Cloudera技术堆栈中构建近实时系统的组件
五种最常用的组件使得这一技术成文可能
• Apache Kafka
• Apache Flume
• Apache Spark
• Apache Kudu
• Apache Impala
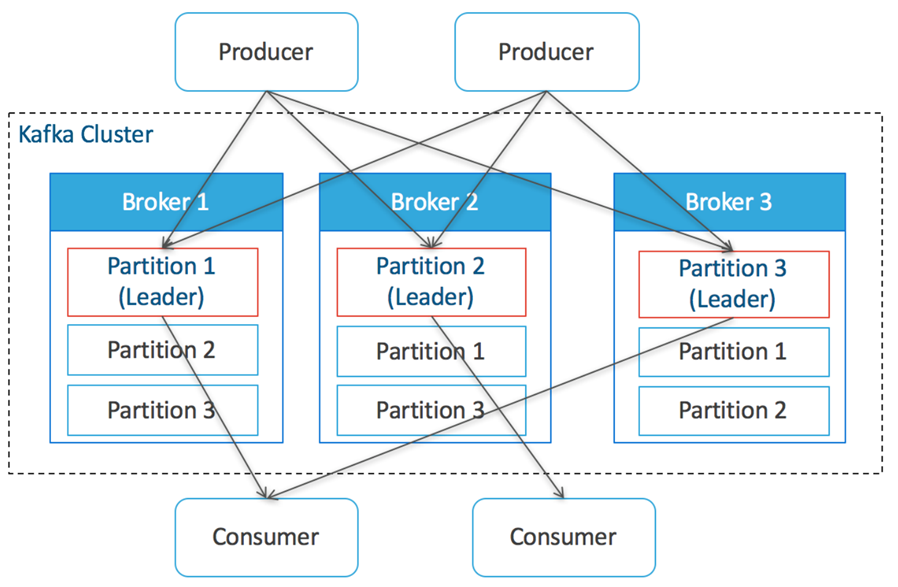
Apache Kafka
- 每个节点成为Broker
- 数据的topics方式写入kafka
- 每一个topic都可以被分片
- 分片分布在broker上
- 分片可以有多个副本,其中一个为leader
-
Producer,Consumer都与partition直接进行数据交换
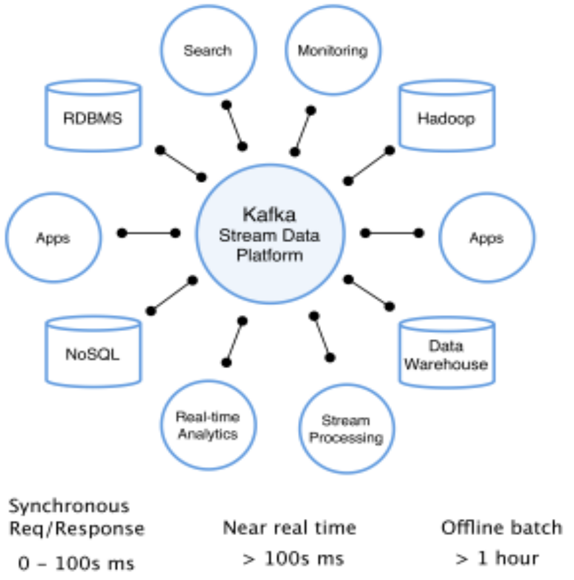
Kafka应用场景
-
Kafka具有消息持久化、高吞吐、分布
式、多客户端支持、实时等特性
-
适用于离线和在线的消息消费,如:
• 常规的消息收集
• 网站活性跟踪
• 聚合统计系统运营数据(监控数据)
• 日志收集
• 其它大量数据的互联网服务的数据收集场景
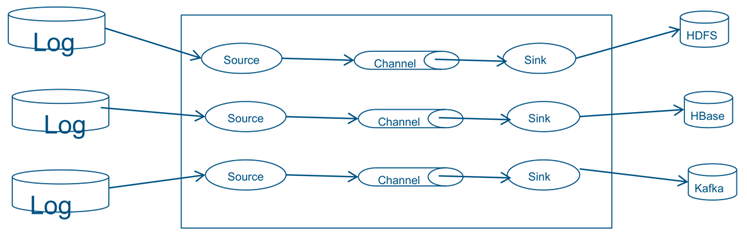
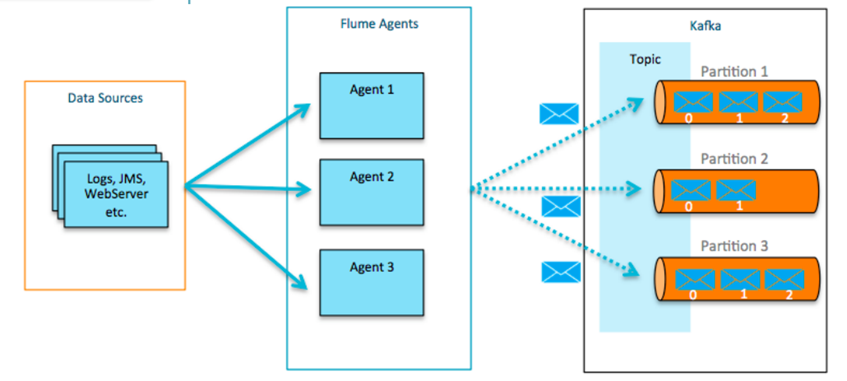
Apache Flume
实现Log & Event 的聚合
-
高效的注入海量streaming/log 数据
• 从多种系统(sources)获取数据,并写入到多种目标系统
• 内建 sources, sinks, 及channels,开发集成简单
• 定制化的工作流可以用来快速转换数据
-
可靠的、高效的、可扩展的能用于生产系统的工具
• 可以使用Cloudera Manager进行集中的管理和监控
