OO一单元多项式求导作业总结
第一次作业
1. 需求分析
对简单多项式求导,分析输入格式是否符合要求,若符合要求则按同样的格式输出求导结果,否则输出WRONG FORMAT
2. 思路分析
由于这一阶段表达式相对简单,可以很方便地使用正则表达式进行匹配。通过指数、系数两个指标可以将常数项和变量项统一表示,求导法则也只与这两个指标有关。
数据结构方面,使用HashMap,将指数作为key,系数作为value,存储表达式各项,同时也方便了同类项(指数相同的项的合并)
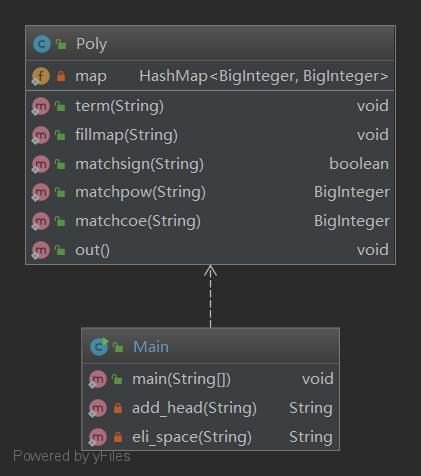
使用IDEA的UML Support插件绘制UML图:
3. 代码度量
使用Statistic插件统计代码行数(Line of Code):

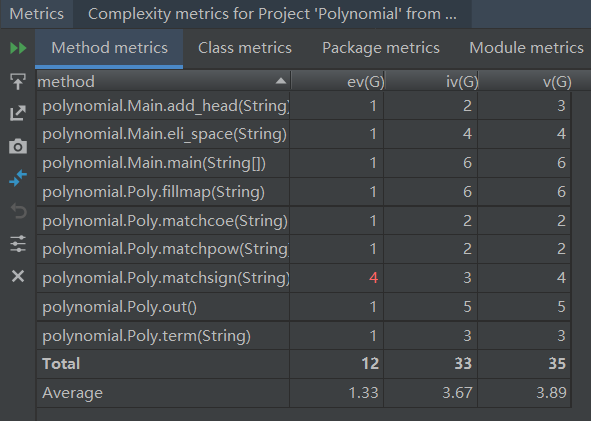
使用MetricsReloaded插件度量复杂性:
说明:
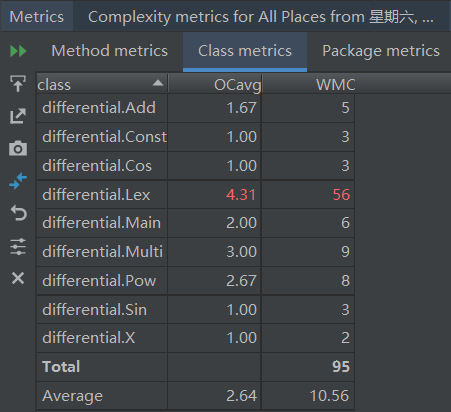
- ev(G)基本复杂度,用来衡量程序非结构化程度
- iv(G)模块设计复杂度,用来衡量模块判定结构
- v(G)独立路径条数
4. bug分析
- 关于正则表达式匹配爆栈的问题: 一开始我采用正则表达式匹配整个输入串验证其合法性,但这种方法在处理长串时会出现迭代次数过多导致爆栈的情况,因此我选择逐项匹配的方式。
