1.一行代码实现1--100之和
| 1 2 |
|
2、如何在一个函数内部修改全局变量
| 1 2 3 4 5 6 7 |
|
3、列出5个python标准库
os datetime sys re math
4、字典如何删除键和合并两个字典
| 1 2 3 4 5 6 |
|
5、谈下python的GIL
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
6、python实现列表去重的方法(先通过集合去重,在转列表)
| 1 2 3 |
|
7、fun(*args,**kwargs)中的*args,**kwargs什么意思?
| 1 2 3 4 5 |
|
8、python2和python3的range(100)的区别
python2返回列表,python3返回迭代器,节约内存
9、一句话解释什么样的语言能够用装饰器?
函数可以作为参数传递的语言,可以使用装饰器
10、python内建数据类型有哪些
整型--int 布尔型--bool 字符串--str 列表--list 元组--tuple 字典--dict
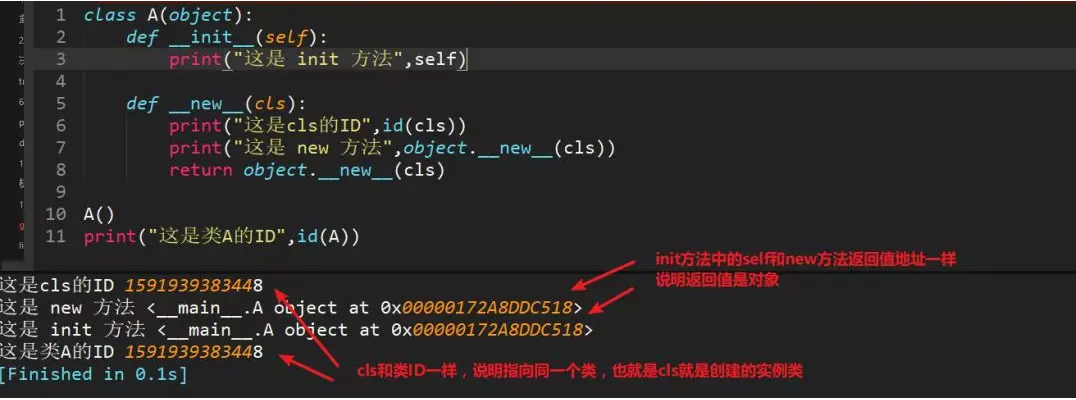
11、简述面向对象中__new__和__init__区别
__init__是初始化方法,创建对象后,就立刻被默认调用了,可接收参数,如图

1、__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别
2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例
3、__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
4、如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。
12、简述with方法打开处理文件帮我我们做了什么?
打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的f.open写法,我们需要try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行finally f.close()关闭文件,with方法帮我们实现了finally中f.close
13、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式([表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件])提取出大于10的数,最终输出[16,25]
| 1 2 3 4 5 |
|
14、python中生成随机整数、随机小数、0--1之间小数方法
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
15、避免转义给字符串加哪个字母表示原始字符串?
r , 表示需要原始字符串,不转义特殊字符
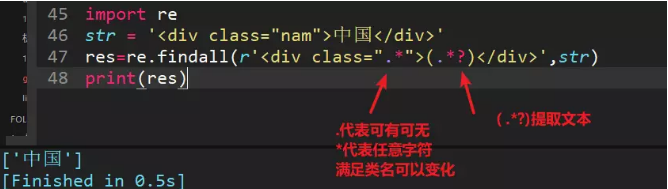
16、<div class="nam">中国</div>,用正则匹配出标签里面的内容(“中国”),其中class的类名是不确定的
| 1 2 3 4 |
|
17、python中断言方法举例
| 1 2 3 4 5 6 |
|
Python的assert是用来检查一个条件,如果它为真,就不做任何事。如果它为假,则会抛出AssertError并且包含错误信息。
18、数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
select distinct name from student
19、10个Linux常用命令
ls(列出目录内容) pwd(显示工作目录) cd(切换目录) touch(建立空文件) rm(删除文件和目录)
mkdir(建立目录) tree(以树状图列出目录的内容) cp(复制命令) mv(移动文件和该文件名)
cat(主要用来查看文件内容,创建文件,文件合并,追加文件内容等功能。) more(显示文件内容,带分页) grep(在文件中查询内容) echo(显示文字)
20、python2和python3区别?列举5个
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2中使用ascii编码,python3中使用utf-8编码
4、python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列
5、python2中为正常显示中文,引入coding声明,python3中不需要
6、python2中是raw_input()函数,python3中是input()函数
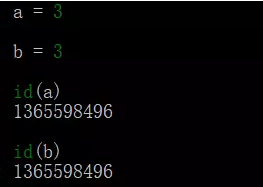
21、列出python中可变数据类型和不可变数据类型,并简述原理
不可变数据类型:数值型、字符串型string和元组tuple
不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址),如下图用id()方法可以打印对象的id:
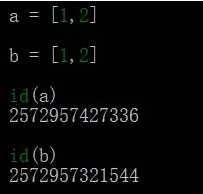
可变数据类型:列表list和字典dict;
允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
22、s = "ajldjlajfdljfddd",去重并从小到大排序输出"adfjl"
| 1 2 3 4 5 6 |
|
23、用lambda函数实现两个数相乘
| 1 2 |
|
24、字典根据键从小到大排序dict={"name":"zs","age":18,"city":"深圳","tel":"1362626627"}
| 1 2 3 4 5 |
|
25、利用collections库的Counter方法统计字符串每个单词出现的次数"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
| 1 2 3 4 5 6 7 |
|
26、字符串a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳"
| 1 2 3 4 5 6 7 8 9 10 11 |
|
27、filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
| 1 2 3 4 5 6 |
|
28、列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
| 1 2 3 |
|
29、正则re.complie作用
re.compile是将正则表达式编译成一个对象,加快速度,并重复使用
30、a=(1,)b=(1),c=("1") 分别是什么类型的数据?
