Spark实现 – Kmeans聚类算法
Kmeans简介
Kmeans是最常用的聚类算法,也是十大经典的数据挖掘算法之一。聚类的思想用一句话概括就是“物以类聚,人以群分”。kmeans算法作为最基础的算法之一,基本上每本数据挖掘的书都会讲到,这里就不在啰嗦了。本文主要结合实现原理利用Spark实现一下过程。
算法实现步骤
step1 首先随机选取k个样本点最为初始聚类中心
step2 计算每个样本到聚类中心的距离,将该样本归属到最近的聚类中心
step3 将每个类的点的均值作为新的聚类中心
step4 重复2、3步骤直到代价函数不再发生较大大变化或达到迭代次数
Kmeans动态过程
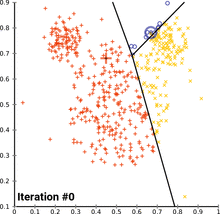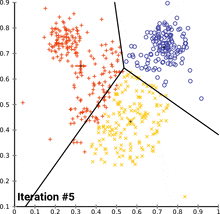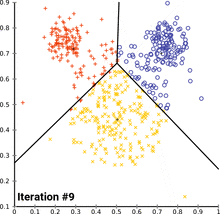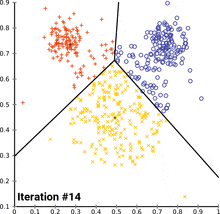
图片来源:维基百科
代码实现
// 定义一个方法 传入的参数是 数据集、K、最大迭代次数、代价函数变化阈值
// 其中 最大迭代次数和代价函数变化阈值是设定了默认值,可以根据需要做相应更改
def train(data: RDD[Seq[Double]], k: Int, maxIter: Int = 40, tol: Double = 1e-4) = {
val sc: SparkContext = data.sparkContext
var i = 0 // 迭代次数
var cost = 0D //初始的代价函数
var convergence = false //判断收敛,即代价函数变化小于阈值tol
// step1 :随机选取 k个初始聚类中心
var initk: Array[(Seq[Double], Int)] = data.takeSample(false, k, Random.nextLong()).zip(Range(0, k))
var res: RDD[(Seq[Double], Int)] = null
while (i < maxIter && !convergence) {
val bcCenters = sc.broadcast(initk)
val centers: Array[(Seq[Double], Int)] = bcCenters.value
val clustered: RDD[(Int, (Double, Seq[Double], Int))] = data.mapPartitions(points => {
val listBuffer = new ListBuffer[(Int, (Double, Seq[Double], Int))]()
// 计算每个样本点到各个聚类中心的距离
points.foreach { point =>
// 计算聚类id以及最小距离平方和、样本点、1
val cost: (Int, (Double, Seq[Double], Int)) = centers.map(ct => {
ct._2 -> (math.pow(distance.Euclidean(ct._1, point), 2), point, 1)
}).minBy(_._2._1) // 将该样本归属到最近的聚类中心
listBuffer.append(cost)
}
listBuffer.toIterator
})
//
val mpartition: Array[(Int, (Double, Seq[Double]))] = clustered
.reduceByKey((a, b) => {
val cost = a._1 + b._1 //代价函数
val count = a._3 + b._3 // 每个类的样本数累加
val newCenters = a._2.zip(b._2).map(tp => tp._1 + tp._2) // 新的聚类中心点集
(cost, newCenters, count)
})
.map {
case (clusterId, (costs, point, count)) =>
clusterId -> (costs, point.map(_ / count)) // 新的聚类中心
}
.collect()
val newCost = mpartition.map(_._2._1).sum // 代价函数
convergence = math.abs(newCost - cost) <= tol // 判断收敛,即代价函数变化是否小于小于阈值tol
// 变换新的代价函数
cost = newCost
// 变换初始聚类中心
initk = mpartition.map(tp => (tp._2._2, tp._1))
// 聚类结果 返回样本点以及所属类的id
res = clustered.map(tp=>(tp._2._2,tp._1))
i += 1
}
// 返回聚类结果
res
}
算法调用 :为了方便,本案例使用的数据集还是鸢尾花数据集
val dataset = spark.read.textFile("F:\\DataSource\\iris.csv")
.rdd.map(_.split(",").filter(NumberUtils.isNumber _).map(_.toDouble))
.filter(!_.isEmpty).map(_.toSeq)
val kmeans = new Kmeans2()
val res: RDD[(Seq[Double], Int)] = kmeans.train(dataset, 3)
res.sample(false, 0.1, 1234L)
.map(tp => (tp._1.mkString(","), tp._2))
.foreach(println)
聚类结果
(4.8,3.0,1.4,0.3,0)
(4.6,3.2,1.4,0.2,0)
(6.0,3.4,4.5,1.6,2)
(5.6,2.7,4.2,1.3,2)
(7.1,3.0,5.9,2.1,1)
(7.2,3.2,6.0,1.8,1)
······
根据笔者的检验来看,聚类出来的结果和源数据的分类还是有些许差别。所以通过本案例说明:每个方法都有它自身的使用场景,每个数据集都有自身的属性因此每个都有不同的解决方法,没有最好,只有更好。工具固然可以帮我们解决问题,但是掌握工具能帮我们有效的解决问题。
不足之处
因为初始聚类中心是随机选择,因此可能会让结果陷入局部最优,有学者就此问题提出了很多优化方法,例如kmeans++、Kernel K-means等方法。有兴趣的朋友们可以看看 。
如有不当之处,欢迎指正