安装前的准备:
- CentOS7操作系统
- jdk1.8(elasticsearch-6.6.2、logstash-6.6.2需要jdk1.8环境的支持)
- 去官网下载ELK(elasticsearch-6.6.2、logstash-6.6.2、kibana-6.6.2) 地址:https://www.elastic.co/downloads 。这里
推荐下载.tar.gz后缀的,安装比较方便(注:jdk1.8推荐下载.rpm后缀的。CentOS7一般自带jdk1.8的(终端输入:java -version
查看如果版本是jdk 1.8 则可以跳过第一步1.jdk1.8的安装,进行第2步的安装)。
1.jdk1.8的安装:
直接在Oracle的官网去下载jdk1.8。地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 如图:
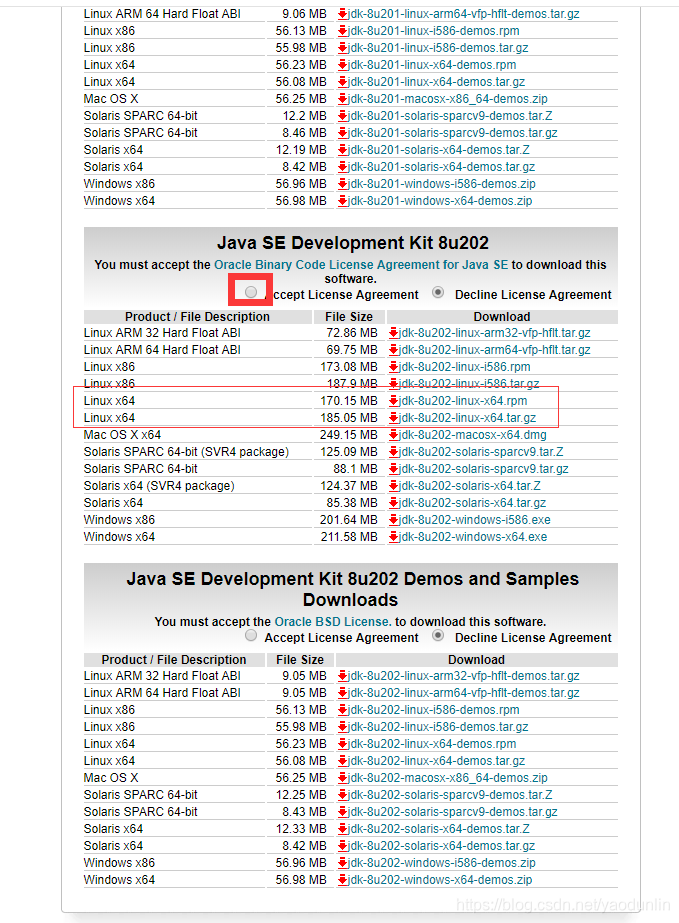
注:这里有两种压缩格式(.tar.gz、.rpm)。这里简单说明一下:
1、*.rpm形式的源代码软件包
安装:
rpm -ivh *.rpm
卸载:
rpm -e packgename
2、.tar.gz/.tgz、*.bz2形式的源代码软件包
安装:
tar zxvf *.tar.gz 或 tar yxvf *.bz2` //先解压
//然后进入解压后的目录: cd 你解压的目录
./configure //配置
make //编译
make install //安装
可以看出使用.rpm的压缩包安装要简单一些,不需要经过配置、编译等过程。所以这里下载的jdk包直接下的.rpm后缀的。
下载好jdk-8u112-Linux-x64.rpm后,使用下面的命令进行安装:
rpm -ivh jdk-8u112-linux-x64.rpm //前提是你要进入到你的jdk下载目录下
使用下面的命令检查是否安装成功:
或
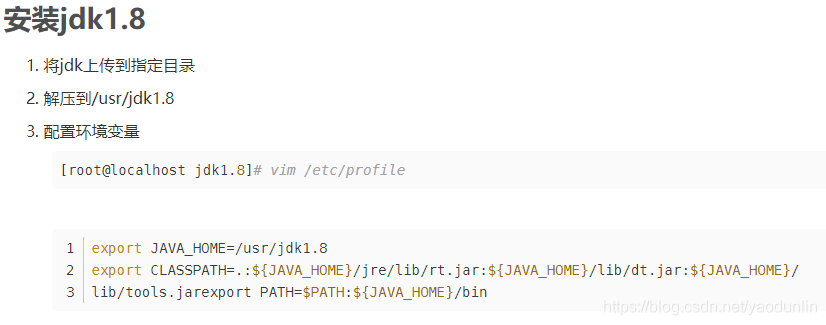
使环境变量生效
source /etc/profile
java -version
显示如下,则证明jdk1.8已经安装到你的CentOS7中了。

安装elasticsearch
1、下载安装包:https://www.elastic.co/downloads

下载好elasticsearch-6.6.2.tar.gz后,使用下面的命令:
tar -xzf elasticsearch-6.6.2.tar.gz //解压。注意要cd进入你的elasticsearch-6.6.2.tar.gz下载目录才能解压
cd elasticsearch-6.6.2 //进入刚才解压的目录
[root@localhost elasticsearch-6.6.2]# ./bin/elasticsearch //运行 ,启动的时候系统可能会卡住,耐心等待就好了
注意,上面运行后会出现这样的错误:can not run elasticsearch as root ,错误很明显,不能以root用户运行elasticsearch 。所以
我们这里要新建一个用户组,及用户。如下:
groupadd elsearchgroup //添加名为elsearchgroup的组
useradd -g elsearchgroup elsearchuser //在elsearchgroup组中添加一个elsearchuser用户
passwd elsearchuser //更改elsearchuser的密码
su elsearchuser //从root用户切换到elsearchuser用户
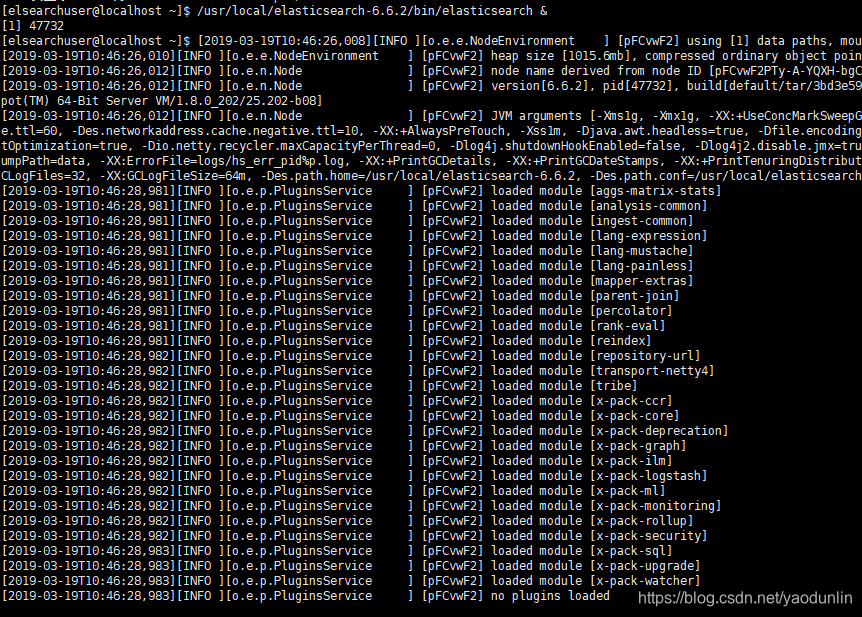
[elsearchuser@localhost elasticsearch-6.6.2]$ ./bin/elasticsearch //在elsearchuser下运行elasticsearch
这时候可能还会报像这样的错误:AccessDeniedException …. 。原因是你的文件访问权限问题(因为你刚才是在root用户下解压的这些
