第三十二周学习笔记
CS231n
翻译自英文笔记
损失函数
数据损失(data loss)是预测与真实标签的一致性度量,往往的表达式是
其中, 是训练集数据的数量,记 为输出层的激活函数,以下是一些实际中面对的问题
分类,两个最常见的损失函数之一是SVM
一些人在squared hinge loss中取得了更好的结果:
另一个常见的损失是交叉熵损失:
问题:大量的类别,当类别特别多的时候(比如英语字典或ImageNet的22000个类别),使用Hierachical Softmax更好,详见这篇文章,hierachical softmax将标签解析为树,每个标签继而表达为树上的一个道路,然后Softmax分类器在树上的每个节点上训练来区分左右分支,树的结构很大程度地影响了模型的表现,其结构也取决于问题本身
属性分类,之前的损失都假定只有一个正确的标签
,但如果
是一个二进制向量,以表示每个样本有或没有某个属性呢?比如,Instagram上的图片可以被认为被标记了多个主题标签(#标签),所有的标签是一个很大的标签集合,对于这个问题,一个合理的解决方法是在每个标签上建立一个二分类器,比如,一个独立的二分类器:
其中求和是在所有类别 上进行, 非1即-1,取决于第i个样本有没有第j个属性,得分向量 为正——当预测为第 个标签的存在,否则为负。注意损失会累积在以下情况,如果正样本的得分少于1,或负样本的得分大于-1
另一种方法是对每个属性独立地训练一个logistic regression分类器,一个二分类logistics regression分类器仅有两个类别(0,1),并计算类别为1的概率:
由于概率为1和0的和为1,类别为0的概率为
,因此若
(或等价地
),一个样例被分类为正(y=1),损失函数继而最大化对数似然:
其中 非1即0,且 是sigmoid函数,上式子可能很复杂,但梯度却很简单,
回归是预测实值标签的任务,比如房价或图像中某物的长度,对于这个任务,通常计算预测与真实值之差,然后使用L2范数的平方而L1范数来度量,L2范数平方:
使用平方的原因是这样梯度会变得十分简单,并不会改变最优参数,因为平方是单调运算。L1范数:
其中 是对预测的每一维的加和
注意:L2 loss比Softmax更难优化,直观地看,L2 loss需要一个网络的敏感和具体的特性,使得输出恰恰与输入值相同。注意Softmax并非如此,每个得分的精确性相对不重要:仅仅需要它们的数量级合适。此外,L2 loss鲁棒性更差,因为异常值会引入巨大的误差。当面对回归问题是,首要的考虑是是否能将之输出转化为二进制,比如,如果你预测一个产品的星级,可能使用五个独立的为1-5星的分类器相比使用回归更合适,分类的一个额外的好处是它可以给你回归输出的分布,而不仅仅是一个输出值,而没有它的可信度,如果你确认分类是不合适的,小心地使用L2损失,L2更脆弱,且在网络中使用dropout(特别是在L2 loss边)不是一个好的主意。综合而言,L2 loss:
- 难优化,因为需要很大的精确度
- 鲁棒差,因为异常点引入巨大误差
- 信息少,相比分类给出的类别及类别概率输出而言,单纯的实值输出的可信度未知
- 不宜使用dropout
当面对一个回归问题时,首先考虑回归的绝对必要性,其次强烈建议将输出转化为二进制并使用分类
结构化预测(Structured prediction),结构损失指代label可以是任意结构,比如图、树或其他复杂的对象,通常结构的空间十分大而无法穷举。结构化SVM的背后思想是需要正确结构 与最高得分的错误结构有一个间隔(margin),通常不会用梯度下降来以一个非限制优化问题来解决这样的问题,相反,设计特殊的solvers以利用结构空间的特性。
