BUAA_OO第一单元作业总结
单元任务
第一单元的任务为实现表达式的求导,其中第一次作业是对简单多项式的求导,第二次作业是对包含简单幂函数和简单正余弦函数的多项式的求导,第三次作业是对包含简单幂函数和简单正余弦函数同时存在嵌套情况的多项式的求导。
一、基于度量的程序结构分析
第一次作业
1. 设计思路
第一次作业给出的多项式每一项之间仅包含加减运算,并且每一项都有固定的格式,即为系数*x^指数,因此可以创建两个ArrayList链表,一个为系数,另一个为指数。首先通过正则表达式将关于空白符与符号错误的情况进行识别过滤,之后将字符串中省略的部分进行替换,使每一项都符合标准格式,即系数*x^指数,通过遍历字符串,识别每一项的系数和指数。通过这两个链表实现求导功能。
优化部分包括合并同类型、省略系数和指数和正项提前。如果指数部分相同,则将系数相加合并为一项;如果系数为零,删除这一项,如果系数为1或-1,省略1和乘号,如果指数为1,省略^1,将所有的+-替换为-;将第一个系数为正的项提前,可以减少一个符号。
2. 类图

3. 程序结构分析
首先解释一下每一项的含义:
LOC: Lines of Code 代码行数
NCLOC: Non-comment Lines of Code 没有注释的代码行数
ev(G): Essential Complexity 基本复杂度:用来表示一个方法的结构化程度。
iv(G): Module Design Complexity 模块设计复杂度:用来表示一个方法和他所调用的其他方法的紧密程度。
v(G): Cyclomatic Complexity 圈复杂度:圈复杂度用来衡量一个模块判定结构的复杂程度,数量上表现为线性无关的路径条数,即合理的预防错误所需测试的最少路径条数。圈复杂度大说明程序代码可能质量低且难于测试和维护。


从上述数据可以看出程序的复杂程度比较高,结构化程度不高,说明这次的程序主要还是面向过程的思路,没有通过面向对象的思路来实现。类的创建也不是很合理,虽然创建了一个类,但与其说是类,不如说只是一些方法的集合,并没有体现出类与类之间的逻辑结构,以及类的封装特性。同时,因为第一次编写java程序不太熟悉,程序中是通过遍历来实现每一项的区分,并没有使用字符串的split操作,导致程序比较复杂,代码行数也比较多,同时程序也不具有可扩展性,不能应用于第二次和第三次作业。
第二次作业
1. 设计思路
第二次作业相较于第一次作业相对复杂了一些,加入了三角函数,但与第一次作业相同的是,每一项依旧有固定的格式,即系数*x^指数*sin(x)^指数*cos(x)^指数,因此每一项可以通过系数、x的指数、sin(x)的指数、cos(x)的指数这四个属性来表示。本次作业创建了三个类,Main类用于控制输入输出,Poly类表示多项式,用于管理和创建每一个项,其中包含多项式求导以及多项式优化的方法,Term类即为描述项的类,其中包含属性和实现求导的方法。其余部分的设计思路与第一次类似。
优化部分相较于第一次的优化,还多出了sin(x)^2+cos(x)^2=1的优化可能,因此多出了许多种优化的可能,有些优化会减少结果的长度,有些优化反而会增加结果的长度,因此在程序中对于sin(x)^2+cos(x)^2=1的情况,只进行了一定会减少长度的优化,并没有实现所有的优化。
2. 类图

