作者团队:谷歌
Inception V1 (2014.09)
网络结构主要受Hebbian principle 与多尺度的启发。
Hebbian principle:neurons that fire togrther,wire together
单纯地增加网络深度与通道数会带来两个问题:模型参数量增大(更容易过拟合),计算量增大(计算资源有限)。
改进一:如图(a),在同一层中采用不同大小的卷积核以及pooling层同时对图像提取特征,然后将特征concatenate。
但是这里有一个问题是,计算量会很大。然后提出了改进二
改进二:如图(b),添加
卷积,一方面用来减小通道数,从而降低计算量;另一方面,在
卷积后加入ReLu,增添非线性。
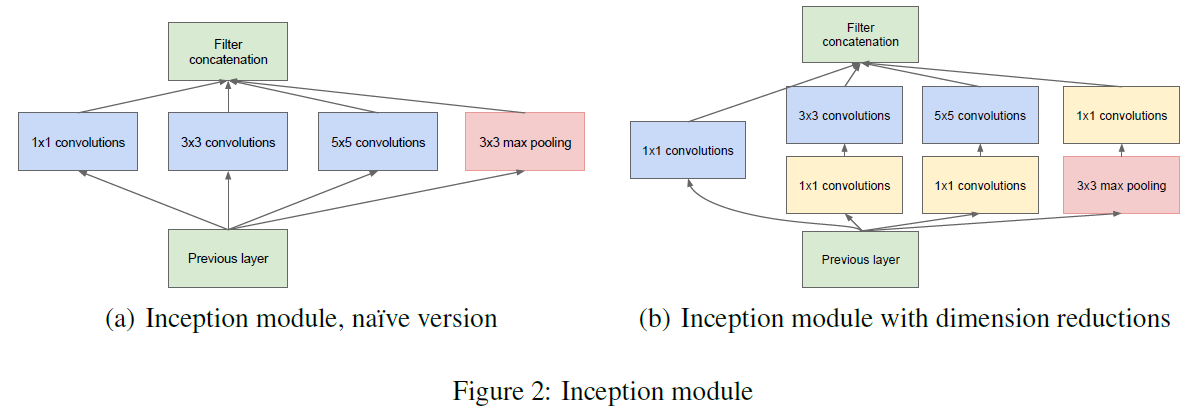
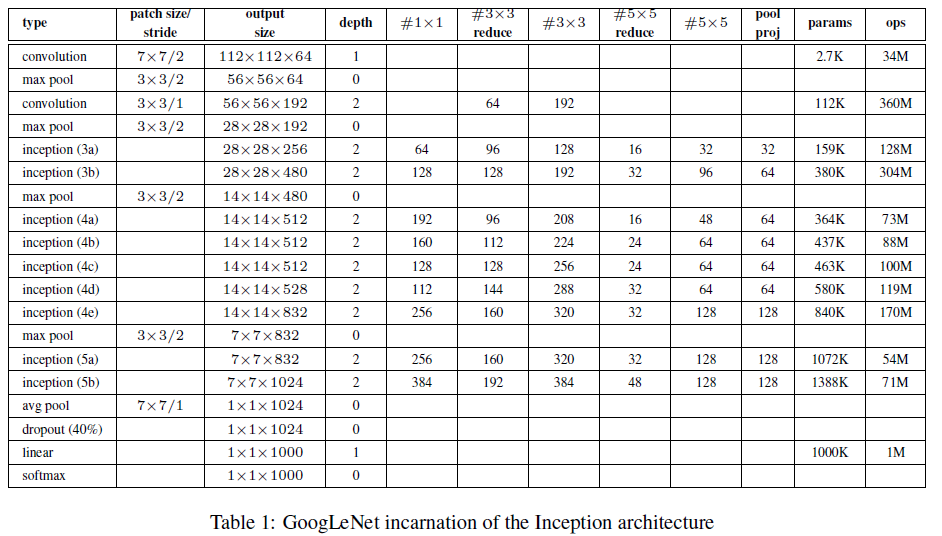
其具体的网络结构如下:
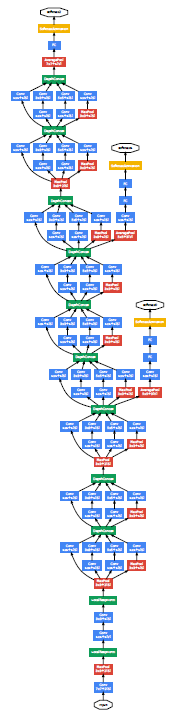
Inception的网络示意图如下。共有22层,网络相对较深,为了避免出现梯度消失的问题,网络中添加了两个auxiliary classifiers,最终的loss为它们的加权和。当然,这两个auxiliary classifiers只在训练阶段使用,测试阶段不用。
Inception V2 (2015.12)
Inception的优点很大程度上是由dimension reduction带来的,为了进一步提高计算效率,这个版本探索了其他分解卷积的方法。因为Inception为全卷积结构,网络的每个权重要做一次乘法,因此只要减少计算量,网络参数量也会相应减少。
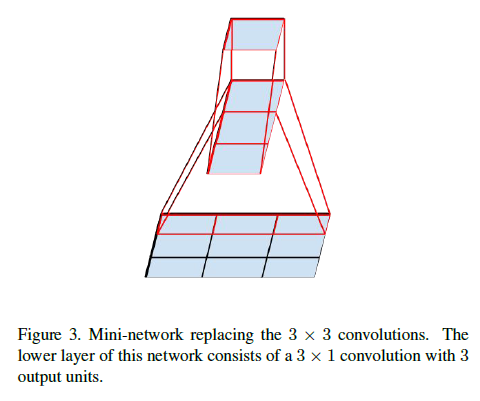
探索一、Factorization into smaller convolutions

