近观Faster R-CNN在车辆检测中的应用
综述
Faster R-CNN在目标检测中取得了优异成果。然而,在大型车辆数据集上却表现不佳。在本文中,我们近距离观察它在车辆检测上的应用。我们做了大量实验,并且提供这个模型内在结构的综合分析。我们发现通过合适的调参和算法修正,我们能显著提升Faster R-CNN在车辆检测中的表现,并且在KITTI车辆数据库中取得不错的结果。我们相信我们的研究对那些探索Faster R-CNN在其他问题和数据库上的应用的研究者来说是有意义的。
1. 引言
车辆检测对诸如公共安全,监控,智能交通控制和自动驾驶的很多应用来说,具有核心意义。由于外界环境、摄像头视角的巨大变化,他成了一个有挑战性的问题(见图1)。

图一
天气和亮度是另外的一些问题。之前的一些关于车辆检测的研究一直关注于特征设计,例如手工特征和闭合建模。尽管这些方法表现得不错,但目前最好的方法都是基于深度神经网络。
近年来,深度学习方法在目标检测中广泛应用。这些方法使用了更大的数据库,并且往往在有大量分类的数据库或者多任务中取得不错的结果。在有挑战性的数据库,例如ImageNet和VOC上,还有特定的数据库,例如专注于车辆和行人检测的KITTI上都取得了最好的结果。在这些目标检测算法中,最优的是Ren提出的faster R-CNN
然而,我们不知道这个方法是否在车辆检测等特定应用中和其他优秀算法表现得一样好。事实上,我们采用faster R-CNN默认参数训练的模型和其他在KITTI汽车竞赛中的优秀算法表现得一样好。
在这个研究中,我们在KITTI数据集上使用Faster R-CNN进行了多方位的实验,包括训练及测试观测,目标提取,局部vs识别,还有迭代训练。我们尝试分析这个方法的优势和它的限制。从我们的研究中,我们发现faster R-CNN的结果高度依赖于训练和测试观测。我们也检查了Faster R-CNN在大量细节下的局部化和识别能力,并且我们使用这个结果去设计一个新型迭代方法来进一步提升在这个数据集上的运行结果。我们的主要贡献如下:
- 深度理解如何为特定的应用和数据集来调整和修改Faster R-CNN
- 显著提升Faster R-CNN在KITTI数据集上车辆检测的表现结果
2. 相关工作
多年以来,boosting techniques(增强技术)成功应用于实时车辆检测中,并且直到几年前,车辆检测的最好算法为deformable part models(DPM)。在[20]中能找到那个时候的车辆检测报告。错误的正反馈经常使用道路和车辆姿势模型结合追踪信息进行过滤。
然而,在近些年,深度模型在几乎所有的目标类型中被证明在分类和检测上更加准确。使用卷积神经网络(CNNs)使得对于检测的数据驱动方法称为可能,最小化了设计特征,模型目标的工作,减小了对于额外传感器的依赖。
KITTI数据集给自动驾驶应用提供了丰富的具有实用性的大型数据库,这爆发了应用CNNs对这个问题上进行探索。在过去两年有超过20个已经开发并且在KITTI上测评过的算法,包括使用location relaxation(区间松弛),dense neural patterns and regionlets(密集神经模式和基本特征区域),clustering appearance patterns(聚类表现模式),data-driven 3D voxel patterns(3D像素模式),和integrating context and occlusion for car detection(车辆检测的整体环境和闭合)。
在KITTI数据及上发表过的最好结果是第四个竞争者X.Chen NIPS 2015。他们的研究依赖于立体图像去评估3D窗口。接下来最好的已发表结果是L.Huang,DenseBox(密集窗口)。它使用了一个单一联合全连接卷积神经网络去进行检测,它结合了窗口预测和目标检测于一个框架之内。他们用landmark information来加强他们的方法。他们在KITTI数据集上取得了不错的结果,并且一直在改进他们的方法。主要的缺点是他们的计算消耗。通过使用一个很小的模型,Huang能够构建一个低版本的DenseBox,它能够在少于0.05秒内运行一张图片。
