一、分组
建表及数据填充语句下载:链接: https://pan.baidu.com/s/1WHYafwqKJEKq1kDwCH_Zlg 提取码: 3wy4
1.1初识分组
分组是按照某一列,将该列中相同多个相同的数据作为一组,整体分成若干组。
例如有如下表:
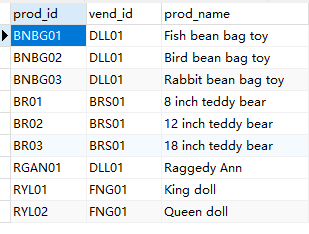
例如将vend_id作为依据分组,则会分成三组。
所有vend_id = DLL01为一组,所有vend_id = BRS01为一组。
所有vend_id = FNG01为一组。
现在我们有这样一个需求,计算每一个每一个供应商有多少商品。
这时我们可以采用这样的思路,先按供应商进行分组,然后采用聚集函数计算。
分组采用GROUP BY colName 进行分组
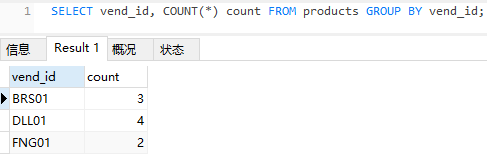
按照vend_id分组后再采用聚集函数计算。
注:SELECT语句后面出现的字段必须是在GROUP BY语句后面出现的字段。
聚集函数除外。因为按照vend_id分成三组后,除了vend_id作为分组的关键字可以正常显示,
每一个分组中其余属性的属性值并不相同,因此不能作为SELECT后面的列。
GROUP BY治具可以任意数目的列,使其可以进行分组的嵌套。
GROUP BY语句必须出现在WHERE之后,ORDER BY之前。
1.2分组过滤
过滤分组类似前面的WHERE,不过WHERE过滤的行,而这里过滤的是分组。
过滤分组采用HAVING 过滤条件。
这里过滤的是分组,是一组数据。
例如现在我们要过滤掉提供商品小于3的供应商。
先按供应商进行分组,然后计算供应商商品数目。
通过HAVING判断数量进行过滤。
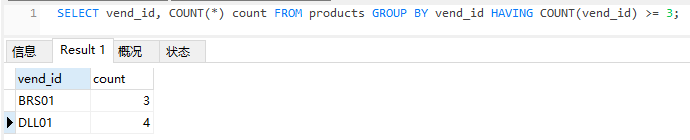
我们来分析下语句的执行顺序,
首先FROM找到表,然后通过GROUP BY进行分组,
然后通过HAVING判断每一个分组的行数是否大于3,大于等于3的分组保留下来,其他的忽略。
最后通过SELECT输出每个组的关键字(vend_id)和每个组的行数。
注:HAVING 筛选条件,满足筛选条件的会被保留下来。
本例执行顺序FROM ->GROUP BY->HAVING->SELECT;
如果在加上WHERE会怎么样呢?
WHERE是在分组前执行,HAVING是在分组后执行,
例如:

先通过FROM找到表,然后执行WHERE保留所有prod_price大于4的商品。
然后通过vend_id分组,然后再通过COUNT()计算每个分组的数量,保留商品数>=3的分组。
最后返回保留下来的分组,即商品价格大于4,且商品数量大于3的供应商。
本例中的分组是在WHERE执行后进行分组,也就是说分组的数据是WHERE过滤完成后保留下来的数据。
WHERE是在分组前执行,HAVING是在分组后执行。
如果再加上ORDER BY呢?