3. 程序结构分析

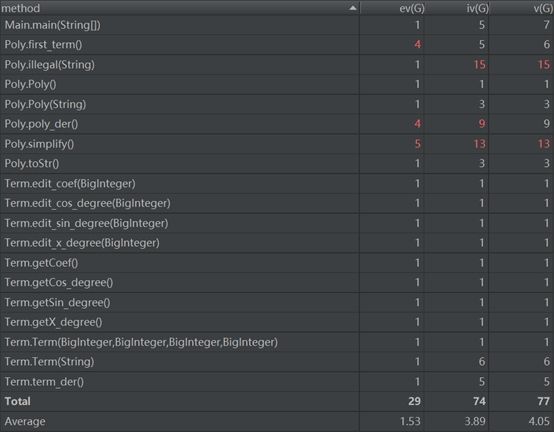
从上述可以看出,相较于第一次作业,这次作业程序的模块化更为明确,类之间的逻辑关系也更加清晰。从复杂度数据来看,程序的平均复杂度有所下降,每个方法的复杂度也有所下降,说明面向程序的思想有所减弱。这次程序的主要缺点在于优化部分没有完全实现,忽略了一些可以优化的情况。
第三次作业
1. 设计思路
第三次作业在第二次作业的基础上加上了嵌套的情况,因为有递归嵌套的可能性,本次的程序主要采用了递归下降子程序的结构。
输入的表达式由多个项通过加减进行组合,因此表达式Expr类的结构为
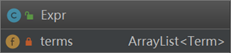
对表达式通过+进行分割,得到一个个项,项由多个因子相乘,因子包括表达式因子、常数因子、幂函数因子、三角函数因子,因此Term类的结构为
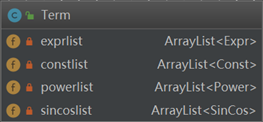
此时,在构造的过程中就出现了递归嵌套的结构,在通过字符串构造表达式Expr时,需要构造项Term,而在构造Term的时候有可能需要构造Expr,体现了递归子程序的思想。
幂函数Power类的结构与之前类似,包括系数和指数,此处的系数主要是为了处理像-x和+x这样省略系数的情况。
三角函数SinCos类相对比较复杂一些,结构为

因为正弦函数和余弦函数的格式类似,在程序中将两者合并为一个类,通过String类型的type来进行区分。因为允许嵌套,三角函数括号内部通过表达式Expr来进行描述,index为三角函数的指数,coeff是为了处理出现系数省略的情况。
每一个类中都有相应的求导方法,例如Expr类中的求导是通过对链表中所有的Term进行求导,再将结果加起来,而Term中的求导则是按照求导公式,分别求导再相加。
本次作业为了保证正确性,只进行了特殊系数和特殊指数的优化,并没有进行其他优化。
2. 类图