| 1 2 3 4 5 6 |
|
31.两个列表[1,5,7,9]和[2,2,6,8]合并为[1,2,2,3,6,7,8,9]
| 1 2 3 4 5 6 |
|
32、用python删除文件和用linux命令删除文件方法
python:os.remove(文件名)
linux: rm 文件名
33、log日志中,我们需要用时间戳记录error,warning等的发生时间,请用datetime模块打印当前时间戳 “2018-04-01 11:38:54 星期:”
| 1 2 3 |
|
34、数据库优化查询方法
外键、索引、联合查询、选择特定字段等等
35、请列出你会的任意一种统计图(条形图、折线图等)绘制的开源库,第三方也行
pychart、matplotlib
36、写一段自定义异常代码
| 1 2 3 4 5 6 7 8 9 |
|
37、正则表达式匹配中,(.*)和(.*?)匹配区别?
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
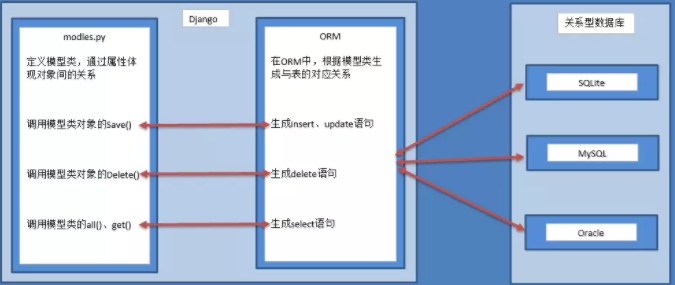
38、简述Django的orm
| 1 2 |
|
39、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
40、x="abc",y="def",z=["d","e","f"],分别求出x.join(y)和x.join(z)返回的结果
| 1 2 3 4 5 6 7 8 9 10 |
|
41、举例说明异常模块中try except else finally的相关意义
try..except..else没有捕获到异常,执行else语句
try..except..finally不管是否捕获到异常,都执行finally语句
42、python中交换两个数值
| 1 2 3 |
|
43、举例说明zip()函数用法
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
44、a="张明 98分",用re.sub,将98替换为100
| 1 2 3 4 |
|
45、写几条常用sql语句
| 1 2 3 4 5 6 7 8 9 10 11 |
|
46、a="hello"和b="你好"编码成bytes类型
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
47、[1,2,3]+[4,5,6]的结果是多少?
| 1 2 3 |
|
48、提高python运行效率的方法
1、使用生成器,因为可以节约大量内存
2、循环代码优化,避免过多重复代码的执行
3、核心模块用Cython PyPy等,提高效率
4、多进程、多线程、协程
5、多个if elif条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
49、简述mysql和redis区别
redis: 内存型非关系数据库,数据保存在内存中,速度快
mysql:关系型数据库,数据保存在磁盘中,检索的话,会有一定的Io操作,访问速度相对慢
50、遇到bug如何处理
1、细节上的错误,通过print()打印,能执行到print()说明一般上面的代码没有问题,分段检测程序是否有问题,如果是js的话可以alert或console.log
2、如果涉及一些第三方框架,会去查官方文档或者一些技术博客。
3、对于bug的管理与归类总结,一般测试将测试出的bug用teambin等bug管理工具进行记录,然后我们会一条一条进行修改,修改的过程也是理解业务逻辑和提高自己编程逻辑缜密性的方法,我也都会收藏做一些笔记记录。
4、导包问题、城市定位多音字造成的显示错误问题