目录,读写权限root用户拥有,而你更换了用户角色,所以就没权限了)。更改一下访问权限就可以了。
chown -R elsearchuser:elsearchgroup elasticsearch-6.6.2//更改elasticsearch-6.6.2目录及其子目录的所属组为elsearchgroup,所述用户为elsearchuser
chmod -R 777 elasticsearch-5.1.1 //-R参数 和 777 结合表示把elasticsearch-6.6.2目录及其子目录的权限设置为完全可读写。
再次启动,效果如下:
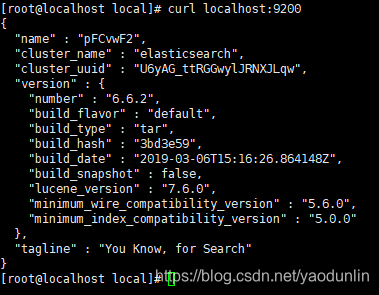
验证:打开浏览器输入localhost:9200 ,得到下图则表明elasticsearch-6.6.2安装成功:
2、elasticsearch-6.6.2的比较重要的配置:
elasticsearch-6.6.2有两个配置文件:elasticsearch.yml、log4j2.properties。 位置在elasticsearch-6.6.2/config目录下。
elasticsearch.yml配置文件下比较重要的配置如下:
- path.data 和 path.logs
- cluster.name
- node.name
- bootstrap.memory_lock
- network.host
- discovery.zen.ping.unicast.hosts
- discovery.zen.minimum_master_nodes
3、path.data 和 path.logs:
我们使用的.tar.gz格式的压缩包安装的elasticsearch-6.6.2。解压出来默认的目录结构都是默认组织在elasticsearch-6.6.2目录下的。
如下图:
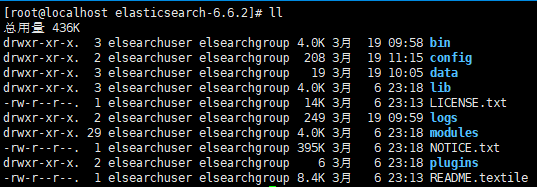
可以看到data和logs目录都在默认的elasticsearch-6.6.2目录下。如果我们就使用这样的默认目录结构保存我们的数据(data)和日志
(logs),当我们更新我们的elasticsearch-6.6.2到更新的版本后,data和logs就很大的风险被新的版本覆盖。所以我们应该更改
elasticsearch.yml配置文件的下的path.data 和 path.logs的路径,避免使用默认的路径。例:
path.data: /usr/worksapces/elsearch6.6.2/data //去掉#,更改路径
path.logs: /usr/worksapces/elsearch6.6.2/logs
3.3.1.cluster.name :
集群(cluster)是一个或多个节点(node)(server:服务器)的集合,它们一起保存整个数据,并在所有节点上提供联合索引和搜索功
能。集群默认名为:elasticsearch。cluster.name 就是来更改默认的名称为我们想要的名称的。群集的名称不能重复。如果一个节点是
通过设置集群名来加入该集群,那么该节点只能是该群集的一部分。例:
cluster.name: logging-prod
3.3.2.node.name:
节点(node)就是一个单一的服务器(比如我们拿自己的电脑启动了elasticsearch,我们的电脑就相当于一个节点),它是集群的一部
分。它能存储数据,并参与群集的索引和搜索功能。节点的默认名是随机的UUID(random Universally Unique IDentifier)。一个节点
只能加入一个集群。通过node.name来更改默认的名称。 例:
node.name: prod-data-2
3.3.3.bootstrap.memory_lock
3.3.4.network.host
默认的就是127.0.0.1(localhost),即本地。但是为了与其他服务器上的节点进行通信并形成集群,所以我们应该更改network.host,
例如:
