一、问题简述与类的设计
本单元作业一共分为三次,主要任务为多项式求导,第一次仅要求对非复合的幂函数多项式求导,第二次增加了正弦余弦的函数形式依然会出现复合,第三次则允许函数复合。要求程序在任何输入情况下都不会崩溃,且能正确识别出用户输入是否合法,对合法的输入输出尽量短的求导结果,对不合法的输入输出WRONG FORMAT。
首先整个程序的运行需要主控类,负责实现输入、输出、求导的过程控制。主控类能够把用户输入的字符串转化为内部的存储结构,而这个存储结构是由类实现的。经过对表达式的分析,以及编译技术学到的文法知识,不难发现,表达式由项构成。
在第一次作业中,项的组成成分单一,所以表达式和项足以应付所有情况,并且输入输出可以直接在表达式类中一次性完成。
第二次作业虽然加入了新的函数类,但是考虑到他们对求导运算封闭,所以其实每个项可以写成一个a*x^b*sin(x)^c*cos(x)^d的形式,因此我依然没有创建因子类,我只需要对每个项维护好abcd四个系数即可。
第三次作业中,嵌套的出现,每个项彻底失去了统一性,所以必须要增加因子类,而因子有很多种,按照其种类,可以分为三个子类:幂函数子类、正弦函数子类和余弦函数子类。随着情况的复杂,对于对象的构造和输入的处理也不能一次完成,所以把对于输出输出的分析分发到各个类的构造函数中,求导过程也要如此。而且为了避免递归下降子程序分析的麻烦,我对字符串进行特殊处理,维持了正则表达式的使用。
综上,我一共有主控类、多项式类、项类、因子类,而因子类作为父类有幂函数子类、正弦函数子类和余弦函数子类。
二、核心点详细设计
2.1 对输入的处理:一以贯之的正则表达式
在我的多项式类中,有一个构造方法,其主要作用是输入字符串进行分析并转化为数据结构。前两次作业中,利用正则表达式,我们都能够很轻松的把识别并提取用户输入,而第三次作业,因为有了嵌套,正则表达式遇到了一些困难。困难在于正则表达式的匹配过程不能正确的识别括号。比如,如果输入为sin((1+x)) + cos(x),因为sin的内部可以嵌套,我们首先想到的是利用类似sin\\(.+\\)的正则表达式去匹配,但是这样的话会误把"(1+x)) + cos(x"认为是sin括号内部的内容。
