MySQL别名
使用 MySQL 别名来提高查询的可读性。
MySQL支持两种别名,称为列别名和表别名。
查询数据时,如果表名很长,使用起来不方便,可以为表取一个别名:
SELECT * FROM 表名 AS 表别名;
在查询数据时,为了使显示的查询结果更加直观,可以为字段取一个别名:
SELECT 列名 AS 列别名, 列名 AS 列别名, ... FROM 表名;
注:为表和列指定别名时,AS关键字可以省略不写
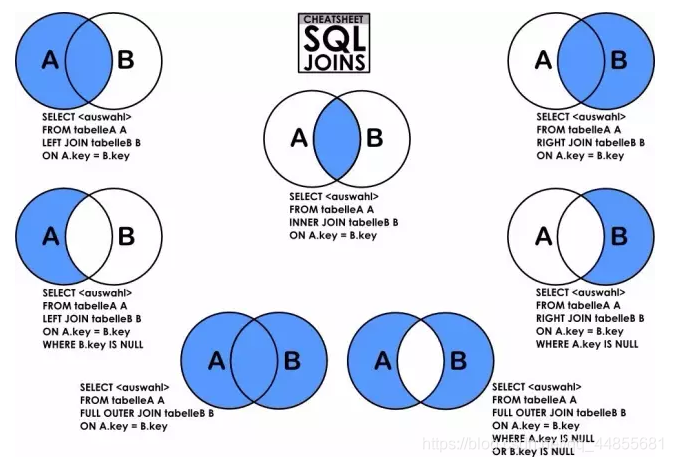
INNER JOIN(内联结)
内联结又称为等值联结,将两个表中存在联结关系的字段符合联结关系的那些记录形成记录集的联结。用 INNER JOIN 指定表之间的关系,用 ON 子句指定联结条件。
SELECT column_name(s)
FROM table_name1
INNER JOIN table_name2
ON table_name1.column_name = table_name2.column_name;
LEFT JOIN(左联结)
获取左表所有记录,即使右表没有对应匹配的记录。
SELECT column_name(s)
FROM table_name1
LEFT JOIN table_name2
ON table_name1.column_name = table_name2.column_name;
CROSS JOIN(叉联结)
没有 WHERE 条件的叉联结将产生连接表所涉及的笛卡尔积。笛卡尔积:某个数据表里的每一个数据行与另一个数据表里的每一行得到的全部组合。
如果 WHERE 子句与 CROSS JOIN 一起使用,则其功能类似于 INNER JOIN 。
SELECT * FROM tableA CROSS JOIN tableB;
自连接
自连接(self join)是 SQL 语句中经常要用的连接方式,使用自连接可以将自身表的一个镜像当作另一个表来对待,从而能够得到一些特殊的数据。自连接的本意就是将一张表看成多张表来做连接。具体用法参考 Mysql自连接的一些用法——WEICHAO
UNION
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
MySQL UNION 操作符语法格式:
SELECT expression1, expression2, ... expression_n
FROM table_name1
[WHERE conditions]
UNION [ALL | DISTINCT]
SELECT expression1, expression2, ... expression_n
FROM table_name2
[WHERE conditions];
- expression1, expression2, … expression_n:要检索的列。
- tables: 要检索的数据表。
- WHERE conditions:可选, 检索条件。
- DISTINCT:可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT修饰符对结果没啥影响。
- ALL:可选,返回所有结果集,包含重复数据。
以上几种方式的区别和联系
内联结只显示在两个数据表里都能找到匹配的数据行。
外联结除了显示同样的匹配结果,还可以把其中一个数据表在另一个数据表里没有匹配的数据行也显示出来。
外联结分左联结和右联结两种:
-
联结意思是把左数据表在右数据表里没有匹配的数据行也显示出来;
-
右联结意思是把右数据表在左数据表里没有匹配的数据行也显示出来。
小练习
项目五:组合两张表 (难度:简单)
在数据库中创建表1和表2,并各插入三行数据(自己造)
表1: Person;(PersonId 是该表主键)
| 列名 | 类型 |
|---|---|
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