翻译自英文笔记
梯度检查
使用中心表达式,对比数值梯度和解析梯度有两种方法
其中 是一个小的值,通常为1e-5,第二种形式是更加建议的,因为其误差为 ,具体检查时,需要使用相对误差来避免梯度量级带来的影响,且网络越深,误差会越大
另外需要注意的是
- 使用双精度,使用单精度会大大增加误差
- 保持在浮点数的有效范围(阅读材料)
- 目标函数的不可导点(kinks),注意目标函数中max等函数的不可导性,记录数据的流向,单独计算其梯度
- 只使用少量数据点,因为kinds随数据减少而减少
- 注意h的大小,并非越小越好,注意调整
- 在“有特点”的模式下检测,存在梯度检查看似正确实际病态的情况,这是由于错误的数值梯度在模型初期不易被察觉的原因
- 不要让正则项覆盖了data,正则化损失超过数据损失的结果是很严重的,这样使得梯度主要由正则化项的梯度组成,这会掩盖数据梯度的损失,因此检查的时候通常不使用正则化,然后单独检测正则化损失的梯度,后者的两种方法是减去数据损失或给正则化项加权
- 记得关闭dropout和augmentation
- 只检测少数维度
训练之前:合理检查的指南
进入耗时的优化之前,需要进行以下的检查
- 检查初始化的损失值:在初始化参数之后,确保得到了期望的损失,最好的方法是先单独检查数据损失(设定正则化为0),例如,对于CIFAR-10的Softmax分类器,我们期望的初始化损失为2.302,因为我们期望初始化时10个类别的预测值都约是0.1,因此-ln(0.1)=2.302,如果不符合预期,则初始化可能出了问题
- 提升正则化权重会提升损失
- 过拟合一个小的数据集,在你和整个数据集之前,拟合一个小的数据集(比如20个样本)并确保得到了一个0误差的模型,此时最好设置正则化参数为0,否则会阻止你到0误差。除非你进行了这样的合理化检查,否则不应在整个数据集上进行训练,但即便通过这个检查,也不一定说明模型就没有问题。
照顾好学习进程
画图,横轴是训练误差
损失函数
损失值是一个训练过程中值得跟踪的值,因为它记录了独立的batches在前向过程中的表现,下图是一些例子
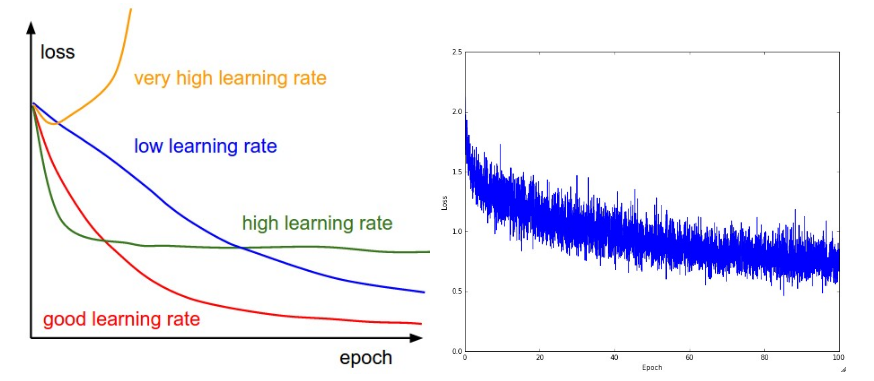
左图是不同的学习率的误差曲线,右图是cifar10上的一个神经网络的损失变化,右图中的batch size可能较小,因为损失的噪声很大
损失的摆动与batch size有关,当batch size是1的时候,摆动会十分地高,当batch size是整个数据集的时候,摆动就会十分小,因为每次梯度更新通常单调地降低梯度
一些人偏好对损失函数做log,然后再画出来,因为损失函数往往看起来像一个指数函数,这样可以使之成为一条直线,此外这样做也能使得交叉验证的模型的损失画在一起时,差异更明显
训练/验证准确率
第二个重要的跟踪指标是验证/训练准确率,这帮助避免过拟合

训练和验证误差的gap代表了过拟合的程度,出现这种情况时需要增加正则项的权重或获取更多数据,另一种情况是训练误差和验证误差几乎处处相同,这时需要增加参数使模型表达能力更强
权值比例:更新
最后一个需要跟踪的量是更新与值的量级比例,注意:更新,而非原始的梯度(在随机梯度中就是梯度和学习率的乘积)。你可能想为了每个参数集合独立地验证并跟踪这个比例。一个粗略的启发式方法是这个比例应该在1e-3左右:
# assume parameter vector W and its gradient vector dW
param_scale = np.linalg.norm(W.ravel())
update = -learning_rate*dW # simple SGD update
update_scale = np.linalg.norm(update.ravel())
W += update # the actual update
print update_scale / param_scale # want ~1e-3
激活/梯度在每层的分布
一个错误的初始化会减缓甚至停止学习进程,幸好这个问题也相对容易被诊断出,一个方法是为每层画出激活/梯度图直方图,直观上看,没有看到任何奇怪的分布是好的表现(比如,有tanh neurons时看到的激活单元应该充满[-1,1]这个区间),而非全0或全饱和在-1或1
第一层可视化
最后,如果是关于图像的网络,画出第一层特征是有很有帮助的:

第一层权值的可视化,左:噪声特征,可能因为:未收敛、错误的学习率、低的正则化乘法权值。右:好的、平滑的、干净的、多样的特征,表面学习很好
权值更新
本节列出一些常见的优化技术,并简介其动机,并省略细节的分析
随机梯度下降(SGD)和铃声和口哨
Vanilla update,最简单的更新方法是将参数向负梯度方向改变(因为梯度方向是增长最快的方向,而我们想最小化函数),若参数x梯度是dx,那最简单的更新方法是:
x += - learning_rate *dx
其中learning_rate是一个超参数 - 一个固定值,当在整个数据集上训练且学习率相对小时,这可以保证使得损失函数单调下降
动量(Momentum)更新是另一种大多情况更容易收敛的方法,这中更新策略是从物理引入优化理论中的,实际中,损失函数可以被解释为一个丘陵地区,随机初始化参数等价于在某个位置放置一个速度为0的质点,优化的过程可视为模拟参数的向量(即质点)在丘陵上滚动的过程。
由于质点上的力与势能的梯度相关(比如 ),质点感到的力就是损失函数的负梯度,此外,由于 ,所以这里的梯度与质点加速度成正比。注意这与SGD更新不同,SGD中的梯度仅仅影响位置,而这里,物理上的观点是梯度影响速度 ,而速度进而影响位置:
v = mu * v - learning_rate * dx
x += v
这里的变量v被初始化为0,且有了额外的一个参数mu,非正式地说,这个值就是动量(通常是0.9),但是它的物理意义与摩擦力系数更一致。这个变量高效地抑制速度并降低系统的动能,否则质点永远不会到达底端,在交叉验证时,这个参数通常被设置为[0.5,0.9,0.95,0.99]。与退火的学习率相同,当动量在后续的学习阶段中增加时,优化有时会从动量中得到好处,加,一个常见的设置是将其设置为0.5,然逐渐退火到0.99左右
使用动量更新,参数会在和吹吹有梯度的某个方向累积速度
Nesterov 动量与动量更新有一些不同,最近也变得流行起来,它有强的理论保证凸函数的收敛且实际上它一致优于标准的动量方法。
Nesterov动量方法的核心思想是,当参数向量在某个点x时,观察之前的动量更新式子,单独看动量(忽略第二项的梯度)将通过mu * v推动参数向量。因此如果我们要计算梯度时,我们可以将一个未来的大致位置x+mu*v看作是一个目测——这是我们即将到达的附近的点,因此,通过x+mu*v来计算梯度相比旧的位置更好
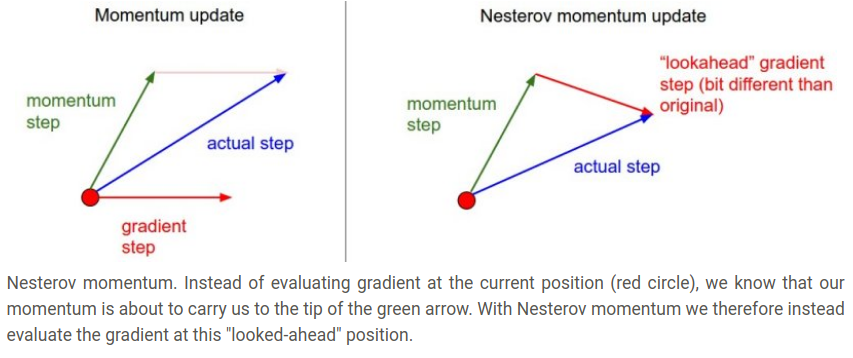
如下所示
x_ahead = x + mu * v
