大概是87%左右,这个是还是比较低的。
2.2 探索练习
1. 练习1
执行如下代码:
classifications = model.predict(test_images)
print(classifications[0])
classification 是一串代码,这串代码代表啥?
- 1. 10个无意义的随机数;
- 2. 机器预测的前10个分类结果;
- 3. 当前测试集的10个类别的可能性;
什么样的结果显示当前图片是一个ankle boot?
- 1. 不知道
- 2. 在列表中的第10个值是最大的,那么其对应的图片就是ankle boot;
2. 练习2
如下代码:
import tensorflow as tf
print(tf.__version__)
mnist = tf.keras.datasets.mnist
(training_images, training_labels) , (test_images, test_labels) = mnist.load_data()
training_images = training_images/255.0
test_images = test_images/255.0
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy')
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])
把 Dense的神经元个数从512设置到1024有啥影响?
- 1. 更长的训练时间,精度有所提升;
- 2. 更长的训练时间,精度没有提升;
- 3. 一样的训练时间,精度有所提升;
3. 训练3
如果移除Flatten 神经层,会发生什么?
model = tf.keras.models.Sequential([#tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
出现错误:logits and labels must have the same first dimension
4. 训练4
如果最后一层的神经元个数设置为5会怎么样?
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dense(5, activation=tf.nn.softmax)])
出现错误: Received a label value of 9 which is outside the valid range of [0, 5)
5. 训练5
如果添加多一层隐含层会怎样?
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
添加多一层,并不会增加正确率,因为数据比较简单,后续如果使用复杂的数据,那么增加层数可以提高准确率。
6. 训练6
改变训练步数(epochs)会有什么影响?
参考:过拟合、欠拟合。
7. 训练7
去掉归一化过程,结果会怎样?
8. 训练8
在前面的练习中,如果过拟合,可能会出现正确率上下波动的情况,直到到达训练步数。是否可以编写代码,使得当正确率满足一定情况时,直接退出,而不用等待运行步数?
可以使用CallBack 策略
import tensorflow as tf
print(tf.__version__)
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('loss')<0.4):
print("\nReached 60% accuracy so cancelling training!")
self.model.stop_training = True
callbacks = myCallback()
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images=training_images/255.0
test_images=test_images/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
model.fit(training_images, training_labels, epochs=5, callbacks=[callbacks])
3. Callback提前退出
在模型训练时,有时模型到一定epoch后,其正确率就不会再提升,但是由于设置了epochs,那么程序还是会继续运行直到设置的epochs,是否有种策略可以在适当的时候终止训练?
可以使用CallBack策略,通过两种方式来进行中断:
- 使用 loss 来判断,参考上面 训练8;
- 通过acc来判断,如下:
class myCallback1(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('loss')<0.4):
print("\nReached 60% accuracy so cancelling training!")
self.model.stop_training = True
import tensorflow as tf
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('acc')>0.6):
print("\nReached 60% accuracy so cancelling training!")
self.model.stop_training = True
mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
callbacks = myCallback()
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, callbacks=[callbacks])
4. 测试
- 第 1 个问题
What’s the name of the dataset of Fashion images used in this week’s code?
- a.Fashion Tensors
- b.Fashion MNIST
- c.Fashion MN
- d.Fashion Data
- 第 2 个问题
What do the above mentioned Images look like?
- a.28x28 Greyscale
- b.28x28 Color
- c.82x82 Greyscale
- d.100x100 Color
- 第 3 个问题
How many images are in the Fashion MNIST dataset?
- a.10,000
- b.60,000
- c.42
- d.70,000
- 第 4 个问题
Why are there 10 output neurons?
- a. There are 10 different labels
- b. To make it classify 10x faster
- c. Purely arbitrary
- d. To make it train 10x faster
- 第 5 个问题
What does Relu do?
- a. For a value x, it returns 1/x
- b. It returns the negative of x
- c. It only returns x if x is less than zero
- d. It only returns x if x is greater than zero
- 第 6 个问题
Why do you split data into training and test sets?
- a. To test a network with previously unseen data
- b. To train a network with previously unseen data
- c. To make training quicker
- d. To make testing quicker
- 第 7 个问题
What method gets called when an epoch finishes?
- a. on_epoch_finished
- b. on_epoch_end
- c. On_training_complete
- d. on_end
- 第 8 个问题
What parameter to you set in your fit function to tell it to use callbacks?
- a. callback=
- b. oncallback=
- c. callbacks=
- d. oncallbacks=
my guess:
1. b
2. a
3. d
4. a
5. d
6. a
7. b
8. c
5. 实战
要求: 编写一个Mnist 数据分类器,需要得到99%+的正确率,同时需要当模型得到99%+的正确率后停止训练。
注意:
- epochs设置为10就可以了,不用设置超过这个值就可以达到99%的正确率;
- 当达到99%+的正确率时,需要打印“一刀满级99+,停止训练!”;
- 如果有新定义变量,建议和课程中的变量保持一致。
以下是提示代码:
# YOUR CODE SHOULD START HERE
# YOUR CODE SHOULD END HERE
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
# YOUR CODE SHOULD START HERE
# YOUR CODE SHOULD END HERE
model = tf.keras.models.Sequential([
# YOUR CODE SHOULD START HERE
# YOUR CODE SHOULD END HERE
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# YOUR CODE SHOULD START HERE
# YOUR CODE SHOULD END HERE
答案: link