很多同学提出使用编译技术中学到的递归下降子程序,这样确实可以解决这个问题,但是,就不能使用正则表达式这套强大且出错率更低的工具,并且递归下降的每个位置都会出现if-else分支结构,大量的分支嵌套结构也无疑增加了代码的复杂性,降低了可靠性。所以在我看来实为下策。
那么应该如何解决这个问题呢?我从计算机网络中学到的数据帧结构得到了灵感:数据帧会使用特殊符号标记边界(以0x7D为例),但是,如果0x7D出现在了数据帧包含的数据中,可能就会错误地把数据中的0x7D当成是帧的边界,为了解决这个问题,网络中把数据里的特殊字符进行转义处理,使得数据中永远不会出现0x7D,实现和边界符号的区分。这和我们面临的情景十分类似,我们之所以不能正确的使用正则表达式匹配括号,就是因为内部的括号和边界不能正确区分,如果能够将其区分开,就能使用正则表达式了,所以,只需要把最顶层的括号进行替换,区分开不同的括号,就能正确匹配。比如,前面所说的sin((1+x)) + cos(x)吧顶层括号替换,得到sin#(1+x)# + cos#x#,而正则表达式则对应修改为sin#[^#]#和cos#[^#]#,就实现了对顶层和下层的区分,而内层的字符串则可以递归下降继续按照相同的方式处理,递归出口为括号内为x或数字的时候。这里还需要注意一个细节,就是在进行匹配之前,必须要先排除#的存在,否则,如果用户了sin#(1+x)#,你本来应该报错,现在却能求导,这类错误应该避免。
采用这样的方法,我的输入输出改动并不大,从第一次作业到第三次作业,我对输入的处理一脉相承,唯一的改动只是把字符串处理的位置移动到了各个类的构造方法里,但是对于代码逻辑始终没有较大变更,重构起来十分简单,避开了递归下降子程序分析。

2.2 递归在数据结构上的体现:更强大的定义
