IterativeQuantization: A Procrustean Approach to Learning Binary Codes 论文理解及代码讲解
这篇文章发表在2011年CVRP上,一作是Yunchao Gong,师从Sanjiv Kumar,关于Sanjiv Kumar可以到她的HomePage上了解。
文章目的:学习保留相似度的二值码,以用于高效的在大规模数据集中做图像检索。本文介绍了在无监督的数据集中用PCA来学习ITQ,在有监督的数据集中用CCA来学习ITQ。
首先介绍学习二值码的重要性:
计算机视觉越来越重视学习相似性保存的二进制代码来代表大规模的图像集合。它主要有三个优点:
(1) 用短的二值码来代图像,可以在内存中存储大量的图像。
(2) 比较两幅图像相似性,用二值码来计算hamming距离,非常快速,高校。
(3) 用这个方法可以代替大规模图像索引方法。
学习二值码有三个重要的特性:
(1) 编码要短。(16G的内存,存储250million图像在内存里的话,对于每图像只能使用64bits)
(2) 图像映射到二值码后,两个编码要尽可能的相似,也就是原来两幅图像距离大,映射到二值码后,hamming距离也很大。
(3) 用来学习二值码的算法要足够的高效,并且对新的图像编码成二值码要efficient。
ITQ的思想:
(1) 用PCA对原始数据进行降维(如果有监督则用CCA来降维)
(2) 然后把把原始数据分别映射到超立方体的顶点,因为超立方体的顶点是二值码,求解量化误差最小的映射方式。量化二值码的方法是:hk(x) = sgn(xwk),用sgn函数来量化。
(3) 本文的创新点是对这个超立方体在空间中旋转,然后求解初旋转矩阵就可以得到最好的映射方式。
(注意:文章不是直接对超立方体进行旋转,而是对数据进行旋转后,再映射到立方体上,相当于物理上运动的相对性,数据旋转,立方体不动,可以看成数据不动,立方体在旋转,一样的道理,文章为了方便求解旋转矩阵,对数据进行旋转。)
对于unsupervised code learning
ITQ 步骤可以简答的概括为(将原始d维向量映射到c维的二值码):
(1)假设数据是centralized,如果不是,用程序进行centralized。X是原始数据(n*d维矩阵),中心化的matlab代码:
sample_mean = mean(X, 1);
X = bsxfun(@minus, X,sample_mean);
(2)将原始数据做一个PCA投影,这一步主要是为了降维。具体PCA降维过程不做过多赘述。
covX = X' * X / size(X,1);
OPTS.disp = 0;
[eigVec, eigVal] =eigs(double(covX), num_bits, 'LM', OPTS);
X = X * eigVec;
(求解离散度矩阵的特征值,选出前C个最大特征值对应的特征向量做为投影矩阵,这样就把原始数据降维到c维)
(3)二值量化
假设第二步求得降维矩阵维W,然后将数据映射到了空间中的一个一个点,现在就是要将空间中的点映射到一个边长为1的超立方体中,以原点为空心,方方正正的放在空间中的超立方体是二值码的(为方面记这个超立方体为Q0)。但如果我们对数据进行一个旋转再映射到这个空间中,会得到更小的量化误差。这个想法类似于如果我们只是要将数据映射到边长为1的立方体中,而不需要固定超立方体的具体位置,这就等同于对数据进行旋转,再映射到以Q0。
降维后的数据:V=XW
旋转后的数据:VR (R是旋转矩阵,必须是c*c维的正交矩阵)
最小化映射误差:
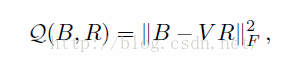
等价于:
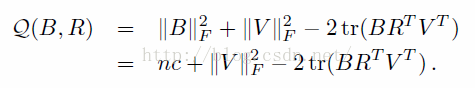
问题等价于最大化:
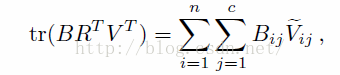
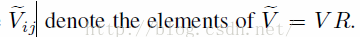
但是这里R也是未知的,B也是未知的,对于求解这样的为题,我们使用迭代求解的方法,固定一个,优化另一个。
求解这个问题分两步:
(1) 固定R,求解B
由于R是正交矩阵,作者使用随机初始化R为正交矩阵。随机的方法:
R = randn(bit,bit); // 随机生成一个矩阵
[U11 S2 V2] = svd(R); //对矩阵做SVD分解,U和V都是正交矩阵
R = U11(:,1:bit); //选取U作为随机初始化的正交矩阵R
R固定了,求解B相当简单。最大化
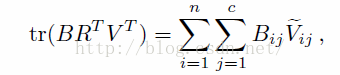
因为这里B的元素只有1和-1(因为是二值码,作者用-1表示0,这样只是为了求解问题简单),所以B =sgn(V R)。
(2) 固定B,求解R
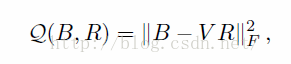
这是一个线性代数的问题orthogonal Procrustes problem。
这个为题的原型是对A做一个正交投影,于B尽量相似:
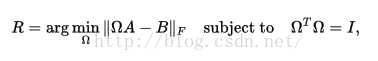

所以本文中,
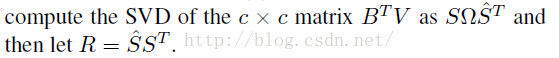
文章迭代求解50步,即可得到最后二值码的编码方式。
% ITQ to find optimal rotation
for iter=0:n_iter
if mod(iter,10)==0
fprintf('ITQ: iter: %d \n', iter);
end
Z = V * R;
UX = ones(size(Z,1),size(Z,2)).*-1;
UX(Z>=0) = 1;
C = UX' * V;
[UB,sigma,UA] = svd(C);
R = UA * UB';
end
% make B binary
B = UX;
B(B<0) = 0;
求得B,R之后,整体的编码方式是:
BincodeXtrainingITQ =compactbit(bsxfun(@minus, Xtraining, sample_mean) * eigVec * R > 0);
利用label信息的ITQ二值码的映射:
给你一个训练集矩阵X,n*d维,一共n个向量,每个向量有d维。现在额外给你一个带标签的矩阵Y,n*t维,你是训练集矩阵的向量个数,t是标签的个数,Y(i,j)=1,表示训练集中的第i个向量和第j个标签有关系。反之Y(i,j)=0表示训练集中的第i个向量和第j个标签没有关系。对PCA比较了解的人都知道,PCA是无监督的降维方法。PCA降维出来的矩阵只是最大限度的保留矩阵的能量,但是不能确保选择的投影pc对于分类是有用的,比如原来的数据是完全可分的,但用PCA降维后完全不可分。所以作者给出了利用带标签的降维方法,CCA。
CCA 的英文全称是Canonical Correlation Analysis,目标是找到特征的投影W矩阵和标签的投影矩阵U,是的投影后的XW和YU的相关性最大。
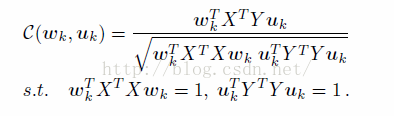
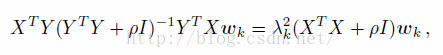
在本文中,作者使用
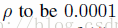
如果我们得到了W,就不用得到U,应为我们得到W的作用是对数据进行降维,而U在以后的ITQ过程中是无用的。
得到降维矩阵后,其余操作和前面相同。