network.host: 192.168.1.43 //自己在网络上的ip,这里给的是自己电脑(节点)在局域网内的ip
修改elasticsearch.yml配置文件中ip地址
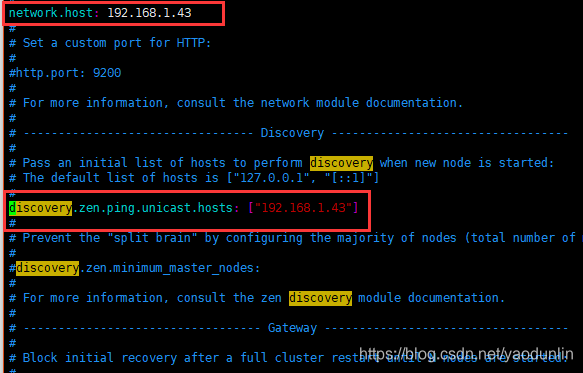
更改network.host可能会遇到下面的错误:
错误1:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]。
解决错误1:
打开/etc/security/limits.conf文件,添加以下两行代码并保存:
* soft nofile 65536 //* 表示任意用户,这里是elasticsearch报的错,也可以直接填运行elasticsearch的用户。如:
* hard nofile 131072
错误2:memory locking requested for elasticsearch process but memory is not locked
解决错误2:修改elasticsearch.yml文件
bootstrap.memory_lock : false
错误3:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决错误3:终端输入以下命令:
sysctl -w vm.max_map_count=262144 //需要root权限
sysctl -a|grep vm.max_map_count //查看修改结果,可选
或者
[1]: max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]编辑 /etc/security/limits.conf,追加以下内容;
* soft nofile 65536
* hard nofile 65536
此文件修改后需要重新登录用户,才会生效
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
编辑 /etc/sysctl.conf,追加以下内容:
vm.max_map_count=655360
保存后,执行:
sysctl -p
重新启动,成功。
3.3.5.discovery.zen.ping.unicast.hosts
如果没有任何网络配置,Elasticsearch将扫描端口9300到9305来连接到同一台服务器上运行的其他节点,这其实就是在我们没有进行任何
网络配置的情况下,给了我们一个自动的群集(auto-clustering)体验。
当你要将网络上多个在其它服务器上的节点建立起一个集群的时候,你必须将这些节点一一罗列出来:例:
discovery.zen.ping.unicast.hosts:
- 192.168.1.43:9300
- 192.168.1.44 //默认使用9300端口
可以通过这些节点来自动发现新加入集群的节点。
3.3.6.discovery.zen.minimum_master_nodes
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。例:
discovery.zen.minimum_master_nodes: 3
bin/elasticsearch &

安装elasticsearch6.X的head插件
因为head插件是用node.js开发的所以需要此环境,官网下载
https://nodejs.org/en/download/
下载插件安装
git clone git://github.com/mobz/elasticsearch-head.git
简单的说 Node.js 就是运行在服务端的 JavaScript。Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。Node.js 的包管理器 npm,是全球最大的开源库生态系统。
打开官网下载链接:https://nodejs.org/en/download/ 我这里下载的是,如下图:

解压
