写在篇前
层次聚类(hierarchical clustering)是一种通用的聚类算法之一,它通过自下而上合并或自上而下拆分来构建嵌套聚类。这种簇的层次结构表示为树(或树状图),树的根汇聚所有样本,树的叶子是各个样本。本篇博客会简述层次聚类的原理,重点是使用sklearn、scipy、seaborn等实现层次聚类并可视化结果。
原理简述
看到一篇详细讲层次聚类原理的文章层次聚类算法的原理及实现Hierarchical Clustering,讲的通俗易懂,一看便知,这里主要讲一下Metrics(请保证sklearn >=0.20):
-
Ward:minimizes所有聚类中的平方差和,它是一种方差最小化方法,在这个意义上类似于kmeans。
-
complete linkage:minimizes两个簇的样本对之间距离的最小值
-
Average linkage:minimizes两个簇的样本对之间距离的平均值
-
Single linkage: minimizes两个簇的样本对之间距离的最大值
算法实现
sklearn中实现的层次聚类实际上是自下而上合并的方式,通过from sklearn.cluster import AgglomerativeClustering导入层次聚类的封装类。
from sklearn.cluster import AgglomerativeClustering
clu = AgglomerativeClustering(n_clusters=2,
affinity='euclidean',
linkage='ward', compute_full_tree=False)
# --------------------------属性--------------------------
# 基础(类)属性
print('n_clusters:', clu.n_clusters)
print('affinity:', clu.affinity)
print('memory:', clu.memory)
print('connectivity:', clu.connectivity)
print('compute_full_tree:', clu.compute_full_tree)
print('linkage:', clu.linkage)
print('pooling_func:', clu.pooling_func)
# 重要属性
print('labels_:', clu.labels_) # 样本聚类结果标签
print('children_:', clu.children_) # 每一个非叶子结点的孩子数
print('n_components_:', clu.n_components_) # 连接图中连通分量的估计值
print('n_leaves_:', clu.n_leaves_) # 层次聚类树中叶子数目
# --------------------------函数--------------------------
print('get_params:', clu.get_params()) # 与set_params()相对应
# fit()、fit_predict()函数放到案例里面讲解
案例
基础案例
官方给了一个很好的案例,我们可以看一下(scikit-learn 0.20 or later):
#! /usr/bin/python
# _*_ coding: utf-8 _*_
__author__ = 'Jeffery'
__date__ = '2018/11/12 17:45'
import time
import warnings
import numpy as np
import matplotlib.pyplot as plt
from sklearn import cluster, datasets
from sklearn.preprocessing import StandardScaler
from itertools import cycle, islice