如下图所示,左边的结构为Inception V1模块,右边的结构仅仅是将 卷积用两个 卷积代替。这样可以一定程度减少计算量。一个 卷积计算量为一个 卷积的 倍。这样替换成两个 卷积后,计算量减少


这种结构替换降低了计算量,但对模型性能会有什么影响?
探索二、Spatial Factorization into Asymmetric Convolutions
将
卷积继续分解为
卷积和
卷积。这可以节省
参数量
改进后模块如下所示:
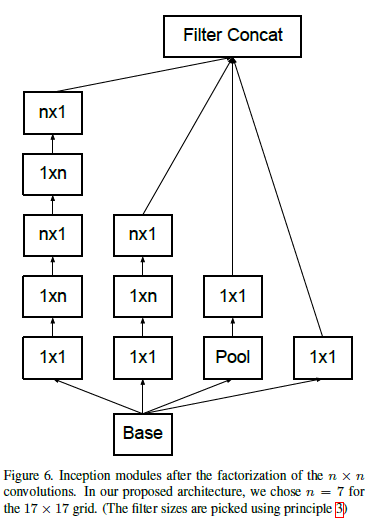
作者还发现,在较浅的层直接用这种分解效果并不好,一般在模型的中间层使用会得到很好的结果。
探索三、Made wider instead of deeper
Reduce representational bottleneck. The intuition was that, neural networks perform better when convolutions didn’t alter the dimensions of the input drastically. Reducing the dimensions too much may cause loss of information, known as a “representational bottleneck”
滤波器组展宽,减少representational bottleneck,从而减少信息的损失。

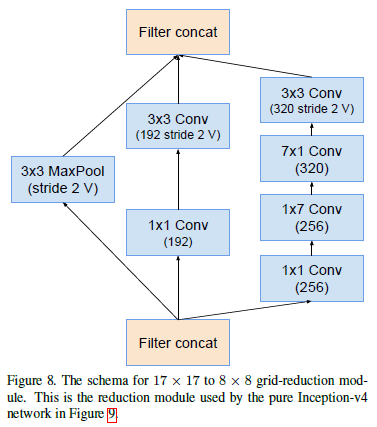
探索四、Efficient Grid Size Reduction
当特征图大小要减半时,使用如下结构:

模型结构

Inception V3 (2015.12)
探索一、Utility of Auxiliary Classifiers
Inception V1在模型中间加入了两个 Auxiliary Classifiers,而作者在去掉一个Auxiliary Classifier后,发现模型并没有削弱,因此作者认为Auxiliary Classifier并没有如Inception V1 文章所说的那样能够促进浅层特征的提取,而更多的是起网络正则的作用。这个结论的佐证是在Auxiliary Classifier中加入BN层或droupout之后,主网络分类器的性能会更好。
探索二、Label smoothing
Label Smoothing : When we apply the cross-entropy loss to a classification task, we’re expecting true labels to have 1, while the others 0. In other words, we have no doubts that the true labels are true, and the others are not. Is that always true? Maybe not. Many manual annotations are the results of multiple participants. They might have different criteria. They might make some mistakes. They are human, after all. As a result, the ground truth labels we have had perfect beliefs on are possible wrong.
One possibile solution to this is to relax our confidence on the labels. For instance, we can slighly lower the loss target values from 1 to, say, 0.9. And naturally we increase the target value of 0 for the others slightly as such. This idea is called label smoothing
思路其实很简单,以10分类为例,原本其中一类标签为1,其余为0;现在将该类标签设置成0.9,剩下0.1平均分配给其他类别。通过对标签smoothing的操作,一方面对模型正则,减少模型过拟合,一方面增强模型的适应性。
模型结构
Inception V3 在Inception V2的基础上加入了RMSProp优化、Label Smothing技巧、
卷积分解以及对auxiliary classifier加入BN层正则。

Inception V4 (2016.02)
模型结构

其中各个模块结构如下:
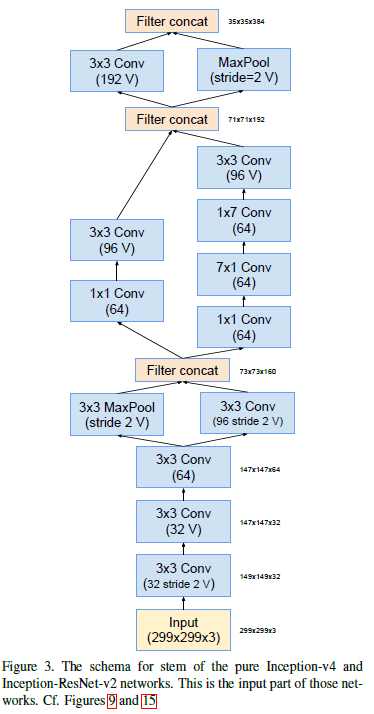
Stem模块:图中的V表示valid padding,数字代表通道数。
Inception-A模块:

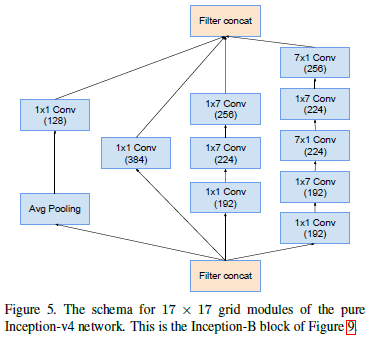
Inception-B模块:
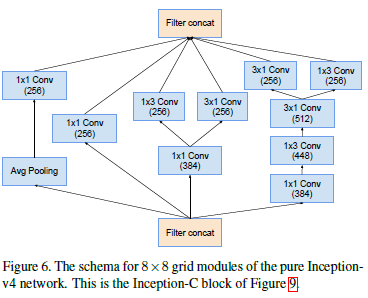
Inception-C模块:
Reduction-A 模块:(该模块-V4、-ResNet相同)
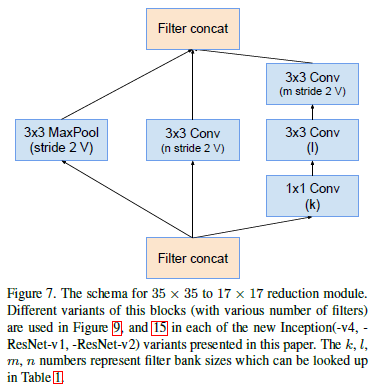
图中k、l、m、n取值如下所示:
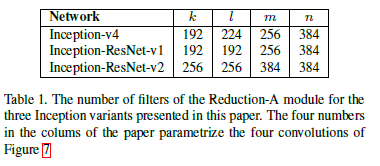
Reduction-B 模块:
Inception-ResNet (2016.02)
随着2015年resnet的提出,作者尝试将residual connections 引入到Inception中。
作者提出了两个版本,Inception-ResNet-v1 和 Inception-ResNet-v2,前者与Inception-V3计算量相当,后者与Inception-V4计算量相当(但实际中V4要慢很多),其结构如下图:
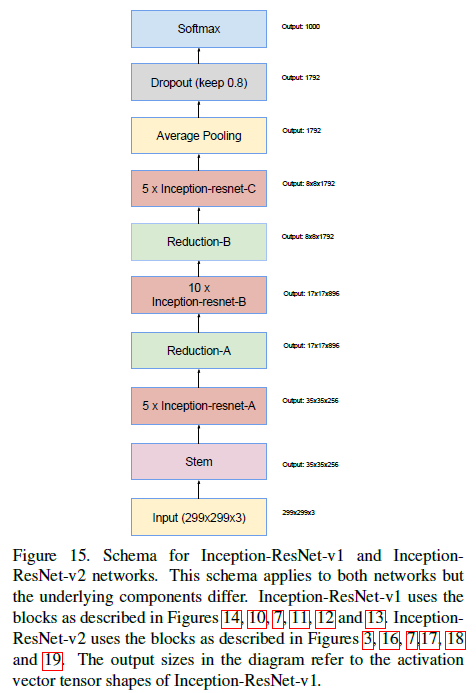
Inception-ResNet-v1 各模块如下:
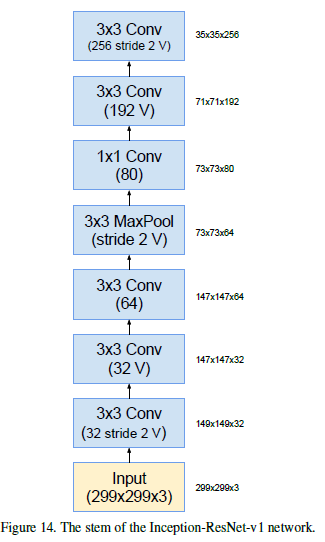
stem模块:
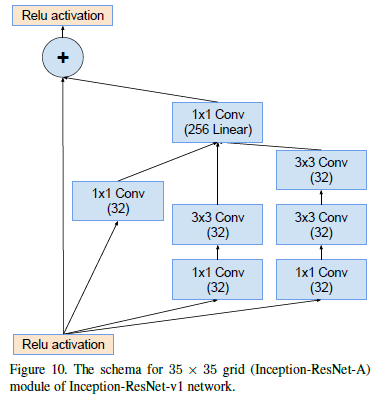
Inception-resnet-A模块:
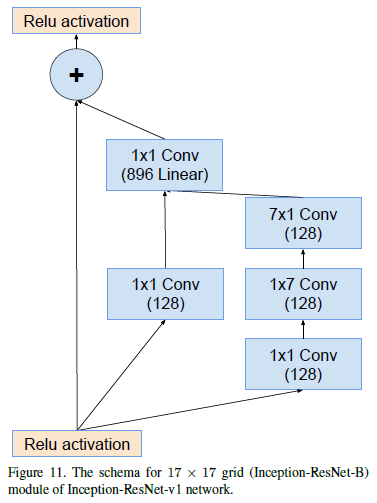
Inception-resnet-B模块:
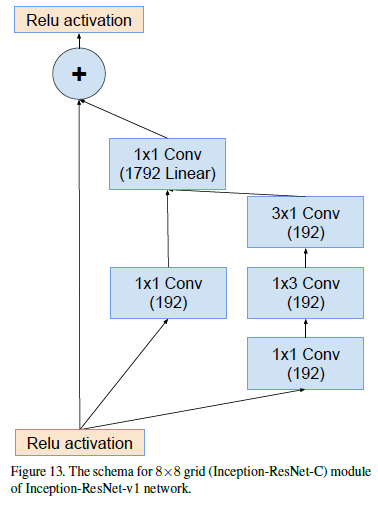
Inception-resnet-C模块:
Reduction-A模块:(该模块-V4、-ResNet相同)