[root@izbp14hdjlwscja93xb3ovz head]# tar -zxvf node-v8.12.0-linux-x64.tar.xz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
换一种方法,不要z参数就可以了
tar -Jvxf node-v8.12.0-linux-x64.tar.xz
变为全局可用
修改 /etc/profile
vi /etc/profile 配置环境变量(以下操作在root用户下执行,因为没有给esuser赋其它文件夹操作
权限)
配置环境变量# vi /etc/profile
添加如下配置 node安装时可不放在目录es下
# export NODE_HOME=/home/elk/head/node-v8.12.0-linux-x64
# export PATH=$PATH:$NODE_HOME/bin
# export NODE_PATH=$NODE_HOME/lib/node_modules
执行一下命令
# source /etc/profile
cd elasticsearch-head
配置head
进入head文件中
执行 npm install -g grunt-cli

执行 npm install ,此过程会下载phantomjs (运行npm install时,可能PhantomJS not found on PATH ...可执行 npm install latest)
这一点是因为我的elasticsearch是es用户,而elasticsearch-head-master文件是root用户所以要使用es的用户来执行
chown -R es:es /home/elk/elasticsearch-head-master/
然后在执行npm install latest下面表示成功
2.修改配置
修改elasticsearch-head下Gruntfile.js文件,默认监听在127.0.0.1下9200端口

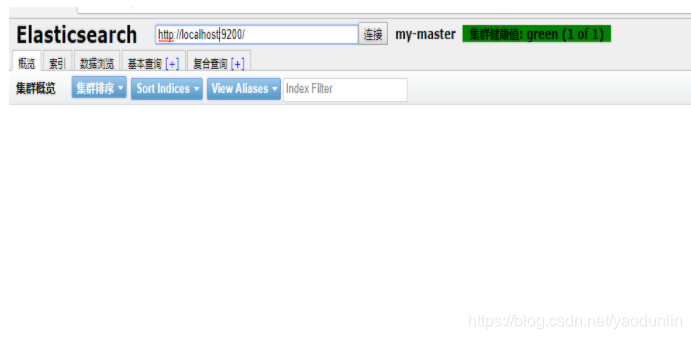
3.启动服务
/usr/local/elasticsearch-head/node_modules/grunt/bin/grunt server &
安装logstash
安装logstash
下载tar.gz:https://artifacts.elastic.co/downloads/logstash/logstash-6.6.2.rpm
安装rpm
[root@localhost ~]# rpm -ivh logstash-6.6.2.rpm
配置logstash输入输出文件
[root@localhost log]# vim /etc/logstash/conf.d/logstash.conf
input {
#stdin {}
file {
path =>"/usr/log/*"
type =>"system"
start_position =>"wld"
#codec => plain{charset => "UTF-8" }
}
}
filter{
}
output {
elasticsearch {
#cluster =>"ourfuture"
hosts =>["192.168.1.43:9200"]
index => "ydl"
}
}
启动logstash
[root@localhost log]# systemctl start logstash.service
安装kibana
下载url:https://artifacts.elastic.co/downloads/kibana/kibana-6.6.2-x86_64.rpm
安装rpm
[root@localhost ~]# rpm -ivh kibana-6.6.2-x86_64.rpm
修改kibana配置文件
[root@localhost kibana]# vim /etc/kibana/kibana.yml
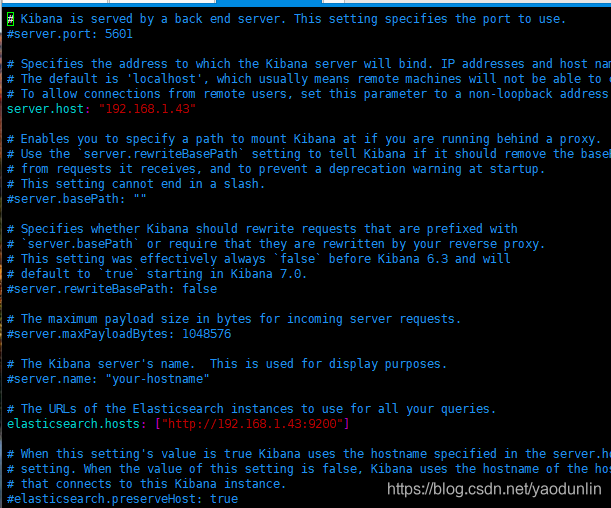
浏览器访问:http://192.168.1.43:5601
详细使用还需各位多看官方文档。