第一次总结性博客
16071070 陈泽寅 2019.3.23
一、第一单元所学总结
- 首先先来总结一下第一单元我所学到的知识以及所感所悟。第一个单元,是我第一次接触JAVA语言,并且再使用了几次之后,就被这门语言的独有的魅力以及简便的用法所深深吸引。下面我从三个方面来简单阐述一下我对于JAVA相比较于c语言的优势。
- (1)从架构上来说,java的设计思路是不同于c的,它是一门面向对象的语言,我们的思维从熟悉的过程式编程语言转移到了对象思维上来。这样的思维的好处是,我们可以将一个大的问题分成很多个小的类去进行处理。如果说过程式编程是一个庞大的整体,而函数是其一个个功能的分布,那么在java里类就是实现各个子模块的实现者。在java的面相编程思维中,类的设计秉持高内聚,低耦合的思想。即在每个类的内部只关心自己类的操作,而不去关心其他类的事情。这样的好处是,我们把整个过程细化成很多个类去实现,每个类只需实现自己的功能,而不需关心其他类的功能。这样方便程序员在写每个模块的时候不需考虑当前类对其他类的影响,并且方便进行单元测试以及问题的发现。同时当某个需求发生改变时,只需更改相应的类,而不需去修改其他相关的类。因为类与类之间的关系是低耦合的。这样方便日后的维护与调试。
- (2)从设计安全性的角度来说,java在大型项目开发的时候更加安全。因为每个类的属性都是private的,其他类不能直接访问当前类的私有属性,因此无法直接对属性的值进行修改。这是安全的,因为其他类可能并不知道这个类的设计原则,若直接修改类的属性可能导致bug的产生。java针对这种情况提供了public方法,其他类可以调用public方法去实现类属性的修改,而一些修改的限制都写在方法中,因此其他类无需知道这些细节,并且这些public方法也保证了类属性数据的安全性。同时java还提供了接口的思想,即很多不同的类为了实现某个接口,就能实现类与类之间的联系。这样就大大增加了程序的可扩展性和可移植性。
- (3)java还有一个很大的优势就是其写法相当简便,相比于c它提供了大量的内置函数包以供调用,比如其String类,ArrayList类,HashMap类等等。还有一些sort,find函数,这些函数都是经过优化的方法,省去了程序员一些复杂地基本操作,使程序可读性增强。
二、多项式求导程序设计说明
(1)第一次作业:
第一次作业的设计,现在看来真是杂乱不堪,完全是面相过程式编程,只不过是套了一个JAVA的壳子而已,存在很多的问题。
第一次作业的题目是求一个简单多项式的导数。所有的表达式都是形如\(f(x) = \Sigma a*x^c\)这种形式。这个多项式是一个字符串类型,当然我们首先应该判断其是否合法。我的思路是首先通过正则匹配检查是否存在不合法的空格。String pattern1 = ".*[+-]\\s*[+-]\\s+\\d.*"; String pattern2= ".*[\\^]\\s*[+-]\\s+\\d.*"; String pattern3 = ".*\\d+\\s+\\d+.*";上述的三个表达式分别判断了是否存在表达式加法时的带符号整数之间的非法空格,数字与数字之间的非法空格,以及指数后的带符号整数的非法空格。在判断不存在这样的非法空格之后,为了方便后续的项的分离,我们将字符串中的所有空格和\t制表符全都删去。
