一.变量(*******)
1.什么是变量
量:衡量/计量/记录某种状态
变:记录下的某种状态是可以发生改变的
变量相当于一个容器,记录事物的状态
2.为何用变量
为了让计算机识别各种事物,为了让计算机具有人记录并且识别事物状态的技能。
3.怎么用变量
变量的使用必须遵守先定义后引用的原则
变量的三大组成部分:
变量名:是访问到值的唯一方式,指向变量值,变量是反映事物的属性或者特征。
赋值号:将值的内存地址"赋值"给变量名,也就是将变量值和变量名关联起来。
变量值:事物某种状态。
变量的是通过变量名引用。
变量名的大前提:变量名应该见名知意,能够清楚的表达事物的某种属性
变量值具有三种特征:
id:是变量值在内存中唯一标识(是根据内存地址计算而来)
type :不同类型的值是用来记录不同的状态
value:变量值
4.变量名的命名规范:只能是数字,下划线,字母的组合
不能用数字开头,不能用特殊符号,不能与内置变量名冲突
5.变量名风格包括:
驼峰体:TarryCode 类的命名推荐使用驼峰体
下划线体:tarry_code,变量名推荐使用下划线体
常量:不变的量
用全大写表示常量,默认的常量书写规范。
6.type() 查看数据类型
7.python的内置垃圾回收机制:
在python中,没当一个变量名被引用的时候,会生成一个引用计数,表明该变量名被引用的次数,当引用计数为0时,会自动断开与变量值内存地址的关联关系,
由于变量名是访问变量值内存地址的唯一方式,所以当变量名与变量值没有关联时,会自动将这个变量名对应的值回收,这也就是垃圾自动回收机制
8.变量值的三个特征:
1.id:变量值的唯一编号,内存地址不同id则不同。
2.type:类型
3.value:值
9.身份运算:is
10.bool值:除了0,None,空的bool为False之外,其余的都为True.
11.逻辑运算:
or:多个条件满足其中一个就成立
and:多个条件必须同时满足
12.小整数池的概念:
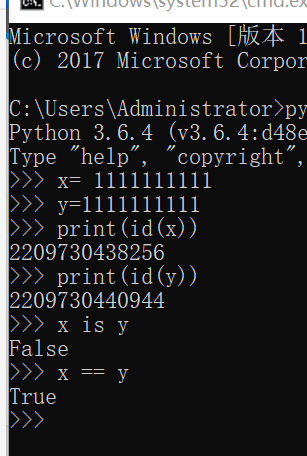
在Python中将数字【-5,256】之间的数字放入一个小整数池中,为了减少内存的使用量,在pycharm中的小整数池的范围更大。
二.数据类型:数据类型就是不同的变量值的数据类型
数据类型的不同为了记录不同的事物的属性,如年龄→int,名字→字符串等
有以下数据类型:
1.数字类型:int,float
int:整数型 1,2,3等
float:浮点型 1.12,2.34等
2.字符串:
1>:什么是字符串:字符串就是由一些字符构成的数据类型,在单引号,双引号,三引号中的就是字符串。
2>字符串的使用方法:str是字符串类,里面存放了字符串的调用方法。
.rjust():居右填充
.center()居中填充
.ljust()局左填充
.split():分割
.strip()去空
.rstrip()右边去空
.lstrip()左边去空
.count()判断个数
.expendtabs():将\t转换成空格,可以自己定义,最少定义成4个空格,默认是8个空格
.join()将列表中的元素以某个字符相连,如 list1= ['a','b','c'] ‘*’.join(list1) = a*b*c,相比字符串的+相连节省内存空间。
.format():重点
三种用法:
<1>:'{0}{1}{2}'.format(name,age)
<2>:'{name}{age}{sex}'.format(name='yuan',age=18,sex=male)
<3>:'{name}{age}{sex}'.format(name:'yuan',age:18,sex:male)
.find():返回字符串是否找到,找到返回字符的索引,找不到返回-1,不会报错,
.index():返回字符串是否找到,找到返回字符的索引,找不到报错
.zifll(width):右对齐,在字符左边填充0,width大于字符长度,才会补充0
.casefold():将所有大写转换成小写
.swapcase(self):将大小写互换 如 : ‘aAc’ → ‘AaC’
.capitalize():首字母大写
.endwith():以什么开头
.startwith():以什么结束
3>.[]切片
[开始,结束,步长] :特点,顾头不顾尾
[::-1]以步长1从后面开始取,
4>.len()函数:返回对象的长度。len(object)
3.list:列表:可以记录多个值,是有序的数据类型
1.增:
append() 在末尾添加
extend() 将一个列表循环添加到列表中
inster(index,object) 按照索引位置添加元素
2.删
del () 按照索引 如 del l[1]
pop() 删除 按照索引 l.pop(index)
remove(self,object) 按照对象删除
3.改
l[index] = new_value
l.copy() 复制
4.查
index()
.reverse() 列表翻转
.count() 元素的个数
.sort(self,key=,reverse=False) key对应的是排序的全值,比如列表中的元素按长度排序,sort(key=len(),reverse=False)
reverse默认的升序排序,reverse=True是降序排序
.clear() 列表清空
4.元祖 touple 元祖和列表对比来说就是一个不可变的列表,用法类似,可用for循环
.index() 索引
.count() 计数
元祖里面的元素是不可改变的,是不可变数据
5.字典 dict= {key:value}
字典是有一个键值对构成的,一个key对应一个value
字典里面的keys是可以进行for循环的,是有序的。values是无序的,key是取到value的唯一方式
item对应的是dict的键值对
增:dict = {} 通过定义去增加元素
d.setdefault('key':value) 如果原先字典中没有该key对应的值,则添加该键值对,如果有则不对字典中该key的值进行修改,还是返回原先的值
删:
.pop()按照key取删除
.popitem() 随机删除字典中的键值对
改:根据定义来修改
查:d{'key'}
d.clear()清除
d.copy()复制
d.fromkeys(object,default_value) 返回一个新的字典,并且所有key对应的值都相同
l= ['name','age','sex']
d= dict.fromkeys(l,123)
print(d)→
{'name':123,'age':123,'sex':123}
d.get()获取key的value,取不到返回None
d.keys() 所有的keys
d.update(dict1) 更新 将d更新成dict1,如果d中的key与dict1中的key相同,则将dict1中key的值赋值给d中key对应的值,如果没有,则在d中添加该键值对
d.values()查看字典所有的key对应的值
6.集合 set:
s = {1,2,3,4}
set是可变的数据类型
set内的元素是不可变的数据类型
集合:关系测试,天然去重,无序去重的
{} 没有值就是set
交集, 两个都有
差集合,在列表A里有,B里没有
并集 把两个列表里的元素合并在一起,去重
交集:linux.intersection(python) linux & python 效果一样
差集:linux.difference(python) linux - difference 效果一样
并集:linux.union(python) linux | python 效果一样
反向差集(对称差集)
linux.symmetric_difference(python) 两个都没有的一起打印
linux ^ python 效果一样
判断子集:linux.issubset(python) 判断linux是不是python的子集 < 效果一样
判断父集:linux.issuperset(python) 判断linux是不是python的父集 > 效果一样
判断两个集合的关联性:linux.isdisjoint(python) 有关联 return true ,else false
增:
union 只会求一个集合,不会改原来的set update 会把原set改变