Reduction-B模块:
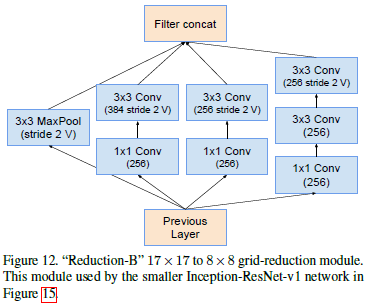
Inception-ResNet-v2 各模块如下:
各个模块与 Inception-ResNet-v1 完全一样,只是在超参的设置上有区别( -ResNet-v2计算量更大,如通道数的设置会更大一些)
stem模块:(与Inception-V4相同)
Inception-resnet-A模块:

Inception-resnet-B模块:

Inception-resnet-C模块:

Reduction-A模块:(该模块-V4、-ResNet相同)
Reduction-B模块:
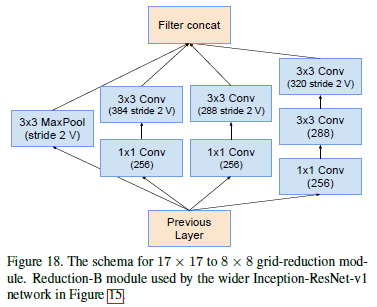
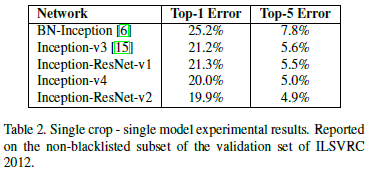
版本性能比较
其中BN-Inception是在Inception V1基础上加入BN层
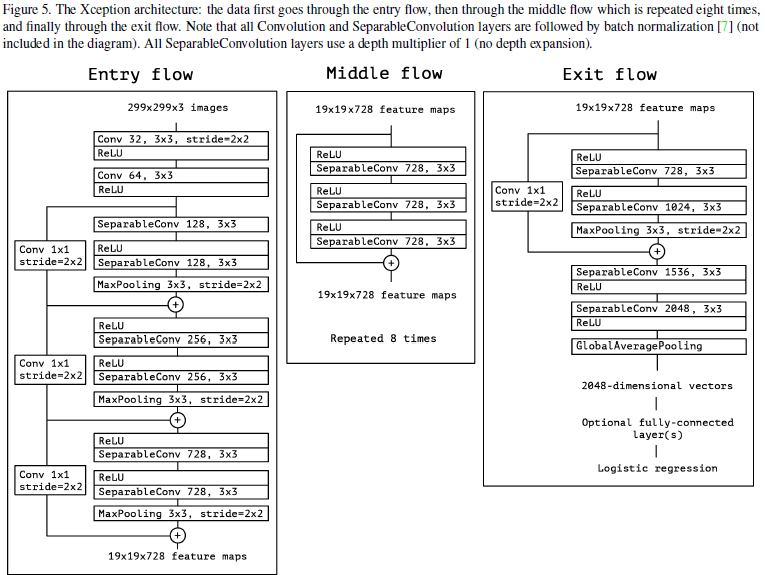
Xception (2016.10)
Xception参数量与Inception-V3相同,但性能更优越。
主要提出的创新在于depthwise seperable convolution。如下图Figure1所示,受Inception V3模块启发,可以将其简化成Figure2、3所示,再将其推向一个极致,对
卷积后的每一通道特征单独用一个卷积核进行卷积,如Figure4所示。


网络结构如下:
模型性能比较:

参考文献
[1] INCEPTION V1 : Going deeper with convolutions
[2] INCEPTION V2、V3 : Rethinking the Inception Architecture for Computer Vision
[3] INCEPTION V4、INCEPTION-ResNet:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
[4] XCEPTION:Xception: Deep Learning with Depthwise Separable Convolutions
[5] 强烈推荐阅读 :https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202