然后我们对整个字符串进行合法性的检验,检查其每一项是否都属于\(f(x) = a*x^c\)这种形式。这里的正则表达式如下。pattern1 = "([+-]{0,2}(((\\d+[*])?[x]([\\^]([+-])?\\d+)?)|(\\d+)))";我们这里需要注意,因为其是贪婪性匹配,每次都去匹配满足上述模式的最大字符串,因此当字符串巨大时可能会存在爆栈的情况,因此我们调用Pattern Matcher里的方法将其分成一个个小的GROUP,并得到每个表达式的系数以及指数,并将其存在多项式类中
下面是第一次作业的类图
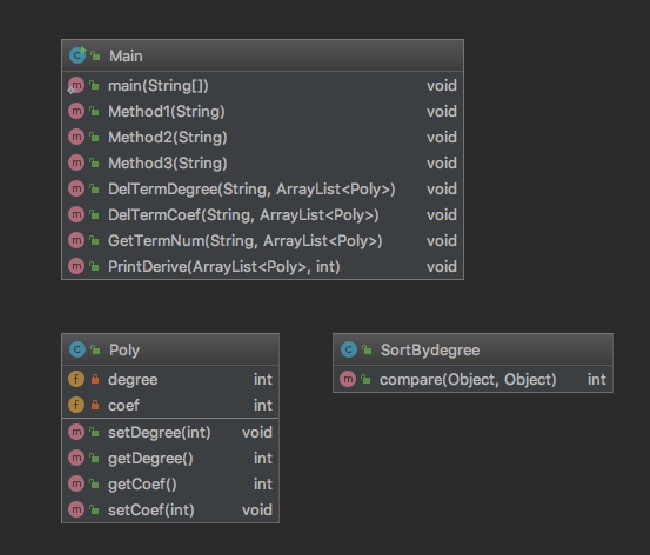
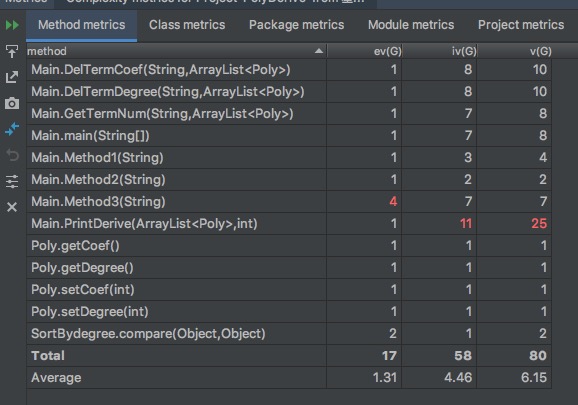
第一次作业的失败主要是把所有的函数方法都写在了一个类里面,无论是数据的读取,还是表达式的构造,以及最后的输出,都是在一个Main类里,导致这个类的长度达到了几百行。这是明显违反了OO的设计准则的。正确的设计方法应该是首先构造一个读取类,这个类专门用来读取数据,并且存储我们的字符串。然后再写一个判断类,来判断我们的字符串是否合法。再通过一个分离类,将我们的字符串进行分离,将分离出来的数据存储在我们的多项式类中,最后再通过输出类来进行数据的输出。这样每个模块功能明确,并且当日后增加需求的时候,大的模块不需要变动,只需在各个类中添加或者修改方法即可。(2)第二次作业:第二次作业在第一次作业的基础上增加了\(sin(x)以及cos(x)这两种幂函数\),并且在每个表达式中允许存在两个因式相乘的形式。由于第一次作业的偷懒设计,导致第二次作业的架构需要重新设计,但是在做完第三次作业之后发现第二次作业的设计依旧是有很大的弊端。
第二次作业的多项式的形式是 \(f(x)=\Sigma a*sin(x)^b*cos(x)^c*x^d\)。项里可以存在乘法,这就需要更改之前的表达式的分离的方法。首先我先更改了多项式的存储结构,运来的多项式里只包含x的指数和系数。现在加入了\(sin(x)和cos(x)\)的指数。最后得到一个项的list,并且根据相应的公式进行求导。求导的公式是
\(a*l*x ^ (a - 1)*cos(x)^c*sin(x)^b + b*l*x^a*cos(x)*cos(x)^c* sin(x)^(b - 1) - c*l*x^a*cos(x)^(c - 1)*sin(x)*sin(x)^b\)这次作业在上一次的基础上更新正则表达式的匹配样例
String patternHead = "[+-]{0,2}(([+-]?\\d+)|(" + "[x]([\\^][+-]?\\d+)?)" + "|([s][i][n][\\(][x][\\)]([\\^][+-]?\\d+)?)" + "|([c][o][s][\\(]" + "[x][\\)]([\\^][+-]?\\d+)?))([*](([+-]?\\d+)|([x]([\\^][+-]" + "?\\d+)?)|" + "([s][i][n][\\(][x][\\)]([\\^][+-]?\\d+)?)|([c][o][s][\\(]" + "[x][\\)]([\\^][+-]?\\d+)?)))*";通过这个表达式去得到一个个项,然后通过split