本例中ORDER BY是最后执行的,ORDER BY先按vend_id升序排列,
在vend_id相同的情况下才会按count进行排序,而count是SELECT中定义的别名。
别名只有定义后才能使用,如果某一个关键字是在SELECT之前执行,例如WHERE,
那么在该关键字中使用count会报错,因为此时count还没有定义,此处就需要注意
语句的执行顺序,以及别名要在定义后使用。
在A中指定别名,如果BCD都在A后执行,则可以在BCD中使用。反之则不行。
二、子查询
子查询是将查询结果作为查询条件,可多层嵌套。
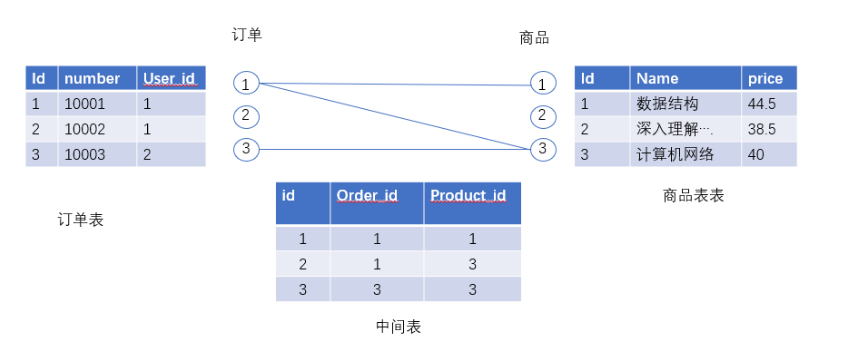
例如当前有这三张表,1号订单有中有1号3号商品,
3号订单中有3号商品。
1号商品在1号订单中,3号商品在1号和3号订单中。
现在需要通过订单查询对应商品。
例如查询1号订单的所有商品:
基本思路,先通过订单表中id作为筛选条件,查询出中间表中order_id = 1的所有行(1,2行)。
再将这些行中的product_id(1,3)作为查询参数,查找商品表中对应商品。
这时就需要使用子查询,将上一级的查询结果,作为下一级的参数参数。
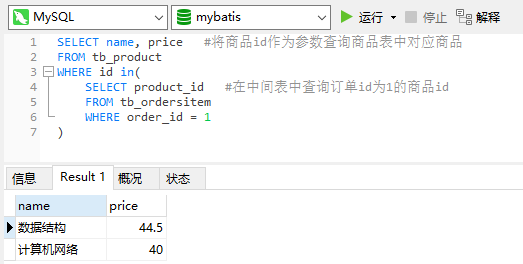
执行时先执行最内层的查询,然后将结果作为上一次的查询参数,如此往复可嵌套多个。
字段子查询

首先通过FROM查找custoemr表,返回每一行数据时,将将该行数据中的custoemr.cust_id作为查询参数
在orders表中查找与orders.cust_id相同的数据,计算行数(即对应客户订单数),依次计算所有客户的订单数。
最后通过订单数降序排列。
注:由于cust_id重名,为了使其区分出是哪一张表中的字段,所以在前面添加了表名。
三、联结
3.1、初始联结
在关系型数据库中,某些数据是分开的,通过某些关键字将多个表连接起来。
这样比较可以节约空间,例如一张商品表,一张订单表,通过商品id关联。
这样的多个表相关联的情况就需要使用子查询或者联结。
之前使用子查询较为繁琐,需要考虑每一级的返回参数等。
而联结可以隐式的将多个表关联起来,我们只需要指定查询条件即可。
例如:
cusomers
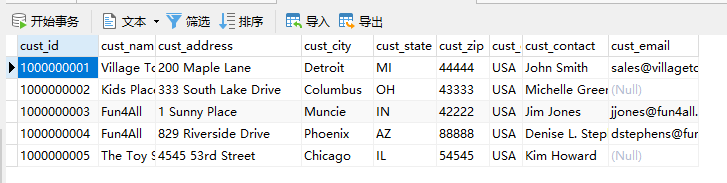
orders

订单表中存储客户ID,可以通过子查询查找客户订单。
现在我们使用联结来查找。
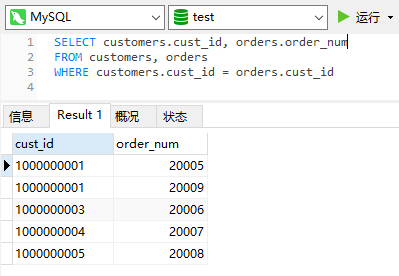
首先将customers,orders表联结,然后通过customers.cust_id在orders表中查找cust_id相同的行。
我们尝试下不加WHERE看看联结后的表是什么样子的。

customers表中的每一个行都和对应了order整个表。
不加WHERE会出现笛卡尔积,即第一表行数*第二个表行数。
对于此联结还可以按如下方式写:

相当于在cuseomer表中加入orders表,ON相当于WHERE。
内联结(INNER JOIN)只会返回相同的部分,即customer.cust_id = orders.cust_id的部分。
使用(FROM table1,table2...)联结多个表默认也是使用内联结。
3.2联结与表别名
联结过程中某些查询字段名称相同,需要通过(表名.列名)的形式来区分。
有时表名较长写起来不方便,这时可以先为表名指定别名,然后通过(别名.列名)
的方式来指定。
orderitems
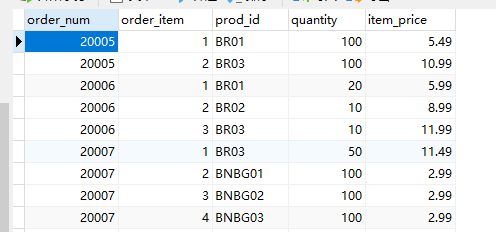
orders
customer


先将orders与orderitems联结,并通过order_id查询,获取到一张订单及对应商品的表(订单-商品)。
然后再将这张表与客户表关联,通过客户表中id查询(订单-商品)表中的对应客户id相同的部分,
找到客户的所有订单。而每一个订单有携带了自身包含的商品。
一号客户有两个订单(20005,20009),每个订单中又有多个商品。
O,OI,C是别名。
3.2外联结
上列我们使用的基本都是内联结,即联结的两个表只会返回满足匹配条件的行,
例如:表一.name = 表二.name 只会返回表一中name等于表二中name的行。
除了这种内联结外,还有外联结,比如左外联结,无论左表中的行是否满足条件都会返回。
下面看一个例子。
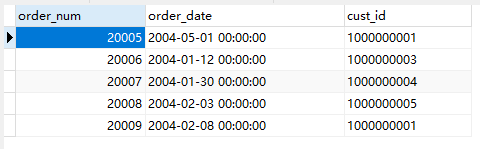
customer

orders

现在我们通过cust_id查找客户对应订单
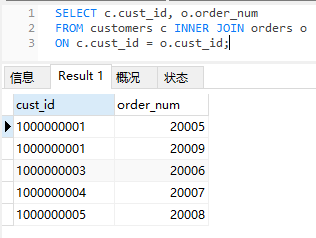
只有两个表中都有cust_id的行被保留了下来,
例如客户表中有100000002,但是orders表中没有cust_id=10000002的客户。
所以没有保留100000002.
有时我们需要保留没有订单的客户进行分析,这时就需要使用到外联结。
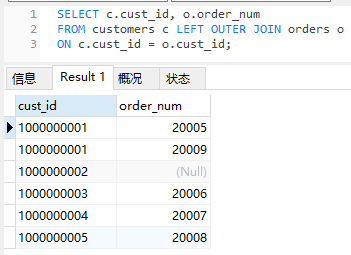
LEFT为做外联,即左表(custoemrs)中的每一项都会显示出来,即使不满足ON后面添加也会显示出来。
LEFT OUTER JOIN 中的OUTER可以省略。
除了左外联还有右外联,RIGHT JOIN
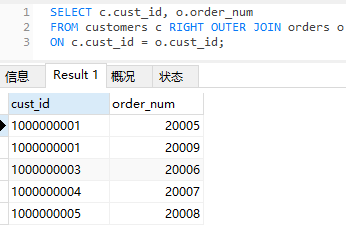
由于订单表中每个订单必有用户对应,所以和之前内联查询结果没有多大区别。
之前通过做外联计算出客户订单后,我们可以通过聚集函数计算出每个客户的订单。

参考资料:
《SQL必知必会》