sed
++++++++++++++++++++++++++++
简介
- Sed是一个逐行读入数据,进行处理后输出到标准输出的非交互式编辑器.
- 优点:流编辑,方便地从管道读入文字,
- 用途
a) 对文档进行批量编辑工作:可以将数据进行替换,删除,新增,选取特定行等功能
b) 对程序的中间过程进行编辑处理:借助管道,自动处理中间结果。 - 注意:Sed只对输入处理,并在标准输出上输出,不改变原有文件内容,如果想保存结果,需要用重定向命令。
使用
-
sed [-nefr] [动作:[n1[,n2]function]] -
动作务必要以两个单引号’’括住
-
n1,n2不见得存在,代表选择进行动作的行数;
-
function:
a) a:新增;
b) c:替换,替换n1 n2之间的行;
c) d:删除;
d) i:插入;
e) p:打印;
f) s:替换,可以直接进行替换工作,可以搭配正则表达式;
g) eg:nl /etc/passwd | sed ‘2,5d’
h) eg:nl /etc/passwd | sed ‘2a drink tea’
i) eg:nl /etc/passwd | sed ‘2a drink tea or……..\
>drink beer ?’
增加两行,每一行之间都必须要以反斜杠\来进行新行的增加; -
以行为单位的替换与显示功能
a)sed ‘2,5c zhangkeluo’:以zhangkeluo替换2到5行;
b)sed –n ‘5,7p’:显示第5,到7行,-n代表“安静模式”; -
部分数据的查找替换功能:s
sed ‘s/被替换的字符串/新的字符串/g’
a) 当新的字符串为空时,相当于删除一个字符串;
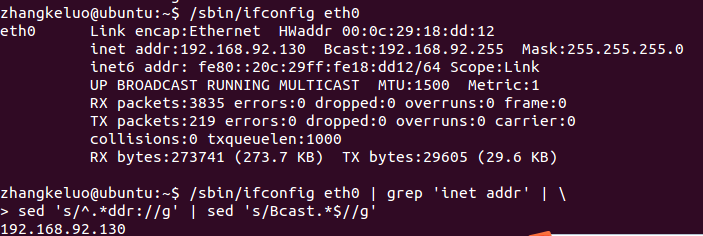
命令:/sbin/ifconfig eth0 | grep ‘inet addr’ | sed ‘s/^.*ddr//g’ | sed ‘s/Bcast.*$//g’
```7. 删除空白行:`sed ‘/^$/d’`
8. 直接修改文件内容(危险操作)
a) `sed –i ‘a #this is a test’ filename` 在文件中添加一行
b) –i 参数直接修改文件的内容,而不是由屏幕输出;
++++++++++++++++++++++++++++
## awk:数据处理工具 ##
## 介绍 ##
1. 是一个**文本分析工具**,对文本文件进行处理以及生成报表。(grep查找,sed编辑)
2. 模式:`awk ‘条件类型1{动作类型1} 条件类型2{动作类型2}….’ Filename`
3. awk可以处理后续接的filename,也可以读取来自前个命令的standardoutput。
4. awk主要处理每一行的字段内的数据,默认的字段的**分割符是空格或[tab]**;
5. 每一行的每个字段都是由变量名称的,`$1/$2/$3……$0代表这一整行`;
6. awk是**以行为一次处理的单位**,而**以字段为最小的处理单位**。
## awk处理流程 ##
1. 读入第一行,将第一行的数据填入$0,$1,$2等变量中;
2. 依据条件类型的限制,判断是否需要进行后面的动作;
3. 做完所有的动作与条件类型;
4. 如果后面还有‘行’数据,重复前三个步骤;
## 调用awk ##
1. **命令行方式**
awk ‘条件类型1{动作类型1} 条件类型2{动作类型2}….’ Filename
eg:`awk ‘BEGIN{FS=”:”} $3 < 10 {print $1 “\t” $3}’`
2. **将所有的awk命令插入一个单独文件,然后调用**:
`awk -f awk-script-file filename` (-f选项加载awk-script-file中的awk脚本)
3. **shell脚本方式**
将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,以便通过键入脚本名称来调用。相当于shell脚本首行的:#!/bin/sh可以换成:#!/bin/awk
## awk内置变量(环境变量) ##
ARGC 命令行参数个数
ARGV 命令行参数排列
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
FNR 浏览文件的记录数
FS 设置输入域分隔符,等价于命令行 -F选项
NF 浏览记录的域的个数
NR 已读的记录数
OFS 输出域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符
## awk运算符 ##
1. 关系运算符:`< ,> ,>= ,<= ,== ,!=`
2. 赋值:`= += -= *= /= %= ^= **=`
3. C条件表达式: `? :`
4. 或 与:`|| &&`