递归定义的出现要求我们类的设计也必须是递归的。为此,我在因子类中增加了一个名为content的属性,其类型为多项式,也就是说,对于那些三角函数因子中为x的部分比如sin(x)的x,cos(x)的x,可以替换成一个表达式,对于课程没有要求的x^a的形式,一样可以允许嵌套。但是这里需要注意一个问题,就是表达式必须在左右两侧有一对括号变成因子的情况下才合法,即sin(1+x)不合法,sin((1+x))才合法。针对这种情况,在因子类的构造方法中必须专门进行判断。
看起来,这样的定义方式和指导书中对表达式的定义并不完全吻合,毕竟我没有专门的常数因子和多项式因子,常数的问题我直接放在term类中方便合并。而我并没有直接定义表达式因子,而是以一种更数学的视角进行了递归定义,即对因子加入content属性,允许所有的因子都进行递归下降。这样,其实我所支持的求导种类要比指导书中定义的多,比如,我能够支持形如(1+x)^2的求导,而且扩展性更强,如果新增函数种类,除了输入输出的修改之外,我只需要新建一个子类,重写求导方法就能实现。因为我的定义是基于数学的,允许任何形式的函数向下递归,而没有单独对多项式因子新建一个类。
不得不承认,这一块重构的力度还是相当大的,特别是从第二次到第三次作业,递归的加入对整个体系的设计改变很大,我需要重新定义各类求导返回值的类型,增加新的属性。但是一旦完成了这次改变,会发现可以很轻松的拓展到对整个基本函数集合的求导。所谓基本函数,是由包含了指数、对数、幂、三角、反三角函数的基本初等函数经过四则运算和复合运算构成的函数。
2.3 求导过程的实现:多态与分解
第一次作业的时候,完全没有因子的概念,我直接在项类中定义了指数、系数的属性,并且定义了求导方法。而在第二次作业时,虽然出现了新的函数,并且可以相乘,但是为了维持先前的架构,我依然没有创建项这个类,因为我发现幂函数族和三角函数族对求导运算是封闭的,正弦函数求导的结果恰好是余弦函数,所以a*x^b*sin(x)^c*cos(x)^d,所以整个函数空间其实只需要四个维度即可确定,我当时充分利用这个特点,所以第二次作业并没有太大改动,也没有留好拓展余地,所有的求导混在一起。前两次作业的求导虽然也是一种逐层分解的形式,即主控类调用多项式的求导方法,多项式会调用项的求导方法。但是求导方法相对固定。