- 关于空白字符的问题: \s不仅能匹配<space>和\t,还可以匹配\f\v等目前文法规定的非法字符,因此在匹配之前有必要先进行非法字符检查
第二次作业
1. 需求变化
在第一次作业基础上,增加了以sin(x)和cos(x)为底数的幂函数项
2. 思路分析
考虑到这一次每个项仍然有固定的格式(系数*x幂函数因子*三角幂函数因子),仍然可以采用HashMap,以<x指数,sin指数,cos指数>为key,系数为value存储各项(同时进行合并同类项),对这种固定格式的项应用固定的求导法则,这样第三次作业就可以重构了

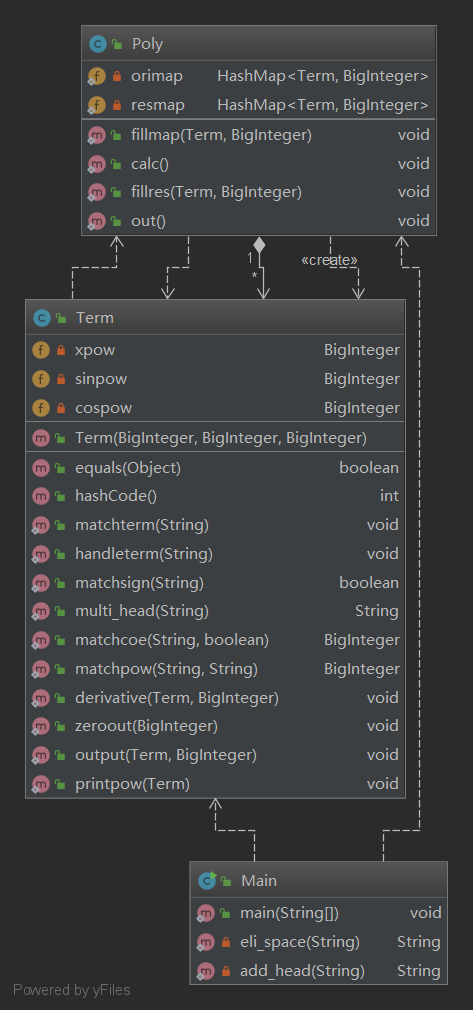
使用IDEA的UML Support插件绘制UML图:
3. 代码度量
使用Statistic插件统计代码行数(Line of Code):

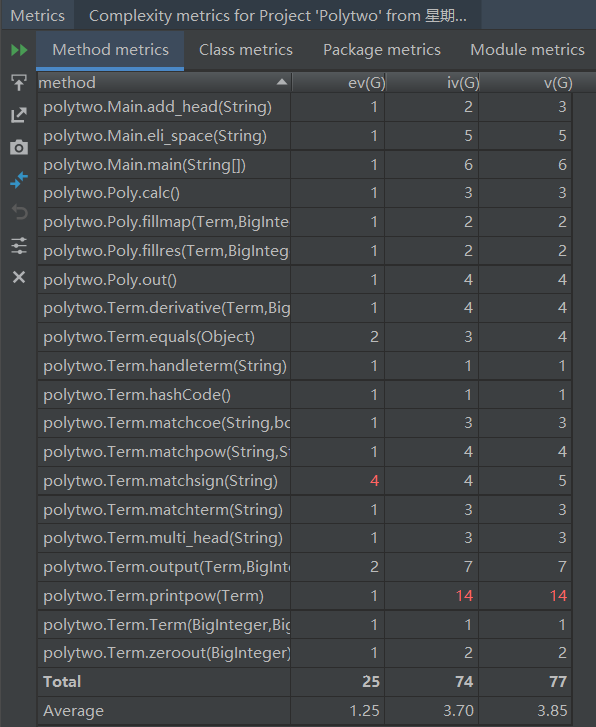
使用MetricsReloaded插件度量复杂性:
4. bug分析
- 一个愚蠢的bug:在填入HashMap时,由于没有重新new一个Term对象,导致后面填入的结果会覆盖前面的项,导致.equals()和.hashCode()方法不能得到正确结果
第三次作业
1. 需求变化