函数将\(*\)号分开得到一个个因式,再通过因式的匹配样例Pattern pattern = Pattern.compile("[+-]{0,3}[0-9]+"); Pattern pattern = Pattern.compile("([+-]{0,2})[x]([\\^]" +"?(([+-]?)(\\d+)))?"); Pattern pattern = "([+-]{0,2})sin[\\(]x[\\)]([\\^]([+-]?\\d+))?"; Pattern pattern = "([+-]{0,2})[c][o][s][\\(]x[\\)]([\\^]([+-]?\\d+))?";分别得到了项的系数,\(x的指数,sin(x)的指数,cos(x)的指数\),然后存入我们的结构体中。最后通过上述求导公式对每个项进行求导,并且将相同系数的项合并。
类图如下
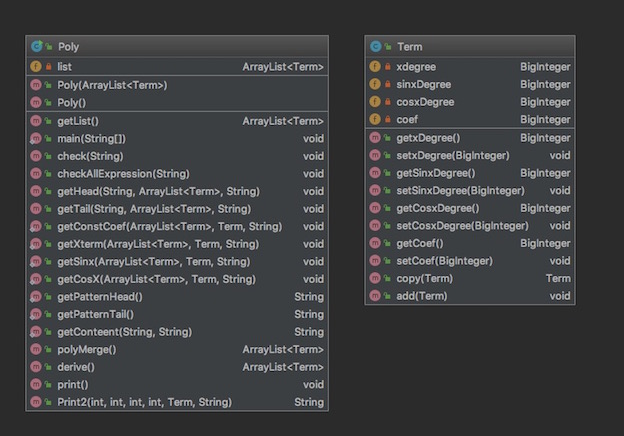
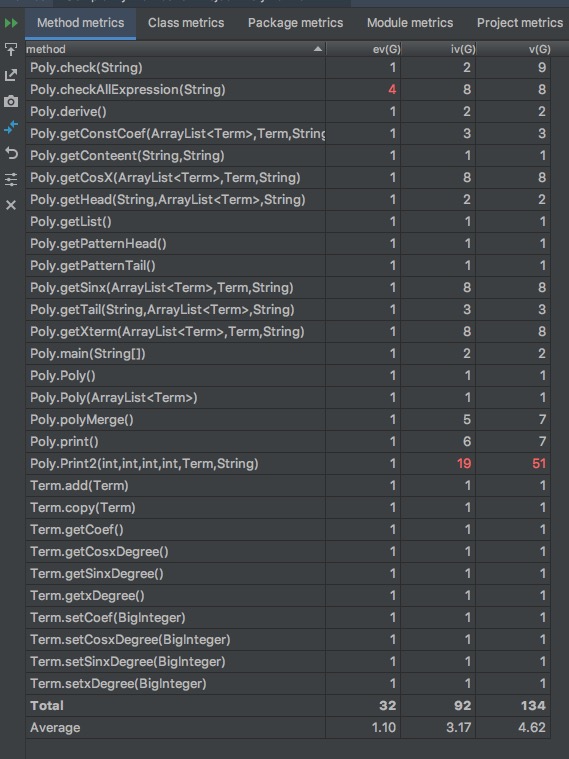
可以看到其实第二次设计依旧没有秉持好的设计原则,虽然将不同的功能写在不同的方法里,但是没有实现类的分类,这里好的设计应该是sin(x),cos(x),x单独分类,然后进行求导,以及输出。然而这里混在了一起,导致main方法十分庞大,修改一个地方会导致很多方法都需要修改。因为代码之间的耦合度非常高,并且几乎所有的操作都是写在Poly里的静态方法,导致第三次作业又需要进行大规模的重构。
(3)第三次作业
这次作业是我三次里认为还比较满意的一次作业,因为这次的题目比较复杂,因此我觉得不能再像前两次作业那样急于编写代码,因为这样会导致代码紊乱,最后难以找bug。因此在动手写代码之前,我仔仔细细地参照面相对象编程的思想,对第三次的题目进行了思考,先把类和接口设计好再进行动手编写代码,果然想清思路之后再下手,写起来快并且最后的bug也少了,代码思路非常清晰。简单分析一下这次的作业,这次的多项式求导不仅延续了之前的项的思路,还添加了嵌套求导的规则。即
表达式 = 项{+项} 项 = 因子*{因子} 因子 = (表达式)|因子也就是类似\(sin(cos(x))\)这种嵌套的求导。我知道再延续以往的面相过程求导肯定是行不通的了。因此这次的设计对每一步进行了细致的类的划分。类图如下。
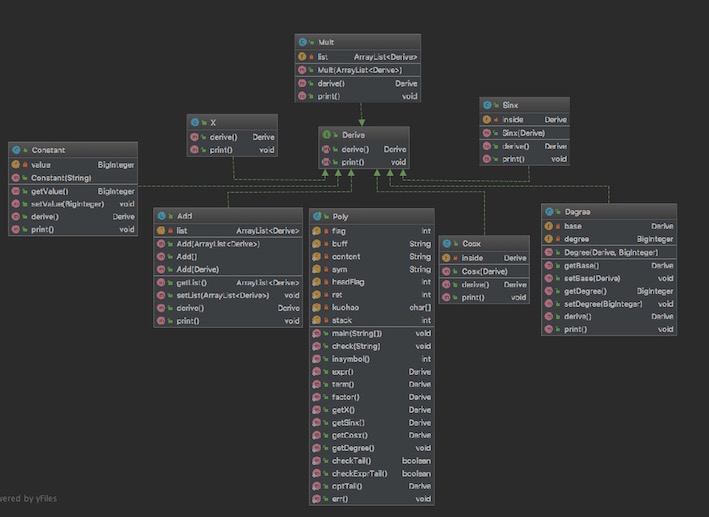
下面来讲一下我的做法,首先我这次划分了很多个类,常数类、x项类、cos项类、sin项类、指数项类、加法类、乘法类这些类,这些类都实现了一个求导的接口,也就是说所有求导的对象都是另一个可求导的对象,比如说指数类里,指数的底数也是一个实现了求导的类,这样就很好地体现了分类的思想,并且在指数这个类里,我只需管指数函数是如何求导的,而不需要管其底数是什么,因为底数实现了求导接口,底数也会自动去调其覆写的求导方法去对底数进行求导。这样就使我们的程序显得很简单。
这里的加法和乘法类就是指两个实现了求导接口的对象相乘进行求导,我们只需关心乘法的求导是怎么样的,而具体对象的求导,放在具体的对象的求导里去完成,这样就真正实现了低耦合的思想。具体的接口的代码如下:
public interface Derive { public abstract Derive derive();//求导函数 public abstract void print(); }然后乘法里实现的求导接口的求导方法如下。