直至第三次作业,逼迫自己进行了大换血,新增类,重构求导方法。多项式调用每个项的求导方法。每个项调用因子的求导方法。因子的求导方法会根据其所属的子类而执行不同的求导方法,实现了分解会多态化的结构,使得求导彻底实现了可扩展性。
三、基于度量的程序结构分析
分析工具采用了IntelliJ IDEA中的UML插件以及课程组推荐的开源度量工具DesigniteJava。为不影响阅读体验,仅放出第三次作业的度量结果。
3.1 规模分析
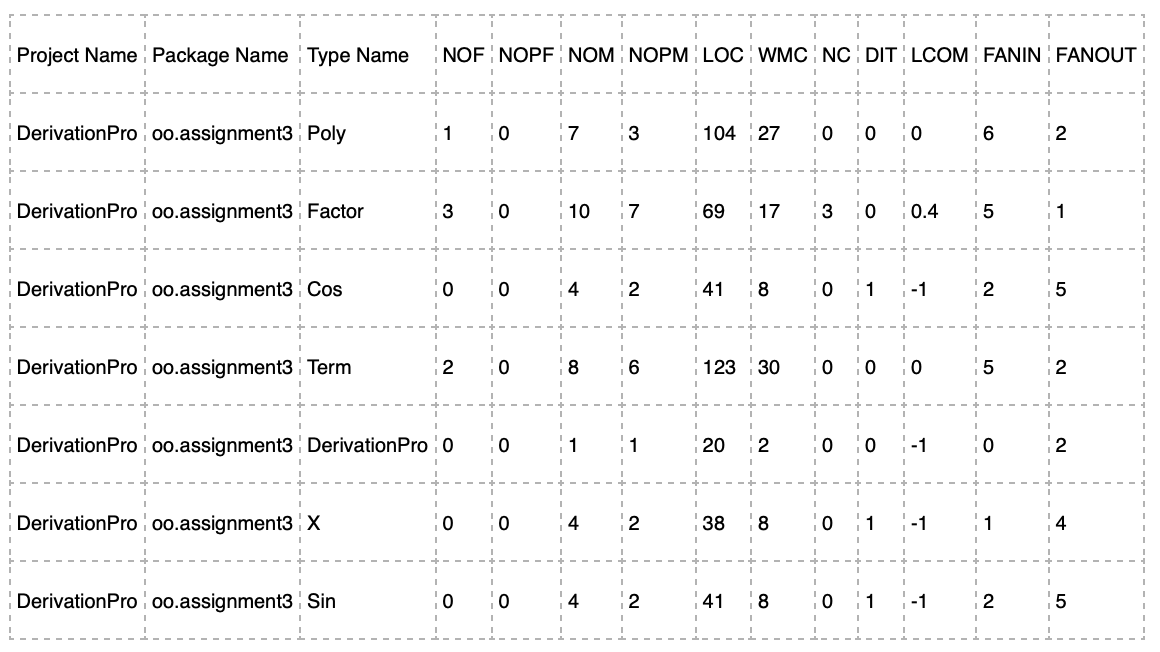
代码长度:
先看总代码。可以发现,第三次作业是最复杂的一次,代码规模总共只用436行,非常精简。当然,即使这样依然有提升空间,我本可以使用protected关键字进行修饰,这样Factor父类还能进一步减少诸多不必要的get方法。
再看每一个类的代码量,可以看到最长的类Term类有123行,整体来说都不超过130行,也是很精简的类了。
类复杂度分析:
我一共设计了7各类,每个类的属性数量都很少,子类甚至没有属性。而每个类的方法也都不超过10个,其中Factor和Term类的方法虽然接近或达到了10个,也是因为有很多set或get这样的简单方法,所以每个类的规模其实都很小。
接下来看每个类中的方法复杂度。
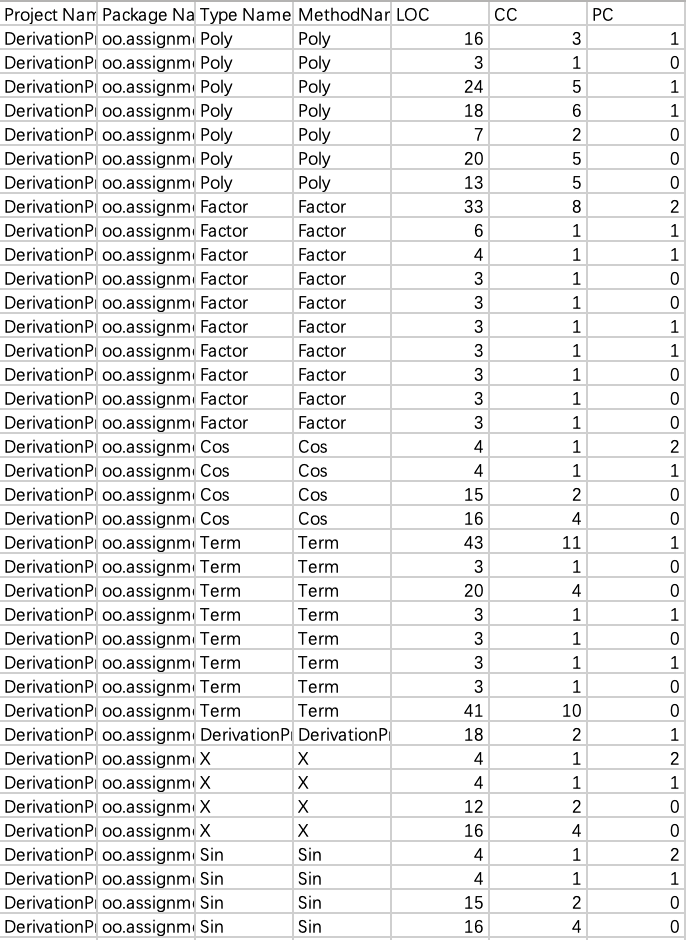
一共有38个方法(方法名总是和类名一样,可能是分析工具有个小bug)。每个方法的代码长度不会超过50行,在圈复杂度的控制方面,有些方法做的不好,超过了10,这意味着为了保证里面的逻辑正确至少需要10次以上的不同测试。这些方法都Term类里面,分别是Term的构造方法和toString方法,造成复杂度过高的原因主要是出现了if-else的双层嵌套,为了降低圈复杂度可以考虑把内层逻辑单列成为新的方法。而方法的参数个数控制很好,全部不超过两个。
3.2 内聚耦合分析