np.random.seed(0)
######################################################################
# Generate datasets. We choose the size big enough to see the scalability
# of the algorithms, but not too big to avoid too long running times
n_samples = 1500
noisy_circles = datasets.make_circles(n_samples=n_samples, factor=.5, noise=.05)
noisy_moons = datasets.make_moons(n_samples=n_samples, noise=.05)
blobs = datasets.make_blobs(n_samples=n_samples, random_state=8)
no_structure = np.random.rand(n_samples, 2), None
# Anisotropicly distributed data
random_state = 170
X, y = datasets.make_blobs(n_samples=n_samples, random_state=random_state)
transformation = [[0.6, -0.6], [-0.4, 0.8]]
X_aniso = np.dot(X, transformation)
aniso = (X_aniso, y)
# blobs with varied variances
varied = datasets.make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
# data shape:
# noisy_circles:(1500, 2)
# noisy_moons: (1500, 2)
# varied(blobs): (1500, 2)
# blobs: (1500, 2)
# aniso: (1500, 2)
# no_structure:(1500, 2) no labels
######################################################################
# Run the clustering and plot
# Set up cluster parameters
plt.figure(figsize=(9 * 1.3 + 2, 14.5))
plt.subplots_adjust(left=.02, right=.98, bottom=.001, top=.96, wspace=.05,
hspace=.01)
plot_num = 1
default_base = {'n_clusters': 3}
datasets = [
(noisy_circles, {'n_clusters': 2}),
(noisy_moons, {'n_clusters': 2}),
(varied, {}),
(aniso, {}),
(blobs, {}),
(no_structure, {})]
for i_dataset, (dataset, algo_params) in enumerate(datasets):
# update parameters with dataset-specific values
params = default_base.copy()
params.update(algo_params)
X, y = dataset
# normalize dataset for easier parameter selection
X = StandardScaler().fit_transform(X)