# evaluate dx_ahead (the gradient at x_ahead instead of at x)
v = mu * v - learning_rate * dx_ahead
x += v
然而实际中人民偏好将更新尽可能表达地像vanilla SGD或之前的动量方法,通过变量变换即可做到x_ahead = x + mu * v,然后以x_ahead代替x即可,因而我们存储的参数实际上是ahead版本的,则关于x_ahead(重命名为x)的计算公式为:
v_prev = v # back this up
v = mu * v - learning_rate * dx # velocity update stays the same
x += -mu * v_prev + (1 + mu) * v # position update changes form
退火学习率
在训练深度神经网络时,通常退火学习率是十分有效的,直观看,更高的学习率的系统有太多动能,参数会因此乱跳,无法在更深、更狭窄的目标函数值处稳定下来,选择衰减学习率的时间是十分技巧性的:衰减太慢会浪费计算资源在参数乱跳的过程中,太快又会让系统冷却过块,无法到达最优位置。以下是常见的学习率衰减的方法:
- 步长衰减:在每几轮后根据某个因子衰减学习率,典型的值为每5轮降低一半,或每20轮降低0.1,这些数字取决于问题和模型,一个启发的方法是你可以根据验证误差来修正学习率,每当验证误差不再下降时,衰减一个常数值(0.5)
- 指数衰减:数学公式是 ,其中 是超参数, 是迭代次数(也可视作轮次)。
- 1/t 衰减的数学公式是 其中 是超参数, 是迭代次数
实践中,我们发现步长衰减通常更被偏好,因为超参数的解释性更强(衰减比例和以周期为单位的衰减步长),相对后两者的超参数 来说,最后如果你可以负担计算资源的重担,应该宁可衰减慢一点训练久一点。
二阶方法
一些二阶的优化算法是基于牛顿法,更新公式为
其中,
是Hessian(黑塞矩阵),是函数的二阶偏导数矩阵,
是梯度向量,直观地看,Hessian描述了损失函数的局部曲率,这使得更新更加高效。实际中,乘以Hessian矩阵的逆矩阵导致优化过程在小曲率时大步前进,在曲率大时小步前进。注意,这个式子中没有任何超参数,这是相比一阶方法的一个大的优势
但是,上述的更新方法对于很多深度神经网络是不切实际的,因为计算并取逆一个Hessian在无论空间还是时间上造成极大的消耗,例如,一个1百万个参数的神经网络会有一个[1,000,000×1,000,000]的Hessian矩阵,占约3725gigabytes(每个浮点数32bit=4byte,100000010000004/1024/1024/1024)的内存,因此,一大堆拟牛顿法出现了,为的就是估计Hessian的逆,其中最流行的是L-BFGS,它使用了不同时间的梯度来得到逆Hessian的大概估计
然而,尽管抛开内存不谈,单纯的L-BFGS方法的一个大的缺点是其必须在整个训练集上计算,而训练集通常有数百万个样例,与mini-batch SGD,使得L-BFGS在mini-batch上运行是更加tricky的
实践中,通常不使用L-BFGS或类似的二阶方法来优化大规模的神经网络和卷积网络,相反,SGD的一些基于动量的变种更加受青睐,因为它们简单且容易扩展。
逐参数适应学习率方法