public Derive derive() { ArrayList<Derive> addList = new ArrayList<Derive>(); for (int i = 0; i < this.list.size(); i++) { /** 根据几个函数连乘的求导法则进行求导 * result = (ui' * (u1*u2*....un)/ui)的和 */ ArrayList<Derive> multList = new ArrayList<Derive>(); for (int j = 0; j < this.list.size(); j++) { if (i != j) { multList.add(this.list.get(j)); } } multList.add(list.get(i).derive()); Mult mult = new Mult(multList); /** * 这条multList 就是Add链中其中的一条 * */ addList.add(mult); } /** * 至次为止, addList是由好几个Mult类构成 */ return new Add(addList); }我们可以看到,对于\(f(x) = h(x)*g(x)\)的求导,只需关心\(f(x)'=f(x)'g(x)+f(x)g(x)'\)即可,而不需关心\(f(x)'和g(x)'\)是什么,因为\(f(x)和g(x)\)都是已经实现了求导方法的对象,在他的类里会调用自己的求导方法进行递归求导。
在明确了类的框架结构以后,我们再想办法对字符串进行处理,我一开始尝试原来的正则文法匹配的方法,但是发现自己不明白如何去产生上述的表达式里嵌套因子的方式,但是我发现,这个形式和我们之前学过的编译原理的递归下降分析法类似。于是我采用相同的思想先写了一个简单的词法分析小程序,然后构造了expr(),term(),factor()三个子程序来对字符串进行读取。这样就能实现程序的因子里嵌套表达式的形式了。下面举一个简单的表达式的例子。
/** * 自顶向下的表达式子程序 */ public static Derive expr() { /** * 表达式 = 项 {+项} */ ArrayList<Derive> exprList = new ArrayList<Derive>(); Derive term1 = term(); exprList.add(term1); if (!checkExprTail()) { System.out.println("WRONG FORMAT!"); System.exit(0); } while (sym.equals("Add") || sym.equals("Minus")) { headFlag = 1; term1 = term(); exprList.add(term1); } if (!checkTail()) { err(); } return new Add(exprList); }这样在后续的调试过程中我可以单独根据每种形式的求导来找问题,就能很快地发现是哪个求导过程发生了问题,简明扼要。
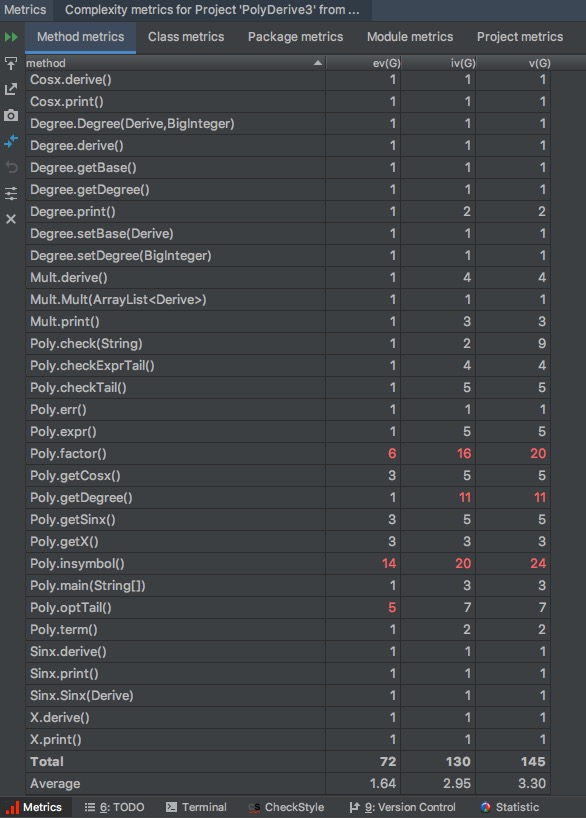
三:程序结构分析
各类代码总规模:(statistic)