Flume应用场景
• 日志采集室Flume的主要应用场景,和其他日志采集工具相比,Flume最大的优势是?供了大量现成的Source和Sink,用户只需要简单的配置即可实现日志采集和加载的工作
Kafka + Apache Flume
• Kafka 可以被配置为 Flume 的Channel
• Flume Sources 和 Sinks 可以配置成Kafka的Consumer和Producer
Flume Sources Consume fromKafka:Write data to HDFS, HBase, or Search
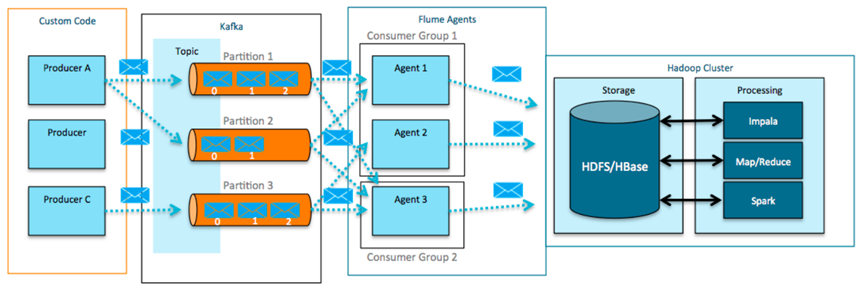
Flume Sinks 把书架写入Kafka:读取logs, files, jms, http, rpc, thrift 等数据源并把事件数据写入到Kafka
Spark Streaming
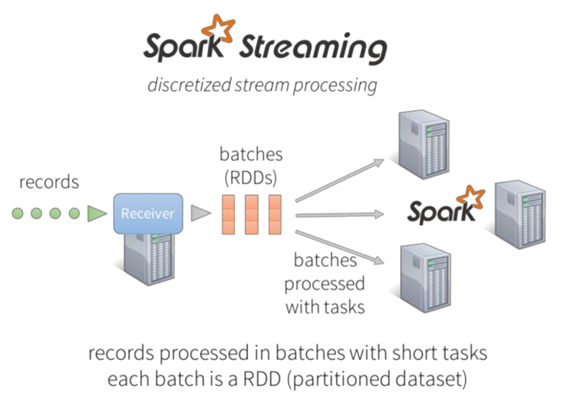
• Spark Streaming接收实时的输入数据流,然后将这些数据切分为批数据供Spark引擎处理,Spark引擎将数据生成最终的结果数据。

• 使用DStream从Kafka和HDFS等源获取连续的数据流,Dstreams由一系列连续的RDD组成,每个RDD包含确定时间间隔的数据,任何对Dstreams的操作都转换成对RDD的操作

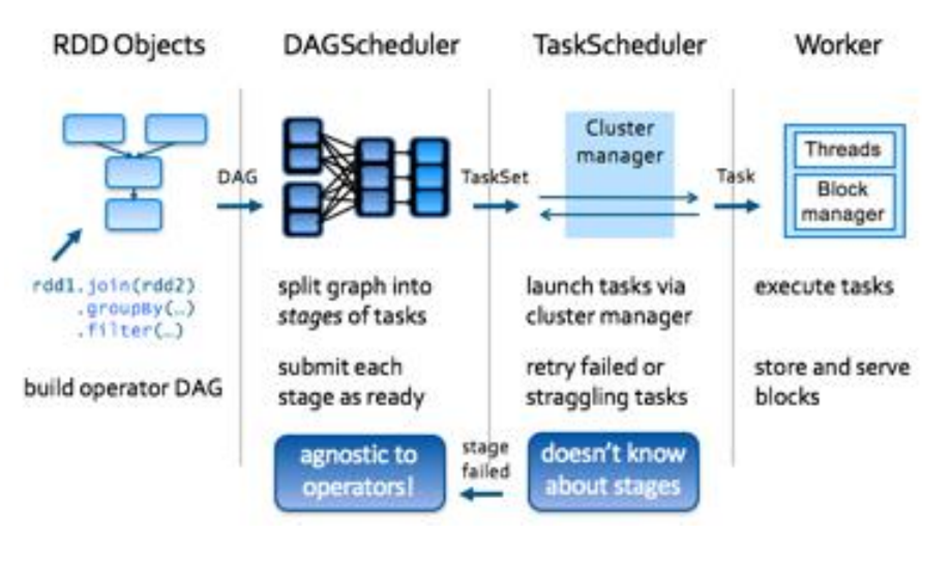
Spark streaming容错性以及可靠性
Spark streaming 依赖spark的调度架构
• Task失败之后可以重新运行
• 数据源接收之后会多备份一份
• 实现exactly-once
• 不能确保顺序执行