在第二次作业基础上,增加了在sin()和cos()内部嵌套因子的情况,增加了一对()括起来的表达式因子
2. 思路分析
由于第二次作业时的懒惰之前的方法已经不适用,需要进行重构。采用了面向求导接口的层次设计。定义了一个名为Derivation的接口,各种类型的项都实现接口中定义的方法,同时将Derivation作为统一的存储类型(常数项使用BigInteger等情况除外)。
考虑到整个表达式可以拆成由加减连接的一串项,每个项又可以拆成以乘号连接的因子,因此在顶层(表达式层)构建一个Addlist,每个元素可以是Addlist,Multilist或者其他类型的项,从而构建了树型结构。
在输入处理方面,使用了与编译器设计相似的词法分析、语法分析的方式,文法整理如下:
<Exp> = (<Term><+|->)* <Term>
<Term> = [+|-](<Factor>*)* <Factor>
<Factor> = <X>|<Number>|<SinFactor>|<CosFactor>|<PowFactor>|(<Exp>)|<Factor>
<X> = x
<Number> = [+|-](\\d)+
<SinFactor> = sin(<Factor>)
<CosFactor> = cos(<Factor>)
<PowFactor> = (<X>|<SinFactor>|<CosFactor>)^<Number>使用IDEA的UML Support插件绘制UML图:
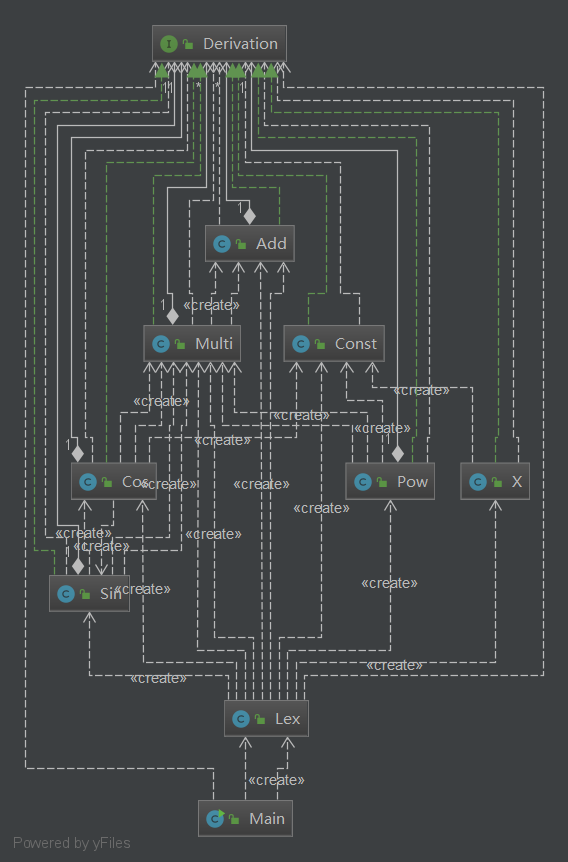
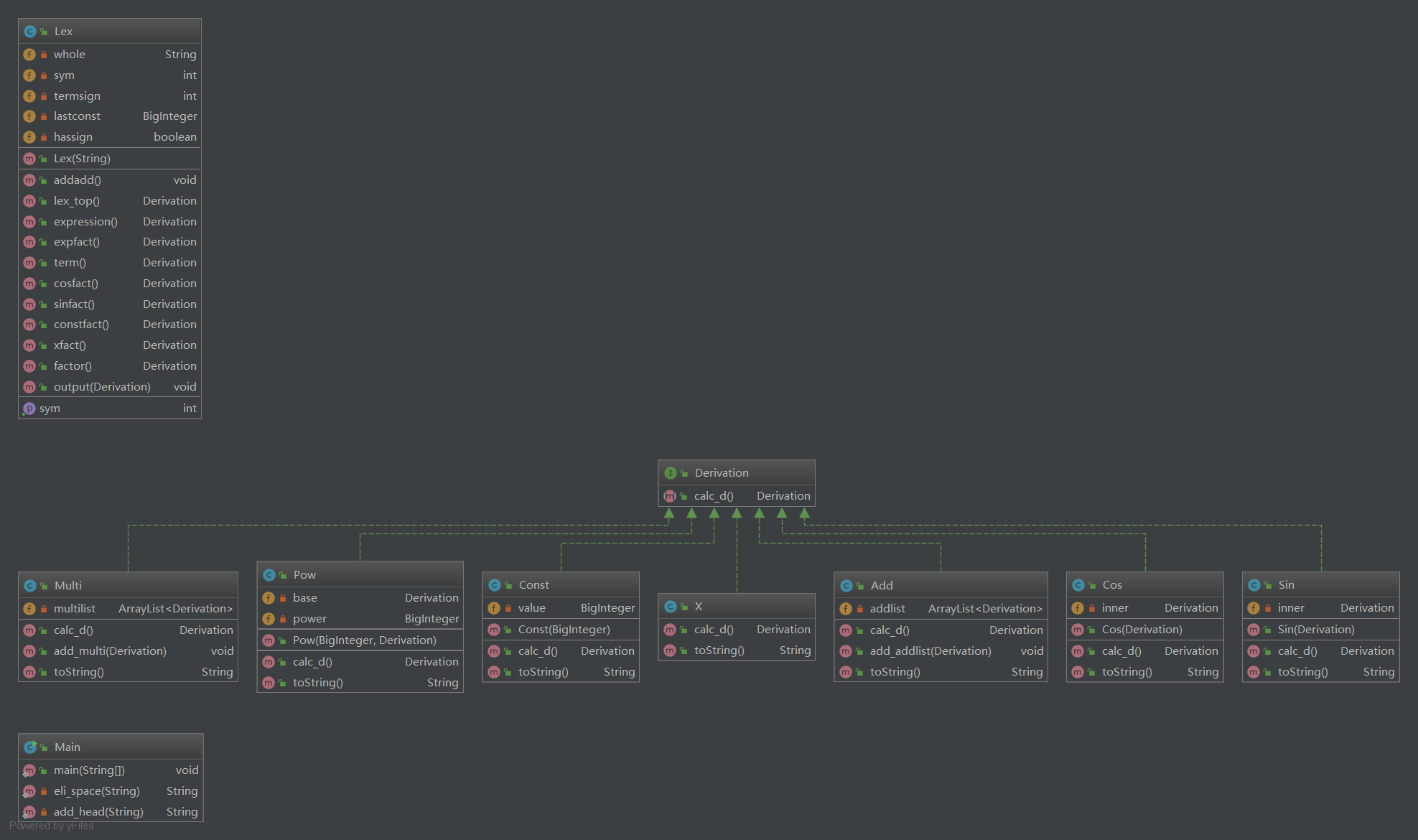
各个类的field和method:
3. 代码度量
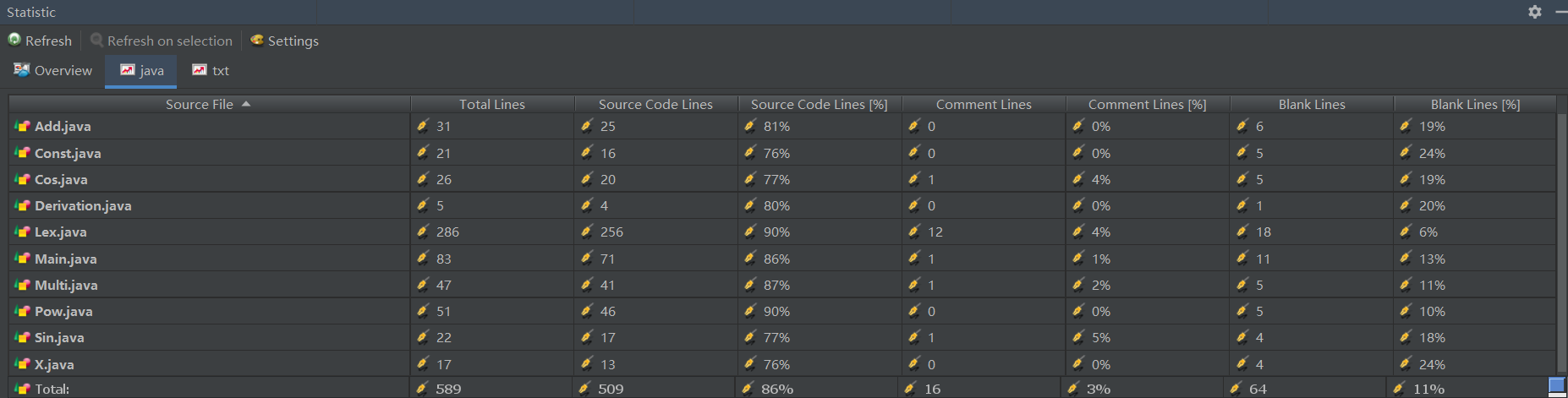
使用Statistic插件统计代码行数(Line of Code):
使用MetricsReloaded插件度量复杂性:
4. bug分析
- 关于暴力化简的问题: 采用循环遍历、逐层逐项比较的方式进行化简,发现在括号层数很多的时候运行时间很长,于是放弃了化简(本身选择的这种存储方式就不适合合并同类项以及sincos平方项合并)
- 关于没仔细看指导书的问题: 一开始没有注意到输出结果中,sin cos括号内表达式因子需要带括号的问题,后来修改了toString方法才过了弱测第四个点
总结
三次作业的设计模式经历了纯过程式——过程式和面向对象混合——面向对象为主的过渡。由于前面没有考虑到层次化设计的需求,可扩展性差,导致后面重构过程相对繁琐。在第三次作业时尝试了Expression-Term-Factor三级继承的设计方式,但最终选择了面向接口的更为简单的实现。