SourceFile Total LinesSource Code Source Code Comment Lines Blank Lines Derive.java 8 4 3 1 X.java 10 8 0 2 Constant.java 25 19 0 6 Sinx.java 28 18 4 6 Cosx.java 28 20 3 5 Mult.java 52 30 13 9 Add.java 54 40 3 11 Degree.java 61 36 13 12 Poly.java 390 345 21 24 Total 658 522 60 76 类的属性方法个数
类 属性 方法 Derive.java 0 2 X.java 0 2 Constant.java 1 3 Sinx.java 1 3 Cosx.java 1 3 Mult.java 1 2 Add.java 1 2 Degree.java 2 5 Poly.java 8 14
四:程序优缺点
优点:
1:将复杂的多项式求导分成诸多形式的类,每个类只需注意自己的求导形式,具体的求导规则由各个实现求导接口的类去完成。 2:采用递归下降子程序法,使字符串的处理比较容易理解,并且不容易出错。 3:使用了接口的思想,方便可扩展性。 4:实现了高内聚低耦合的思想,使每个类和方法尽量能干的事情少,各自之间互不影响。缺点:
1:在处理项的连乘的时候可能会出现爆栈的情况。 2:没有做完备的可能发生异常的情况的统计与测试。 3:单元测试不够完备,Main类的设计还过于冗杂。 4:存在大量的if-else语句,不够精炼,存在代码复用比较严重。 5:输出的时候如果嵌套层次太多,会导致大量的()产生,很难进行优化。
五:程序的Bug分析
第一次
第一次的bug在于没有处理指数或者系数过长可能抛出的异常,没有意识到助教和老师在作业指导书里的提示,这个问题在我理解了BigInteger类之后得到了较好的解决。并且在checkStyle风格检查的时候,没有按照规范要求的行数以及缩进。还存在表达式第一项如果为数字的话前面的符号的个数的问题。
第二次
- 第二次的第一个小bug是未考虑Scanner异常输入时抛出的异常会使程序crash,这里只需要在输入的地方加上try-catch的异常处理即可。
- 第二个bug是在去除空格的时候没有吧制表符\t一起去除,没有重视空格space与制表符在ASCII码上不同的本质区别。
- 第三个bug是在输出的时候,我是按照不管指数系数为不为0或1,全部将其按照\(a*x^b*sin(x)^c*cos(x)^d\)的格式输出,然后再对字符串进行处理,去掉"+1","1","^1"这些,但是忽略了完备性,如果一个指数恰好是 \(y^12\),那么去掉\(*1*\)之后就变成了\(y2\),这明显是错误的。错误的原因就是没有对类进行细分,如果按照第三次作业的方式对每个函数进行分类输出就会简单很多,可以分别判断系数、指数为0为1的情况,就可以省去大量的if-else并且保证程序的正确性。
第三次作业
- 没有考虑到输出的时候\(sin(2*x)\)这种错误的输出格式带来的问题。
- 一开始没有做左右括号匹配的处理。
六:自我评价与寄语
通过第一个单元的学习,已经基本掌握了各种java类的用法,也理解了面向对象的设计思想。了解了继承与接口的原理。但是在使用上还存在不熟练的时候。希望在日后进行多线程学习之前,能够把java的基础打扎实,写出漂亮稳定的好程序。