之前的方法都是全局调整学习率,对所有参数一视同仁。调整学习率是一个非常耗时耗力的工作,很多适应的调整方法被相继提出,甚至逐个参数调整,其中许多需要额外的超参数设定,但结论是它们的表现都很好——当在一个大的超参数集合中找到答案,相比于原来而言。本节我们将强调一些实践中可能碰到的适应方法
Adagrad是一个适应学习率方法,最初由Duchi等人提出
# Assume the gradient dx and parameter vector x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
注意cache与梯度的尺寸相同,并且跟踪每个参数的平方和。这继而用来进行逐个元素的更新操作。注意到有大梯度的权值的学习率将会下降,反之则上升,有趣的是,开平方的操作是这个算法中重要的元素,没有则会表现奇差。平滑项eps(通常是1e-4到1e-8之间)是避免分母为0的。Adagrad在深度学习中的缺点是,单调的学习率会十分激进并很早停止学习
RMSprop,RMSprop是一个非常高效的,但到目前都没公开发表的适应学习率方法。有趣的是,每个使用这个方法的人都引用了这个,是Cousera上的一个课件,RMSProp用一种简单的方法调整了Adagrad以减少它的激进的、单调递减的学习率。实践中,它使用平方梯度的移动均值:
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
其中decay_rate是一个超参数,通常取[0.9,0.99,0.999],注意到x+=的更新是与Adagrad相同的,但是’cache’变量是不同的。因此,RMSProp仍然取决于梯度的量级来更新每个权重的学习率,与Adagrad不同,不会让学习率单调下降
Adam是一个近期提出的看似加上动量的RMSProp的方法,其简化更新如下
m = beta1*m + (1-bata1)*dx
v = beta2*v + (1-beta2)*(dx**2)
x += -learning_rate * m / (np.sqrt(v) + eps)
注意到更新与RMSProp几乎相同,除了使用平滑的m而非dx,超参数往往设置为eps = 1e-8, beta1 = 0.9, beta2 = 0.999。实践中Adam是建议的默认优化算法,通常效果略优于RMSProp,然而,SGD+Nesterov动量法也值得一试。整个Adam更新也包括一个偏置矫正机制,用以步长m、v最开始被初始化为0,通过偏置矫正机制,更新过程如下:
# t is your iteration counter going from 1 to infinity
m = beta1*m + (1-beta1)*dx
mt = m / (1-beta1**t)
v = beta2*v + (1-beta2)*(dx**2)
vt = v / (1-beta2**t)
x += - learning_rate * mt / (np.sqrt(vt) + eps)
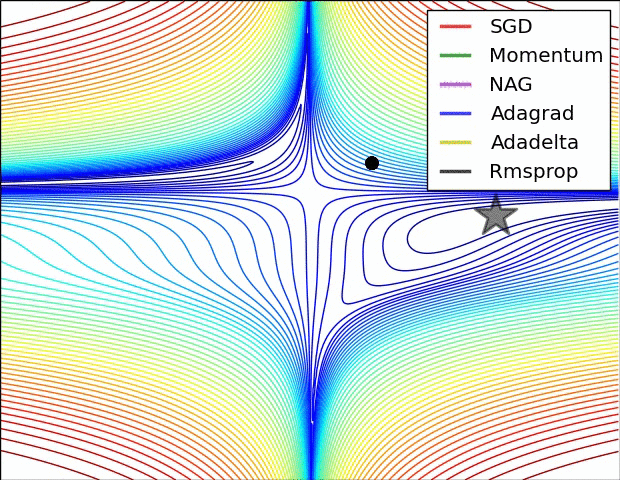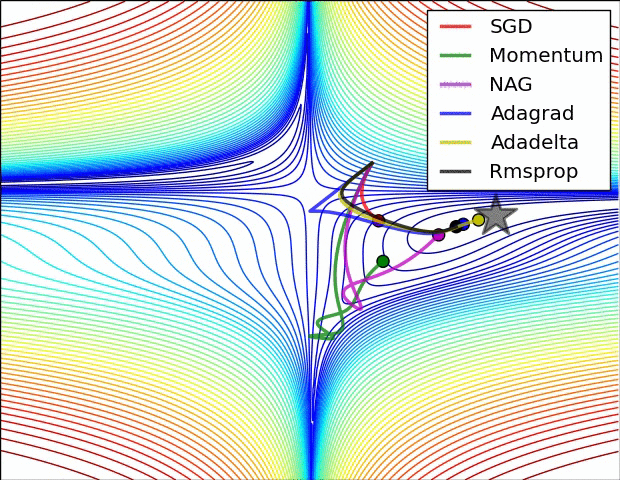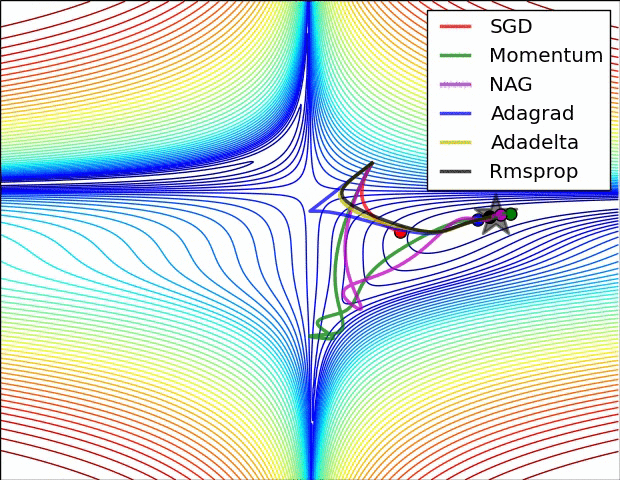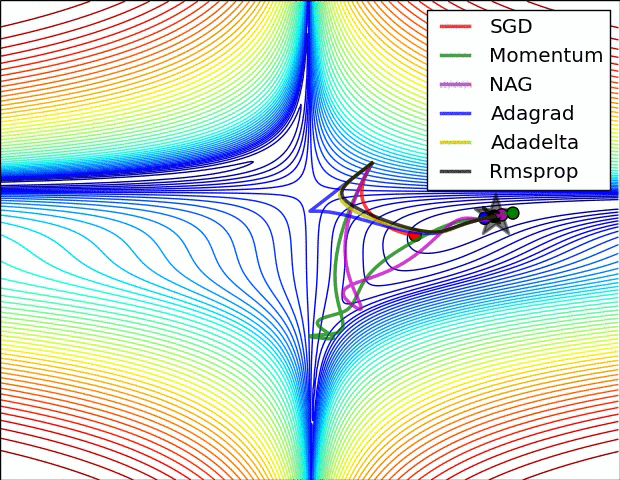
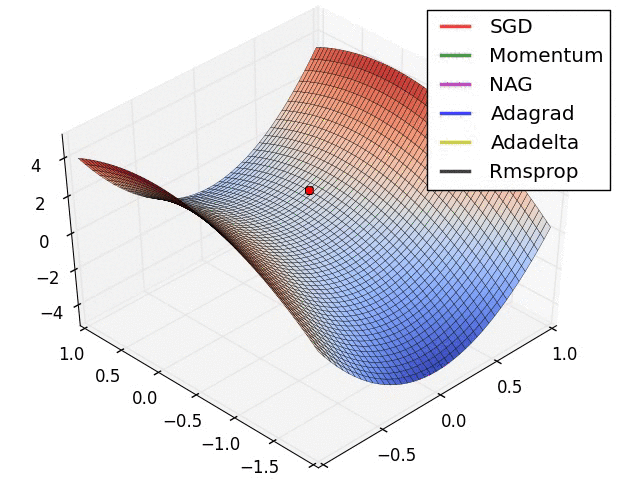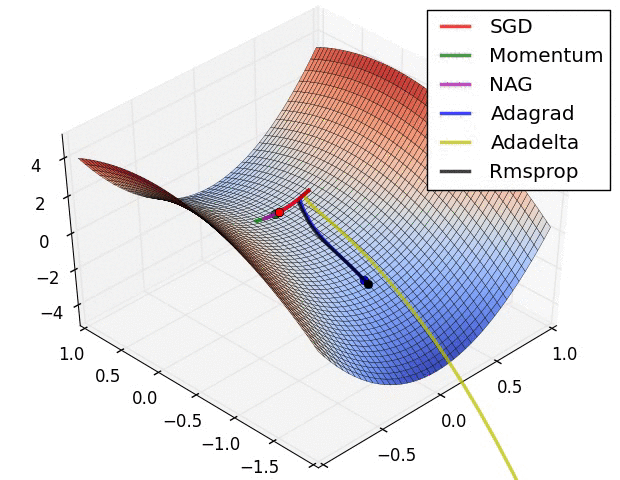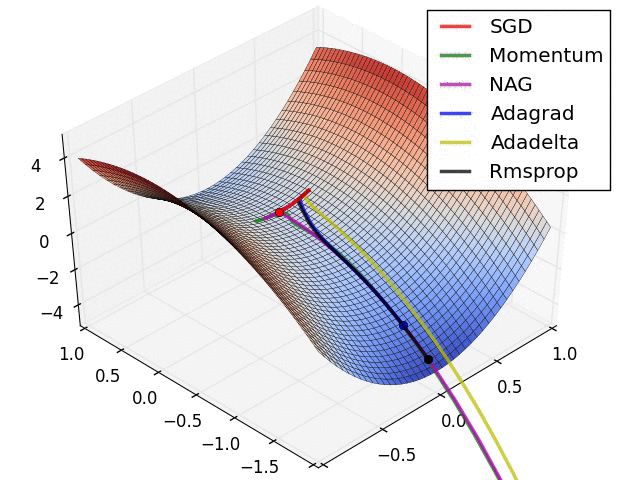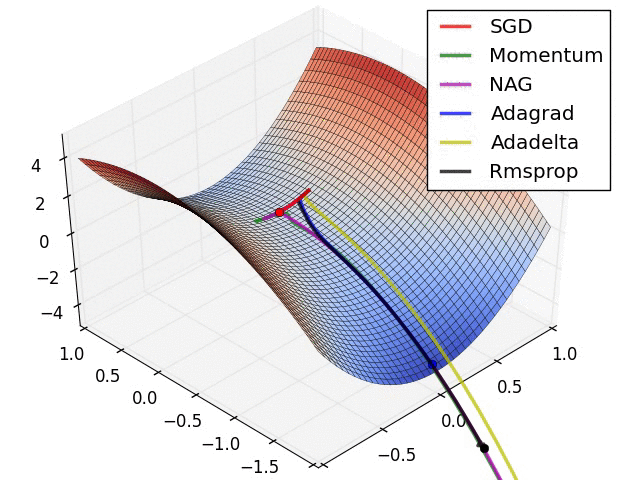