# ============
# Create cluster objects
# ============
ward = cluster.AgglomerativeClustering(
n_clusters=params['n_clusters'], linkage='ward')
complete = cluster.AgglomerativeClustering(
n_clusters=params['n_clusters'], linkage='complete')
average = cluster.AgglomerativeClustering(
n_clusters=params['n_clusters'], linkage='average')
single = cluster.AgglomerativeClustering(
n_clusters=params['n_clusters'], linkage='single')
clustering_algorithms = (
('Single Linkage', single),
('Average Linkage', average),
('Complete Linkage', complete),
('Ward Linkage', ward),
)
for name, algorithm in clustering_algorithms:
t0 = time.time()
algorithm.fit(X)
t1 = time.time()
if hasattr(algorithm, 'labels_'):
y_pred = algorithm.labels_.astype(np.int)
else:
y_pred = algorithm.predict(X)
plt.subplot(len(datasets), len(clustering_algorithms), plot_num)
if i_dataset == 0:
plt.title(name, size=18)
colors = np.array(list(islice(cycle(['#377eb8', '#ff7f00', '#4daf4a',
'#f781bf', '#a65628', '#984ea3',
'#999999', '#e41a1c', '#dede00']),
int(max(y_pred) + 1))))
plt.scatter(X[:, 0], X[:, 1], s=10, color=colors[y_pred])
plt.xlim(-2.5, 2.5)
plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plt.text(.99, .01, ('%.2fs' % (t1 - t0)).lstrip('0'),
transform=plt.gca().transAxes, size=15,
horizontalalignment='right')
plot_num += 1
plt.show()
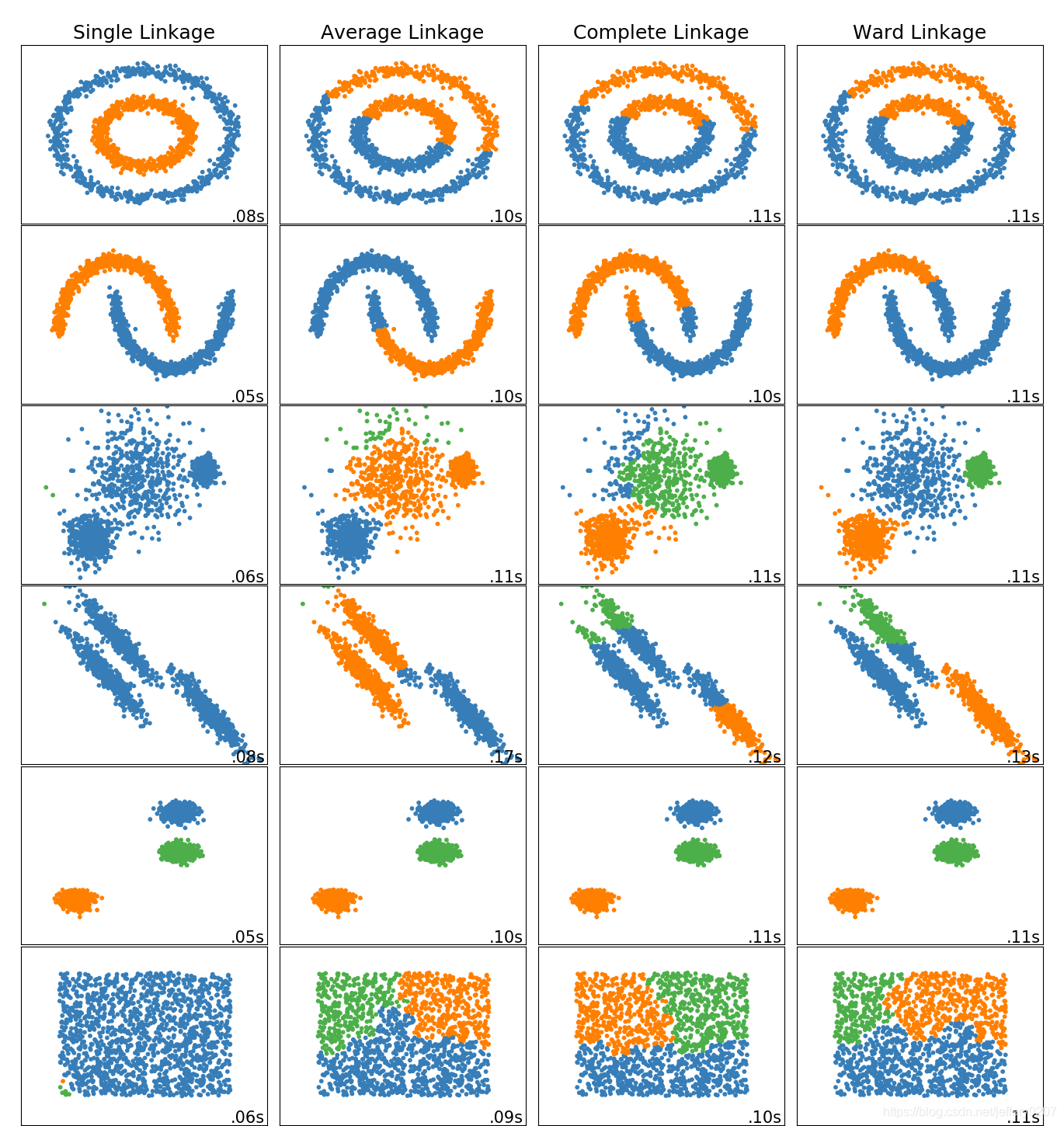
通过以上案例我们应该学习到:
- single linkage速度快,并且可以在非球状数据上表现良好,但是在存在噪声的情况下它表现不佳;
- average linkage和complete linkage在‘干净’的球状数据上表现良好;
- Ward是应对噪声数据最有效的方法;
- 层次聚类一般不能直接适用于高维数据
进阶案例
树状图
对于层次聚类,我们一般还会构建聚类树或生成热图,这就是我们下面要探讨的问题。但是其中还会牵涉一些原理,包括natural divisions、dissimilarity(cophenetic correlation coefficient.)、disconsistency等,请参考层次聚类原理解析
import pandas as pd