Spark Streaming优势
Spark Streaming的优势在于:
• 能运行在100+的结点上,并达到秒级延迟。
• 使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
• 能集成Spark的批处理和交互查询。
• 为实现复杂的算法提供和批处理类似的简单接口。
Spark Streaming 支持的业务场景
目前而言SparkStreaming 主要支持以下三种业务场景无状态操作:
• 只关注当前的DStream中的实时数据,例如 只对当前DStream中的数据做正确性校验
• 有状态操作:对有状态的DStream进行操作时,需要依赖之前的数据 例如 统计网站各个模块总的访问量
• 窗口操作:对指定时间段范围内的DStream数据进行操作,例如 需要统计一天之内网站各个模块的访问数量
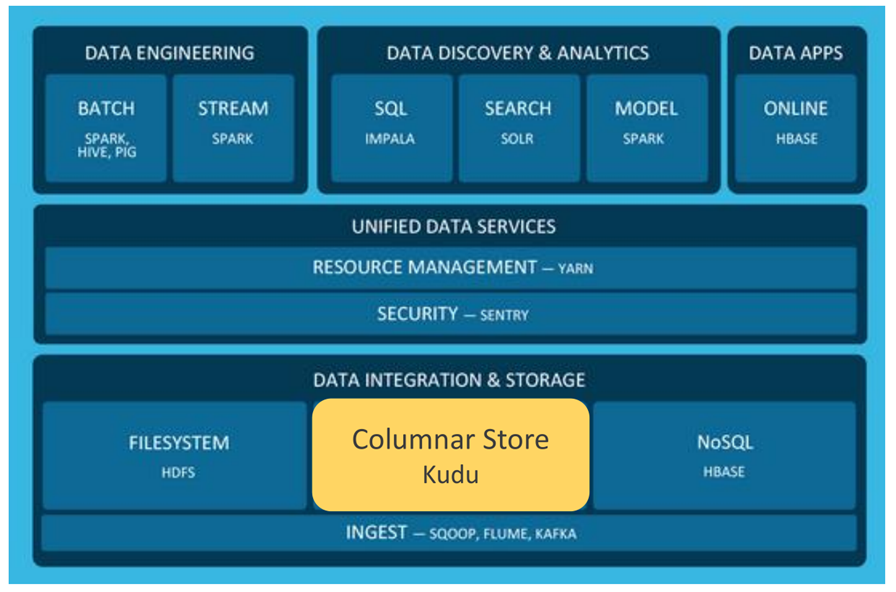
Apache Kudu
kudu是高效分析快数据的存储格式
• Hadoop平台支持数据修改的新的列式存储格式
• Apache许可,100%开源
• 当前为Beta版本,2016年一季度GA
硬件行业的进展
机械硬盘 -> 固态硬盘
• NAND 闪 存:读数据时IOPS达到45万个,写数据时IOPS达到25万个,读数据的吞吐率约为每秒2GB,写数据的吞吐率达到每秒1.5GB, 存储成本低于每GB3美元并且持续下降
• 3D XPoint memory (比NAND快1000倍, 比RAM更有成本优势)
内存成本更低,单机内存量更大 :
• 过去几年64->128->256GB
• 启示 1: CPU 将成为性能瓶颈,当前的存储系统设计时并没有考虑高效使用
CPU.