以上是不同学习方法的对比,左图:注意基于动量的方法的"overshooting"的特点,就像一个球沿着坡越滚越快的感觉,右图:这是一个马鞍面,注意SGD难以打破网络的对称性而卡在顶部,相反,RMSprop等方法在马鞍方向的梯度很小,由于RMSProp更新中的分母项,这会增加这个方向的学习率,使得RMSProp前进,图片来源:Ale Radford
超参数优化
训练神经网络会引入大量超参数,通常有以下几类
- 初始学习率
- 学习率衰减方式(比如常数衰减)
- 正则化强度(比如L2惩罚,dropout强度)
但如我们所见,有很多相对不易察觉的超参数,比如,在适应学习方法中,动量和其方法的设定等。本节我们将给出一些额外的好的超参数搜索方法:
实现,大规模神经网络通常需要很长时间来训练,因此寻找超参数需要很长很长时间,这点需要时刻记住,因为这影响了你代码的设计,一个可能的设计是用一个狗腿子来不断从超参数中随机采样,并进行优化,根据训练,狗腿子会跟踪每轮的验证表现,并写出模型的checkpoint(以及各种训练过程中的统计值)到一个文件中,更好的是一个共享的文件系统中。通常将验证表现包含在文件名是有帮助的,这样容易对这些文件排序,然后使用第二个程序大王,它能呼唤或踹走狗腿子,亦可以影响狗腿子写的checkpoint,并画出它们的训练统计量等
一个验证集比交叉验证更好:很多情况下简单的一个足够大的验证集大大简化了代码,而不用交叉验证很多折,你可能听说别人交叉验证了一个参数,但往往它们仅仅使用了一个验证集
超参数范围:在log规模上搜索一个超参数,比如,一个通常的采样方法会是learning_rate = 10 **uniform(-6,1)。即我们从均匀分布中生成随机数,然后作为10的指数。对于正则化强度也是一样。直观上看,这样做是因为学习率和正则化强度在训练的动态中是乘法的作用。比如,学习率由0.001额外加上0.01会造成很大的影响,但若学习率是10则几乎没有影响。这是因为学习率与梯度相乘,因此更自然的想法是超参数在乘或处上的变化,而不是加或减,不过某些超参数(比如dropout)是在原来的尺度上 搜索(比如 dropout = uniform(0,1))
随机搜索比网格搜索更好,如Bergstra和Bengio在Random Search for Hyper-Parameter Optimization中论证的:“随机选择的方法比网格搜索更高效”,这一点也容易说明
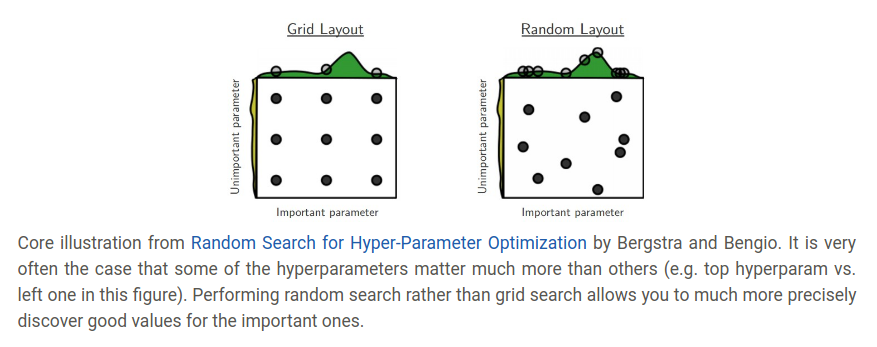
注意边缘上的最有值,有时你可能在一个不好的范围内搜索超参数(比如 学习率),举个例子,若我们使用learning_rate = 10 ** uniform(-6,1),当我们看到结果后,我们要确定最后的学习率不在这个区间的边缘上,否则你可能忽略了在这个区间之外的更好的超参数
从粗调到微调,实践上,大略的搜索是有帮助的(比如 10**[-6,1]),然后根据最好的结果的位置,缩小搜索范围。最初的搜索可以只训练一轮或更少,因为很多参数根本无法让模型学习,或瞬间让损失爆炸多,第二轮在训练5轮,最后在小的范围内仔细地搜索
贝叶斯超参数优化是一整个领域,提出了算法来更有效地在超参数空间中漫游的方法,核心方法是近似平衡搜索——在不同超参数的表现中权衡,很多基于这些模型库已经被开发了出来,其中有名的有Spearmint,SMAC和Hyperopt,然后,实践上它仍然难以击败卷积网络的好的间隔搜索。
