原理的话,使用论文中的图进行说明, 这是论文中的效果图,我们可以看出不管是场景还是人脸都有较好的复原效果

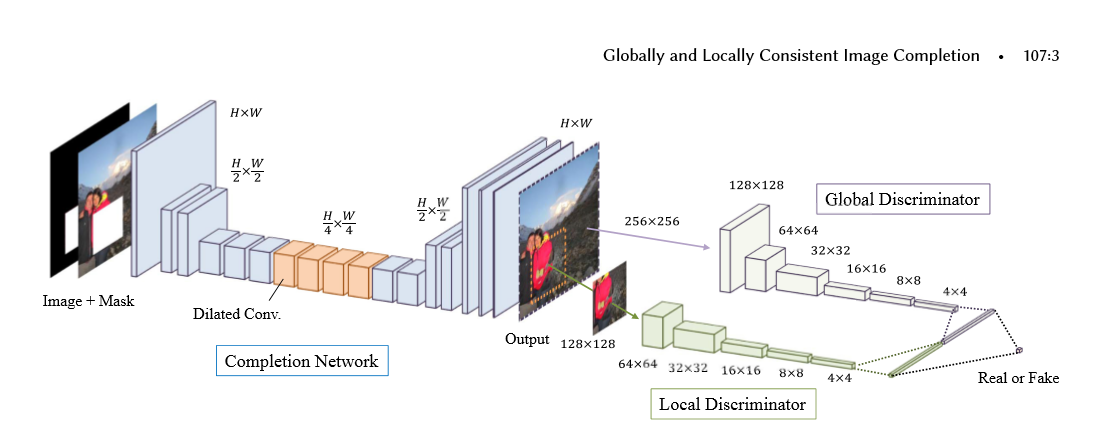
下面是论文的结构图, 主要是有2个结构组成,
第一个结构是全卷机填充网络:首先使用一个mask和图片进行组合,构成了具有空缺的图片,将空缺图片输入到全卷积中,经过stride等于2,做两次的向下卷积,然后经过4个dilated_conv(空洞卷积),为了在不损失维度的情况下,增加卷积核的视野,最后使用补零的反转卷积进行维度的升高,再经过最后两层卷积构成了图片。
第二个结构是global_discrimanator 和 local_discimanator
对于global_x输入的大小为全图的大小,而local_x的输入大小为全图大小的一半,上图的mask的大小为96-128且在local_x的内部,取值的范围为随机值
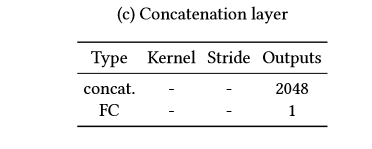
global_x 和 local_x经过卷积后,输出1024的输出,我们将输出进行串接tf.concat,对最后的输出结果[1]进行预测,判别图片为实际图片(真)还是经过填充的图片(假)
网络系数的展示



填充网络(卷积-空洞卷积-反卷积) 全局判别网络(卷积-全连接) 局部判别网络(卷积-全连接) 串接网络(全连接)
训练步骤:为了使得对抗网络训练更加的有效,我们需要先对填充网络进行预训练,然后是对判别网络进行训练,最后将生成网络和判别网络放在一起进行训练

这里说明一下,填充 网络的损失值是mse,即tf.l2_loss() 判别网络的损失值是tf.reduce_mean(tf.nn.softmax...logits)