• 启示 2: 列式存储也可以用于随机访问
Kudu的设计目标
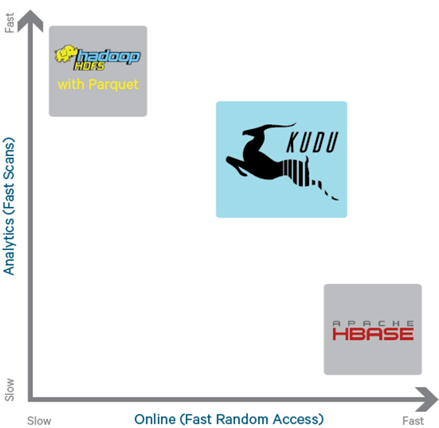
扫描大数据量时吞吐率高(列式存储和多副本机制)
目标 : 相对Parquet的扫?性能差距在2x之内
访问少量数据时延时低(主键索引和多数占优复制机制)
目标 : SSD上读写延时不超过1毫秒
类似的数据库语义(初期支持单行记录的ACID)
关系数据模型
• SQL查询
• "NoSQL"风格的扫?/插入/更新(Java客户端)
Kudu的使用
-
类似SQL 模式的表
• 有限的列数 (不同于HBase/Cassandra)
• 数据类型: BOOL, INT8, INT16, INT32, INT64, FLOAT, DOUBLE, STRING, BINARY,TIMESTAMP
• 一部分列构成联合主键
• ALTER TABLE快速返回
-
"NoSQL" 风格的 Java和C++ APIs
• Insert(), Update(), Delete(), Scan()
-
与MapReduce, Spark 和Impala 的无缝对接
• 将对接更多处理引擎!
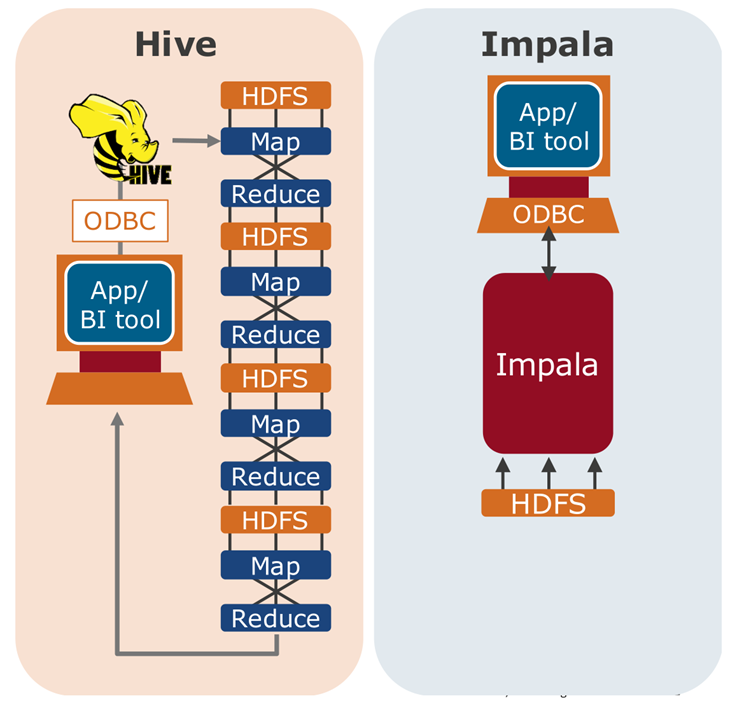
Impala简介
-
Impala是高性能的MPP SQL引擎,支持超大数据集
- 大规模并行处理架构(MPP)
- 秒级低延迟查询响应速度
-
Impala运行在Hadoop集群之上
- 直接写入/查询存放在HDFS或者HBase中的数据
- 支持通用的Hadoop文件格式
-
由Cloudera公司开发
- Apache子项目,100%开源
Impala特点
- Impala SQL直接在Hadoop集群上执行,不依赖底层的通用计算引擎,例如MapReduce
- 针对查询进行优化,基于成本的执行优化器支持多用户并行访问,以及多种不同类型的工作负载
- 支持通用的Hadoop文件格式,包括Parquet, ORC, Sequence File等
- 和Hadoop管理模块有很好的集成,包括元数据管理,安全整合等
Impala主要应用场景
主要适用于分析型应用,数据探索以及交互式自助查询/分析
运营KPI 仪表盘
案例: 医疗保险
业务场景:
• 可视化展现当前医院各项话费指标以及历史趋势
• 集成并整合了1000+医院的系统数据
效益:
• 支持大规模数据处理,允许用户查询历史数
据以及下钻到更细粒度数据
• 节省了传统数据库许可证的费用
• 更好的查询性能
实时SQL 数据探索
案例: 银行
业务场景:
• 发现内部/外部的欺诈行为
• 分析内外部系统的应用/web日志
效益:
• 支持对非结构化数据的分析
• 使用现有的BI工具
• 使用现有Hadoop继续,无需搬迁数据到外部的数据库系统