from scipy.cluster import hierarchy
import matplotlib.pyplot as plt
import numpy as np
my_data = np.random.random(size=[10, 4])
my_data = pd.DataFrame(my_data, index=(1, 2, 3, 4, 5, 6, 7, 8, 9, 10),
columns='A B C D'.split())
Z = hierarchy.linkage(my_data,
method='ward',
metric='euclidean',
optimal_ordering=False)
print(type(Z), '\n', Z) # 这个有必要解释一下
hierarchy.dendrogram(Z)
plt.show()
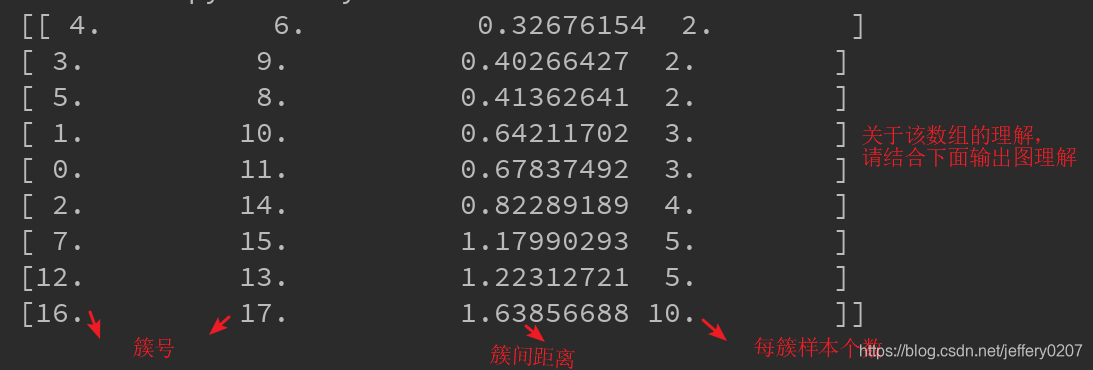
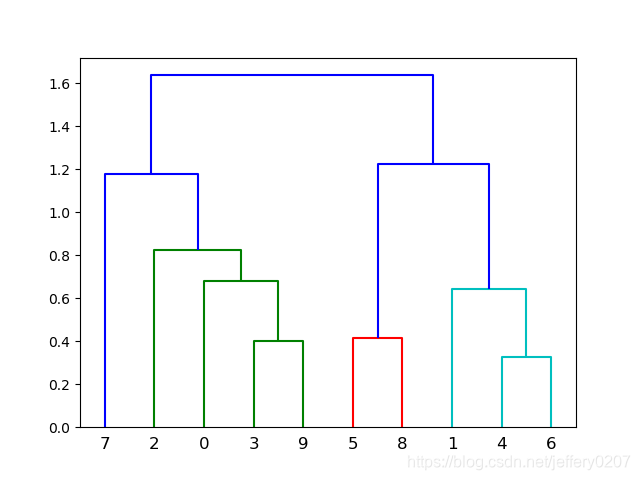
# 可以继续对树进行剪枝
# n_clusters和height只能二选其一
label = cluster.hierarchy.cut_tree(Z, n_clusters=2, height=None)
# label:(可以对比上图验证结果的正确性)
[[0]
[1]
[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]]
分割聚类树,将其生成多个不同的cluster还有一种方式:
# 分割cluster
labels = fcluster(Z, t=0.7, criterion='inconsistent')
print(labels)
参数说明:
- 当criterion为’inconsistent’时,t值应该在0-1之间波动,t越接近1代表两个数据之间的相关性越大,t越趋于0表明两个数据的相关性越小。
- 当criterion为’distance’时,t值代表了绝对的差值,如果小于这个差值,两个数据将会被合并,当大于这个差值,两个数据将会被分开。
- 当criterion为’maxclust’时,t代表了最大的聚类的个数。
- 当criterion为’monocrit’时,t的选择不是固定的,而是根据一个函数monocrit[j]来确定。
热图
上面的图呢,形式比较简单,有时候我们更希望我们能够画出更加炫酷的聚类图,这个时候我们就会想到绘制clustermap,这是我们可以用到seaborn.clustermap(),该函数基于上面讲到的scipy.hierarchy模块,封装了一个方便的绘图函数。
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(color_codes=True)
iris = sns.load_dataset("iris")
species = iris.pop("species") # {'setosa', 'versicolor', 'virginica'}
lut = dict(zip(species.unique(), "rbg"))
row_colors = species.map(lut)
g = sns.clustermap(iris, row_colors=row_colors)
print(g.dendrogram_row.reordered_ind) # reordered row indices
print(g.dendrogram_col.reordered_ind) # reordered col indices
print(g.savefig('a.png'))
plt.show()
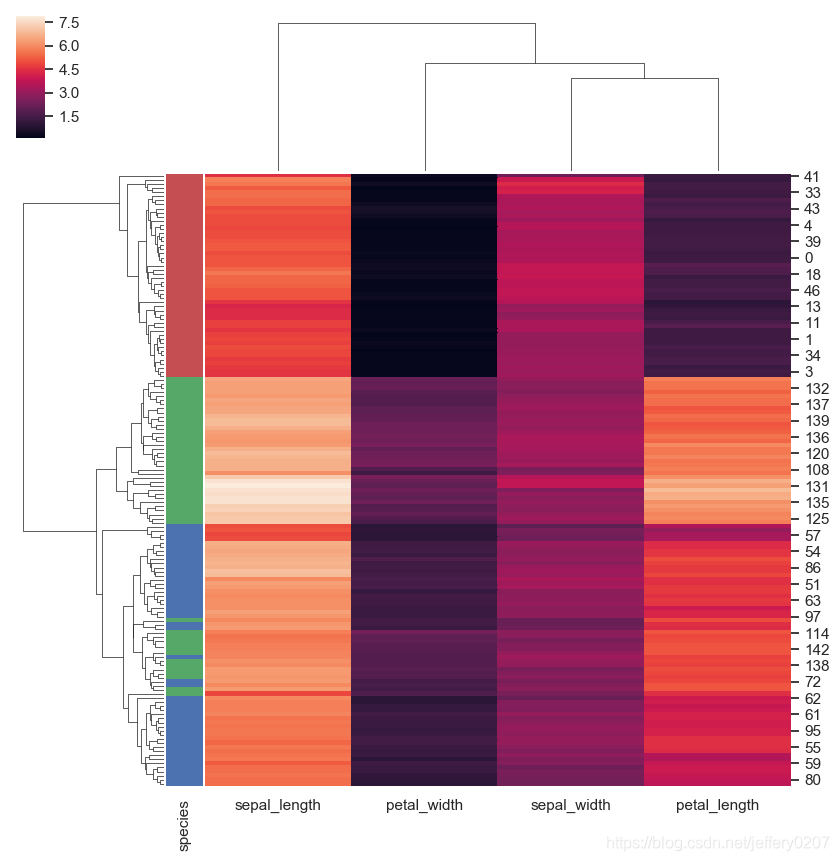
层次聚类本身的原理不难,主要就在于对聚类的method(euclidean、manhattan等)、metrics(single、average等)的理解以及聚类树分割原理的理解。