评估
模型集成
实践中,提升网络表现少许百分点的一个可靠的方法是训练多个独立的模型,并在测试时平均它们的预测值,集成的模型越多,表现通常单调上升(尽管提升越来越少),此外,模型越多样,表现越好,以下是几种方法:
- 一个模型,不同的初始化,使用交叉验证确定最好的超参数,然后使用这组参数训练不同初始化的模型,缺点是多样性仅依赖初始化
- 交叉验证中得到的最好的几个模型,使用交叉验证确定最好的超参数,然后选择最好的几个模型(比如 top 10),这增加了多样性但会引入次优的模型,实践中,这往往更容易因为它不需要交叉验证后直接可以使用,不用重新训练了
- 一个模型的不同checkpoints,如果训练代价很大,一些人会集成不同checkpoints的模型以取得少量的进步,但这样缺少多样性,但实践中也勉强可以,这个方法的优势是十分节约计算资源
- 与上一点相关,一个最cheap的方法是将网络的参数拷贝到内存中,并在训练过程中维持一个指数衰减的求和。这样平均了各次迭代中的网络,你会发现这种利用几轮结果平滑的网络在验证集上表现更好,关于这个方法的直觉是目标函数是碗状的而你的模型在模型周围跳动,因此平均之后更可能接近底端
集成方法的缺点是测试的时候需要更多的时间,感兴趣的读者可以发现Geoff Hinton关于"Dark Knowledge"很有启发性,这种方法通过合并集成的对数似然到目标函数中,从好的集成模型中提炼出单个模型
总结
为了训练一个网络
- 使用小批数据检查梯度,并避免陷阱
- 合理性检查,确保初始损失是合理的,并可以在小规模数据上达到100%的准确率
- 训练过程中,监视损失以及训练和验证准确率,也可检查参数更新的比例(应该是1e-3)
- 使用随机搜索(而非网格搜索)找到好的超参数,搜索时从粗略到精细(粗略搜索时可以只训练1-5轮,精细时缩小参数范围,训练更多轮)
- 形成集成模型来提高性能
论文阅读
Batch Normalization:Accelerating Deep Network Traning by Reducing Internal Covariate Shift
概括
BN减少了internal covariate shift,后者指代训练过程中数据经过每层后发生的分布变化,因为每层微小的参数更新即会影响其输出的数据的分布,而随着网络越深,这种影响会越来越大,使得学习率设置和网络初始化时我们要谨小慎微,对越深的网络尤是如此,而BN的引入减少了internal covariate shift,从而使得网络更容易初始化、可以使用更大的学习率、网络更快收敛、减少了饱和非线性单元造成的梯度弥散作用、作为正则化使用(可能不需要Dropout)
文章解决了什么问题
一些定义
covariate shift means the input distribution to a learning system changes
internal covariate shift means the distribution of each leayer’s inputs changes during training, which slows down the training by requiring lower learning rates and careful parameter initialization, and makes it notoriously hard to train models with saturating nonlinearities.