表2: Address;(AddressId 是该表主键)
| 列名 | 类型 |
|---|---|
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:FirstName, LastName, City, State
-- 创建表1
USE datawhale;
CREATE TABLE Person
(
PersonId INT NOT NULL PRIMARY KEY,
FirstName VARCHAR(20) NULL,
LastName VARCHAR(20) NULL
);
-- 插入数据
INSERT INTO Person (PersonId, FirstName, LastName)
VALUES
(1, 'Wangtao', 'LONG'),
(2, 'Yang', 'LIU'),
(4, 'Xiaoqi', 'CHEN');
-- 创建表2
CREATE TABLE Address
(
AddressId INT NOT NULL PRIMARY KEY,
PersonId INT NULL,
City VARCHAR(50) NULL,
State VARCHAR(50) NULL
);
-- 插入数据
INSERT INTO Address (AddressId, PersonId, City, State)
VALUES
(21323, 3, 'Beijing', 'China'),
(21324, 2, 'Shanghai', 'US'),
(21325, 1, 'Shenzhen', 'China');
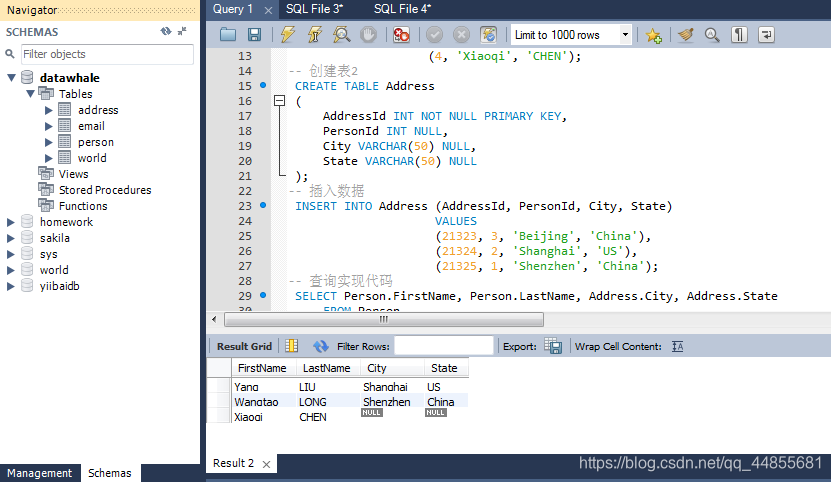
-- 查询实现代码
SELECT Person.FirstName, Person.LastName, Address.City, Address.State
FROM Person
LEFT JOIN Address
ON Person.PersonId = Address.PersonId;
项目六:删除重复的邮箱(难度:简单)
编写一个 SQL 查询,来删除 email 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
| Id | |
|---|---|
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
Id 是上表的主键。
例如,在运行你的查询语句之后,上面的 Person表应返回以下几行:
| Id | |
|---|---|
| 1 | [email protected] |
| 2 | [email protected] |
-- 创建表
USE datawhale;
CREATE TABLE IF NOT EXISTS email
(
id INT AUTO_INCREMENT,
Email VARCHAR(30) NOT NULL,
PRIMARY KEY (id)
);
-- 插入数据
INSERT email (id, Email)
VALUES (1, '[email protected]'),
(2, '[email protected]'),
(3, '[email protected]');
-- 查询
DELETE e1 FROM email AS e1
LEFT JOIN email AS e2
ON e1.Email = e2.Email
WHERE e1.Id > e2.Id;
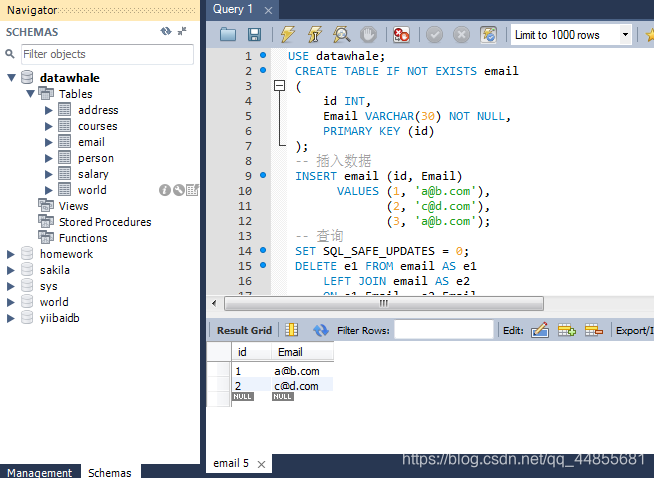
这里出现了上一篇博文相同的错误: Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode, toggle the option in Preferences