3. 程序结构分析

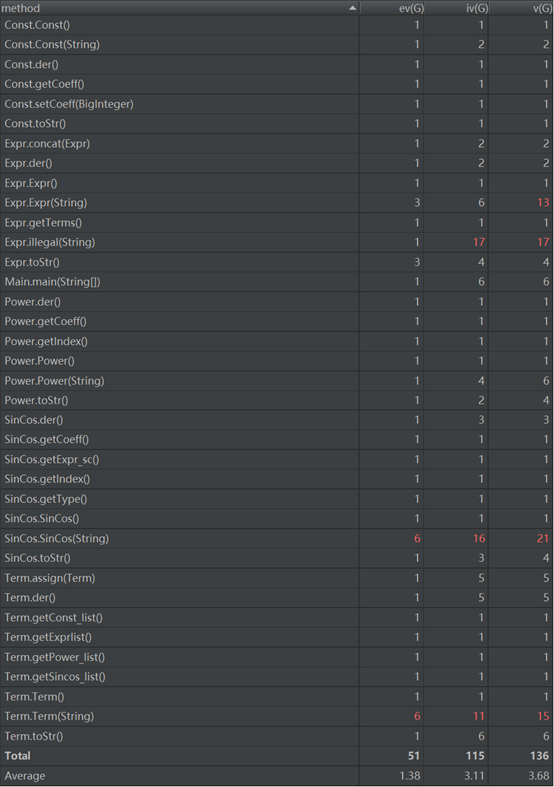
从上述数据可以看出,平均复杂度相较于第二次作业有所下降,但却出现了一些复杂度比较高的方法,说明依然没有实现高内聚低耦合的结构。本次作业的优点在于程序更加结构化了,代码行数也变较少,相较于第二次作业,虽然功能增加了很多,但代码行数却没增加多少,缺点在于本次作业并没有采用课堂上讲解的继承和接口和没有实现优化。本次作业可以将不同类型的项汇总成一个接口,而表达式Expr则是一个接口组成的链表,每个类中定义不同的求导和转换字符串方法,在对表达式求导的时候,也就是对每一个接口进行求导,因为接口的特性,在对项求导时,调用的求导方法是每个项对应类的求导方法,这样实现可以减少很多在求导时的判断,将所有的项看作一个整体,转换为字符串时也是同样。这样可以有效地减少程序的递归次数,在最终转换为字符串和优化时也会减少很多麻烦。像我之前的代码,在生成求导结果的时候就会产生多重嵌套,原本只是一个常数系数也会被看作一个表达式处理,在优化的时候造成了很大的麻烦。
二、程序bug
1. bug特征与所在的类和方法
第一次作业的功能比较简单,可能出现bug的地方只要是错误情况的判断。为了便于对字符串进行模块化的处理,需要将输入的表达式的每一项转换为标准格式,为此需要将一些符号,例如++,--,x进行替换,此时可能会将一些错误的输入变成可以识别的输入,无法实现鲁棒性。
第二次作业的bug主要是在优化部分,在使用正则表达式对结果字符串进行替换的过程中,没有测试到^1后面是数字的情况,因此在替换之后出现错误的结果表达式。
第三次作业的bug可能是会忽略对于-1系数的处理,还有就是对于错误情况的判断。因为我的程序使用的是split方法,因此对于最后一个*后面没有输入的情况是不会判断其为错误输入的。
2. bug位置与设计结构之间的相关性
从这三次作业来看,bug的位置一般都是处于需要对情况进行分类的位置,例如很多if语句的位置或者if语句的判断条件极为复杂的位置。因为需要分类,就难免会出现考虑不全面的问题,一旦出现考虑范围之外的输入,程序立刻就会出现错误。其次就是对于不同情况划分不明确,这样会导致程序的鲁棒性不高,也可能出现调用的方法不对应。
3. 从分类树角度分析程序在设计上的问题
分类树可以将输入根据特定的条件进行划分,其叶子节点为输入的各种可能情况,将所有叶子节点的可能情况进行排列组合就可以尽可能覆盖所有的输入情况。而将程序与分类树进行对比,能相对容易地发现程序在设计上的问题。当程序的分类情况少于分类树的叶子节点时,说明有情况是程序设计没有考虑到的,会在缺少的情况输入时出现bug。
三、Applying Creational Pattern
第一次和第二次作业中因为功能比较简单,因此不太需要使用创建模式。
第三次作业可以使用工厂方法模式,简单的工厂模式,就是去创建一个创建对象的工具类,具体到第三次作业,就是创建一个类用于根据字符串创建不同的类,调用类中不同的创建方法。而我目前的程序是将对象初始化的方法放在了构造函数中。之后再创建一个接口,将所有类的求导方法通过这个接口连接在一起。
如果要重构的话,首先需要创建一个创建的工具类create,根据字符串不同的开头情况,调用相应的创建方法,其次需要创建一个接口的类Node,将常数类、三角函数类、幂函数类、项类、表达式类通过这个接口连接在一起,在每一个类中实现对应的求导方法。
四、总结
通过这三次的作业,我逐渐脱离了之前面向过程的思想,开始向面向对象的思路转换,同时也熟悉了一些java编程时的技巧,比如使用正则表达式以及一些已经写好的方法。通过对需求的扩展,使我们明白了一个程序架构的重要性,如果在写代码之前先进行设计,在实现的时候就可以规避很多麻烦,而一个良好的设计可以为程序带来很好的扩展性,在面对扩展的需求时,也不需要进行重构。