问题
small changes to the network parameters amplify as the network becomes deeper
The change in the distributions of layers’ inputs presents a problem because the layers need to continuously adapt to the new distribution
用了什么方法
Batch Normalization: Take a step towrads reducing internal covariate shift to accelerate the trainning of deep neural nets normalizing layers inputs
Batch Normalizing Transform:

operate independently on each feature of
Any layer that previously received as input,now receives
At inference time:

效果如何
-
【Higher learning rate】allow us to user much higher learning rates and
-
【less bother when initializing】make us less careful about initialization
-
【call back saturating nonlinearities】makes it possible to user saturating nonlinearities by preventing the network from getting stuck in the saturated modes
-
【Fater training】applied to a state-of-the-art image classification model, Batch Normalization achieves the same accuracy with 14 times fewer training steps, and beats the original model by a significant margin
-
【some invariance】has a beneficial effect on the gradient flow through the network by reducing the dependence of gradients on the scale of the parameters or of their initial values,allows us to use much higher learning rates without the risk of divergence. Back-propagation through a layer is unaffected by the scale of its parameters
and
The scale does not affect the layer Jacobian nor, consequently, the gradient propagation. Moreover, larger weights lead to smaller gradients, and Batch Normalization will stabilize the parameter growth. -
【Regularization】Act as a regularizer, in some cases eliminating the need(or strength) for Dropout
-
【In practice】using an ensemble of batch-normalized networks, improve upon the best published result on ImageNet classification:reaching 4.9% top-5 validation error(and 4.8% test error),exceeding the accuracy of human raters.
存在什么不足
文中似乎没有给出一些不足之处
其他
1.mini-batch的好处
- mini-batch相对单个样本来说,是对总体的损失值的更好的估计,batch size越大,估计越准确
- mini-batch相比单个样本训练更快,因为可以使用并行
2.BN理论上不会使得网络表现更差
当
时,BN是一个恒等变换,这使得网络(理论上)至少不会变差
3.卷积网络上的BN
卷积网络中为了与卷积的特性一致,对于每个激活图分配一个
和
,而非之前的对每个激活单元分配一个
和
,此时若激活图是
的,就有$m’=mpq $
4.BN层放在哪
文中辨析了给定一层
那么究竟是对
进行BN还是对
进行BN?
由于
一般是其他非线性层的输出,它的分布形状在训练中在训练中可能会变化,且限制它的一阶和二阶矩不会消除covariate shift,而
更可能有对称、非稀疏的分布,更加Gaussian(文中此处有引用),将其正规化更可能让激活单元有一个稳定的分布
Future Work
- 在RNN上应用BN
- 检测BN是否能帮助domain adaptation——whether the normalization performed by the network would allow it to more easily generalize to new data distributions,perhaps with just a recomputation of the population means and variances
问题
1.为什么不是0
文章中
但因为
就有
那第二项就为0,进过实际计算,也是如此,那为何要将其写在公式中
2.一些单词
- inference,可能指网络测试时
- population,可能指训练集全集
本周反思
- 阅读resnet的论文,未完成,但是阅读了BN的论文作为替代
- 继续完成cs231n的学习进度到50%,完成
- 学习opencv上册到25%,完成到14.6%,。
下周目标
- 阅读resnet的论文
- 继续完成cs231n的学习进度到75%
- 学习opencv上册到50%