Tensor
Tensor是PyTorch中重要的数据结构。可认为是一个高维数组它可以是一个数(标量)、一维数组(向量)、二维数组(矩阵)或更高维的数组。Tensor和numpy的ndarray类似,但Tensor可以使用GPU加速。Tensor的使用和numpy及MATLAB的接口十分相似。
import torch as t
from torch.autograd import Variable
#1、构建5*3矩阵,只是分配了空间,未初始化
x = t.Tensor(5,3)
x
>>tensor([[3.8816e-43, 0.0000e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00, 0.0000e+00],
[0.0000e+00, 1.1154e-42, 0.0000e+00],
[0.0000e+00, 1.3553e-19, 0.0000e+00]])
#2、构建全是1的二维数组
x = t.ones(5,3)
print(x)
print(x.size())
>>tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
torch.Size([5, 3])
#3、两Tensor相加
y = t.ones(5,3)
#第一种方法
x+y
#第二种方法
t.add(x,y)
#第三种方法
result = t.Tensor(5,3)
t.add(x,y,out=result)
#4、函数名带下划线_的函数会修改Tensor本身,例如y.add_(x)会修改y,但y.add(x)会返回一个新的Tensor,不会改变y
print(y.add(x))
print(y)
>>tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
print(y.add_(x))
print(y)
>>tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
#5、Tensor和Numpy的数组间的互相操作非常容易且快速。Tensor不支持的操作,可以先转为numpy数组处理,之后再转回tensor
a = t.ones(5)
b = a.numpy()#Tensor->Numpy
print(a)
print(b)
>>tensor([1., 1., 1., 1., 1.])
array([1., 1., 1., 1., 1.], dtype=float32)
import numpy as np
a = np.ones(5)
b = t.from_numpy(a)#Numpy->Tensor
print(a)
print(b)
>>[1., 1., 1., 1., 1.]
tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
#6、Tensor和numpy对象共享内存,所以它们之间的转换很快,而且几乎不会消耗资源。这也意味着,如果其中一个变了另外一个也会随之改变
b.add_(1)#以_结尾的函数会修改自身
print(a)
print(b)
>>[2. 2. 2. 2. 2.]
tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
autograd:自动微分
深度学习的算法本质是通过反向传播求导数,PyTorch的autograd模块实现了此功能。在Tensor上的所有操作,autograd都能为它们自动提供微分,避免手动计算导致的复杂过程。
autograd.Variable 是autograd中的核心类,它简单封装了Tensor,并支持几乎所有Tensor的操作。Tensor在被封装为Variable之后,可以调用它的.backward反向传播,自动计算所有梯度。Variable的数据结构如下图所示:
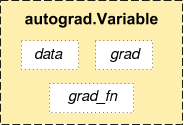
Variable主要包含三个属性:
- data:保存Variable所封装的Tensor
- grad:保存data对应的梯度,grad也是个Variable,而不是Tensor,它和data的形状一样
- grad_fn:指向一个Function对象,这个Function用来反向传播计算梯度的
from torch.autograd import Variable
x = Variable(t.ones(2,2),requires_grad = True)
print(x)
y = x.sum()
print(y)
>>tensor([[1., 1.],
[1., 1.]], requires_grad=True)
tensor(4., grad_fn=<SumBackward0>)
y.backward()#反向传播,计算梯度
x.grad #每个值的梯度都为1
>>tensor([[1., 1.],
[1., 1.]])
#注意:grad在反向传播过程中是累加的,这意味着每次运行反向传播,梯度都会累加之前的梯度,所以反向传播之前需把梯度清零
y.backward()
x.grad
>>tensor([[2., 2.],
[2., 2.]])
x.grad.data.zero()#梯度清零
>>tensor([[0., 0.],
[0., 0.]])
y.backward()
x.grad
>>tensor([[1., 1.],
[1., 1.]])
#Variable和Tensor具有几乎一致的接口,在实际应用中可以无缝切换
x = Variable(t.ones(4,5))
y = t.cos(x)
print(y)
x_tensor_cos = t.cos(x.data)
x_tensor_cos
>>tensor([[0.5403, 0.5403, 0.5403, 0.5403, 0.5403],
[0.5403, 0.5403, 0.5403, 0.5403, 0.5403],
[0.5403, 0.5403, 0.5403, 0.5403, 0.5403],
[0.5403, 0.5403, 0.5403, 0.5403, 0.5403]])
Out[79]:
tensor([[0.5403, 0.5403, 0.5403, 0.5403, 0.5403],
[0.5403, 0.5403, 0.5403, 0.5403, 0.5403],
[0.5403, 0.5403, 0.5403, 0.5403, 0.5403],
[0.5403, 0.5403, 0.5403, 0.5403, 0.5403]])