类内聚合度的指标可以用LCOM来评价,在第一张图中,有各个类的LCOM。LCOM的定义有很多,比较易于理解的是:一个属性也不重叠的方法的对数 - 至少一个属性重叠的方法的对数,这样看来,我的类内耦合度较高,但是因子类Factor达到了0.4,这可能是因为子类要重载父类的方法,所以我在父类定义的方法很随意,造成内聚度较低,应该把子类方法中共性的部分提取作为父类方法进行改进。
类间耦合度可以使用扇入和扇出指标进行评价。通常的设计规范要求高扇入而合理扇出,高扇入说明这个模块被很多其他模块调用,说明这个模块提炼出了其他模块的共性,合理扇出说明不希望每个模块调用太多其他模块(一般在3~4个),否则其他模块的修改会引发它本身的修改。按照这样的考核指标来看,Sin和Cos子类扇出稍高,原因有二。一是因为Sin和Cos求导会产生对方,所以调用了对方的构造方法,还因为我把系数直接放在了Term类里,所以求导产生的系数必须调用Term类的setCoef进行设置,第二个原因是出现嵌套,所以调用了多项式类的方法。一般来说出现扇出过高的解决方法是通过增加中间函数,但是对于一个仅400行的程序来说实无必要。
3.3 类图的绘制与评价
第二次和第三次作业的类图对比,可以看到两者差异很大,也说明重构的力度很大,第二次作业完全没有预测未来需求的走向,加上确实不知道如何从有限的需求进行高度抽象,所以其实不会扩展。这导致两次类图之间的差异很大。
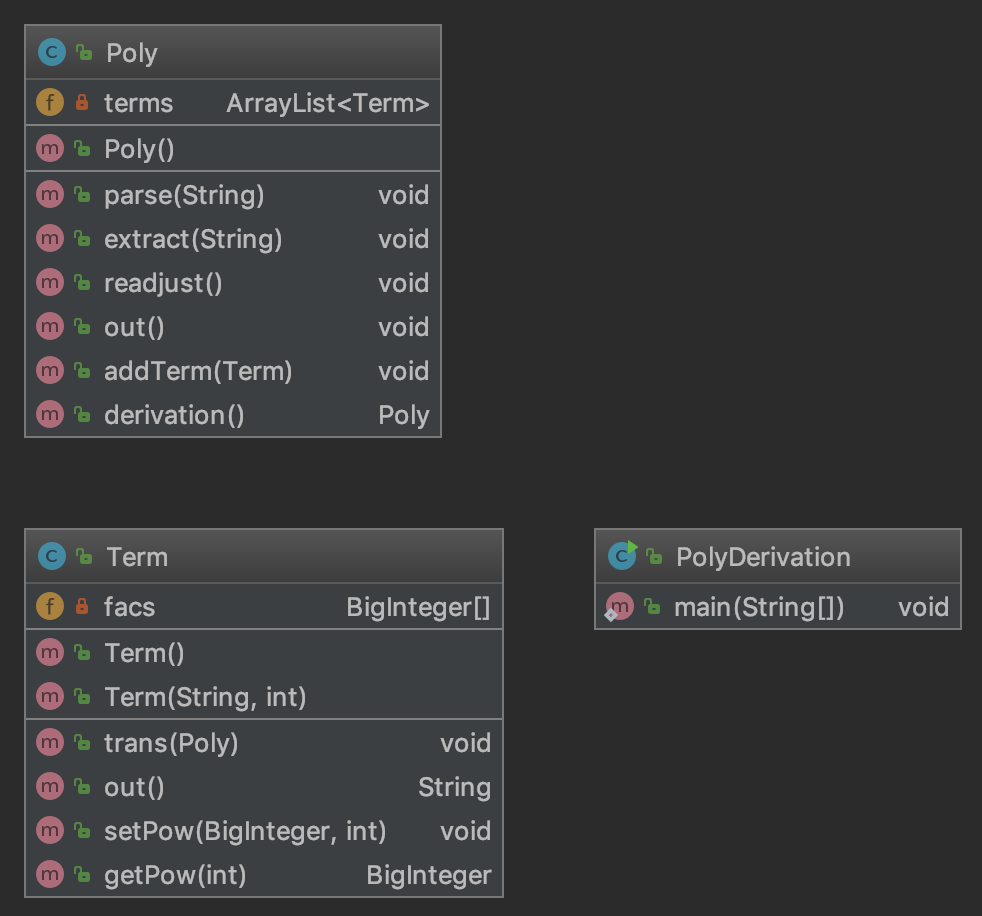
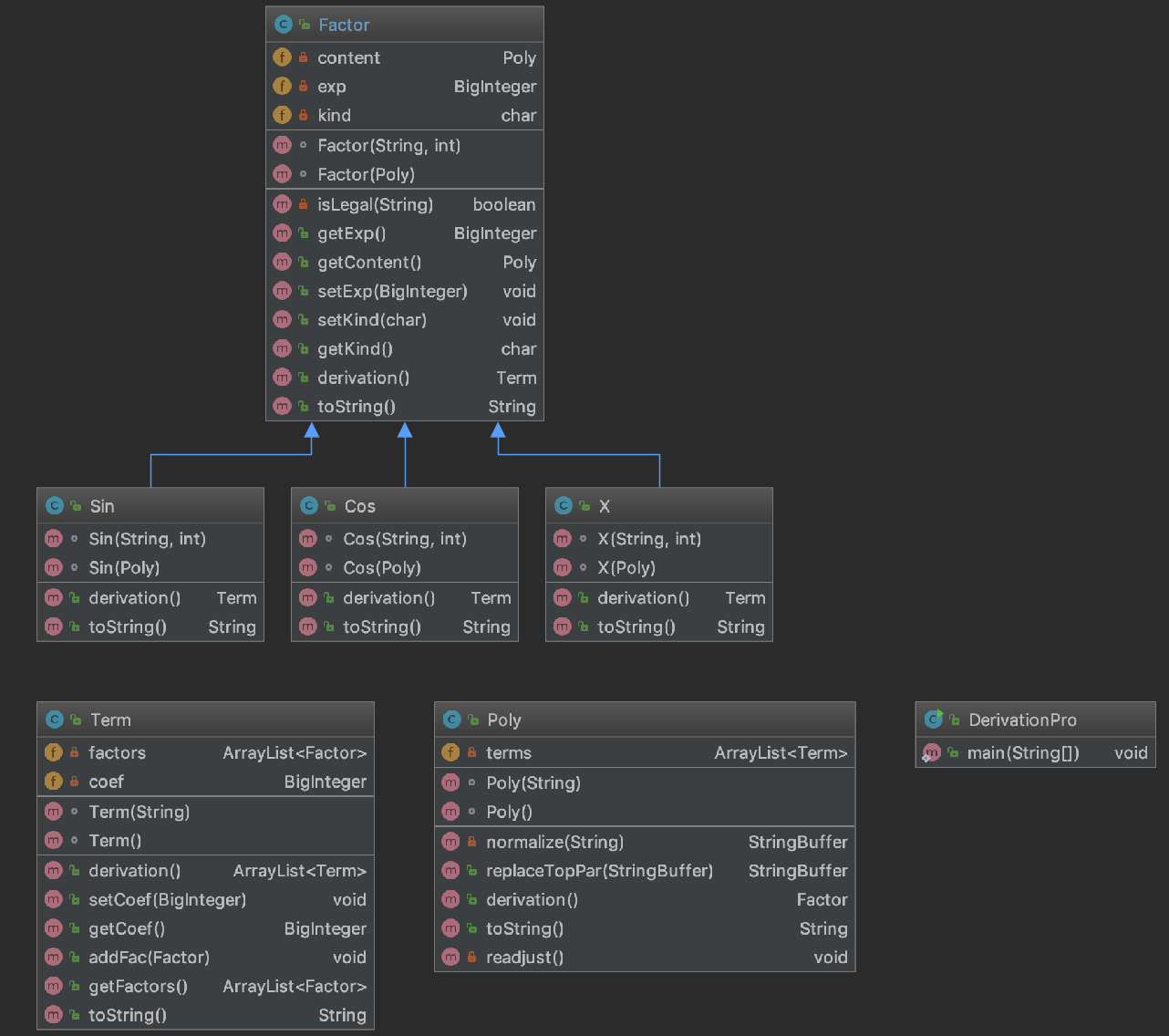
四、Bug分析策略
首先是手动测试,手动测试的时候,我加入了死循环,并且使用IDEA中Run with Coverage的模式运行,这个模式的好处是可以在结束运行之后告诉你各段代码时否被覆盖,这种方法简单快速,而且能让你迅速有针对地把所有代码执行一遍,甚至可以起到简化代码的作用。我在第一次作业中使用这种方法,发现有几处代码无论如何也覆盖不上,后来仔细分析了一下,是因为x无论如何不会成为一个求导的结果,所以那里的逻辑组合系数和指数都是1这个分支其实永远不会进入,所以我果断删掉了这个分支。当然这个方法存在致命问题,为了测试我不得不修改已经写好的代码,这样测完了如果没改回来,就可能造成致命风险,比如卡评测。