5. 匹配正则表达式和不匹配正则表达式:`~,~!`
eg:`$ awk '$1 ~/^root/' test`将显示test文件第一列中以root开头的行。
6. 字段引用:`$`
7. 数组成员:`in`
## 输出重定向 ##
`print items > output-file` 保存到某文件中
`print items >> output-file` 追加到某文件中
`print items | command` 使用管道交给某些命令处理
特殊文件描述符:
`/dev/stdin`:标准输入
`/dev/sdtout`: 标准输出
`/dev/stderr`: 错误输出
`/dev/fd/N`: 某特定文件描述符,如/dev/stdin就相当于/dev/fd/0
用法示例:
awk ‘BEGIN {printf “%-15s %i\n”,$1,$3 > “/dev/stderr” }’ /etc/passwd
## awk中常见的模式类型 ##
1. Regexp: 正则表达式,格式为`/regular expression/`
2. expresssion:表达式,其值非0或为非空字符时满足条件,如:$1 ~ /foo/ 或 $1 == "magedu",用运算符~(匹配)和~!(不匹配)
3. Ranges: 指定的匹配范围,格式为pat1,pat2 /bash/,/awk/从被/bash/匹配到的行开始到被/awk/匹配到的行结束
4. BEGIN/END:特殊模式,仅在awk命令执行前运行一次或结束前运行一次
(1)BEGIN{ 这里面放的是执行前的语句 }
(2)END {这里面放的是处理完所有的行后要执行的语句 }
(3){这里面放的是处理每一行时要执行的语句}

5. Empty(空模式):匹配任意输入行
## awk中控制语句 ##
1. **if-else**
eg: `awk 'BEGIN {if ($1=="root") print $1, "Admin"; else print $1, "Common User"}' /etc/passwd`
2. **while**
eg: `awk -F: '$1!~/root/{i=1;while (i<=4) {print $i;i++}}' /etc/passwd`
3. **do-while**
4. **for**
eg: `awk -F: '{for(i=1;i<=NF;i+=2) print $i}' /etc/passwd`
for遍历数组中元素:for {A in ARRAY} {print ARRAY[A]}
5. **case**
语法:`switch (expression) { case VALUE or /REGEXP/: statement1, statement2,... default: statement1, ...}`
6. **break continue**
7. **next**: 提前结束对本行文本的处理,并接着处理下一行
## awk中数组 ##
1. 数组的**下标可以是数字和字母**,数组的下标通常被称为关键字(key)。
2. 值和关键字都存储在内部的一张针对key/value应用hash的表格里。
3. **hash不是顺序存储**,因此在显示数组内容时会发现,它们并不是按照你预料的顺序显示出来的。
4. 数组和变量一样,都是在使用时自动创建的,awk也同样会自动判断其存储的是数字还是字符串。
5. 一般而言,awk中的数组用来从记录中收集信息,可以用于计算总和、统计单词以及跟踪模板被匹配的次数等等。
**例如**
awk -F ‘:’ ‘BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}’ /etc/passwd
0 root
1 daemon
2 bin
3 sys
4 Sync
5 games
…
## awk内置函数 ##
1.
split(string, array [, fieldsep [, seps ] ])
功能:将string表示的字符串以fieldsep为分隔符进行分隔,并将分隔后的结果保存至array为名的数组中;
netstat -ant | awk '/:80/{split($5,clients,":");IP[clients[1]]++}END{for(i in IP){print IP[i],i}}' | sort -rn | head -50
2.
length([string])

功能:返回string字符串中字符的个数;
3.
substr(string, start [, length])
功能:取string字符串中的子串,从start开始,取length个;start从1开始计数;
4.
system(command)
功能:执行系统command并将结果返回至awk命令
5.
systime()
功能:取系统当前时间