之后是自动化测试,对于正确的用例,我写了一个python脚本,可以根据正则表达式,生成目标表达式,在使用python中subprocess指令,调用自己的java程序,识别控制台输出,然后使用python的sympy进行求导,计算。这个方法最大的好处是真正实现了黑盒测试,把需要测试的代码使用子进程的方式启动,利用管道获取控制台输出。但是问题也很明显,就是随机生成的用例往往没有针对性,而且因为正则表达式太复杂,稍微长一点的表达式,生成和计算都需要很长时间,而且还很容易超出计算限制。不过,这个方法至少实现了大量测试,在一定程度上确保程序的正确性。
对于错误情况分析,则比较难,理论上,只要正则表达式是正确的,看起来对于所有错误都会输出WRONG FORMAT!。所以核心是建立正确的正则表达式分析方法,借助编译技术中学习的语法分析方法,从语法树分析,按照DFA分析,最终得到的正则表达式不会出问题。
五、构建模式
创建型模式是三大设计模式之一,另外两种为结构型模式与行为型模式。
创建型模式一共分为五种模式:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
其中工厂模式应该是适合本次作业的一种模式。因为我现在代码中最大的问题就是构造方法很长,而且几乎每个类都是如此,因为构造方法要完成对输入的字符串的分析,同时提取其中的信息。这样复杂的构造方法违背了面向对象的原则,而且更致命的地方在于,多项式类和因子类的构造方法有一段代码是几乎重复的。所以可以使用工厂模式,专门建立工厂类,实现对这些对象的生产。
六、总结感悟
第一次作业之后,对正则表达式,java语言和面向对象有了初步认识。在编程过程中一直坚持设计先行的原则,感受抽象封装继承的特点。并且使用了自动化测试的手段。
存在的问题是,对于单元测试还没有掌握,对于需求缺少前瞻性,导致重构量很大。这些都是经验积累,非一日之功,先树立意识,不断总结提高。