3. Faster R-CNN概括
以往的目标检测通过完全利用一个二类目标分类器通过基于窗口搜索来运行。所有的窗口涵盖了所有有效的尺寸还有宽高比,它返回一个确定目标分类,之后进一步使用非最大值抑制进行裁剪。这个方法之后在使用不同的预过滤器后得到了增强,称作目标提取算法。例如使用分支和边界的最小化搜索区域,和根据标定信息的对象尺寸限制,grouping super-pixels(集合超像素)包括Selective Search(选择性搜索),还有基于一个空间金字塔池化和边界框。预过滤增强了效率,特别是通过分享提取的卷积
在Faster R-CNN中,一个ergion proposal network(RPN)区域提取网络用目标检测网络共享卷积层,这显著降低了提取计算代价。一些额外的卷积层用来回归每个区域的区域边界和目标得分。这个算法设计上的改变显著提高了模型速度,同时它也提高了目标检测的结果。Faster R-CNN在PASCAL VOC 2007和2012中取得了最高准确率,并且是ImageNet检测和定位等比赛获胜模型的基础。
图二显示了Faster R-CNN框架的网络结构。

图二
区域提取网络和目标分类器共享全连接卷积层。这些高效地进行了联合训练。区域提取网络作为一个探测者,从大量不同尺寸和宽高比的边界框中决定了接下来将要被目标分类器评估的最优边界框。换句话说,RPN告诉了分类器去看哪里。
4. KITTI数据库
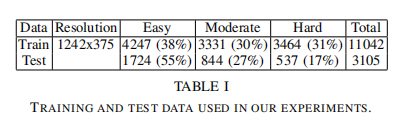
KITTI目标检测和和目标定位示例图像通过使用一个全自动驾驶平台获取高分辨率立体数据、连续帧、视觉测量和3D镭射扫描来进行收集。关于目标检测,数据库包含了12000张图像,有40000个已标记的对象包括小轿车,卡车,行人,自行车和有轨电车。图像是彩色的,并且分辨率为1242 x 375。每个对象用一个3D边界框准确标记。数据库提供了一个MATLAB评估工具。
在我们的实验中,我们使用这个数据库包含小轿车的子集。这个子集包含了7481张训练图片,有28742个已标记的小汽车(见图一)。这些汽车的高度分布见图三。大多数汽车图像高度为40到80像素。数据集被切分为3个类型:简单,中等,困难,这基于最小边界框高度(分别为40,35,25像素)和最低可视程度(完全可见,部分遮挡,很难看见),还有缺失程度(15%,30%,50%)
5. 实验结果
A. 实验准备
数据 我们切分7481张图片为两部分,2/3用来训练,1/3用来测试,得到了11042个有效的训练用例和3105个测试用例。这两个子集的视频序列是不重叠的。表一显示了样例在3个类别的分布:简单,中等,困难。
模型参数 Faster R-CNN把所有的训练示例变为同一尺寸,这基于一个图像最小边的涨肚。另外,这个图像的最长边如果太大了,会变为一个已给尺寸,并且保持图像的宽高比。在我们的例子中,因为所有的图像都是一样的尺寸,训练和测试各一个参数已经足够指定图像大小。我们在这里分别标记他们为训练尺寸training scale(TR_S)和测试尺寸test scale(TE_S)。默认的,Faster R-CNN把测试尺寸设置为和训练尺寸一样大小,例如1000像素。另外我们需要关注的相关参数是分类器的提取数量,这和Faster R-CNN的结果和效率息息相关。
训练我们在ImageNet预训练的VGG上微调Faster R-CNN模型。不单单为汽车做二分类器,我们训练给数据集中所有的对象标签,包括人等训练多分类器,但是在分析中只关注汽车。我们采用平均准确率(AP)作为我们的结果度量,并且使用[1]中所提供的工具。
接下来,我们深入分析TR_S,TE_S和提取的数量,如何影响Faster R-CNN的运行结果。除非特别说明,在我们的实验中,每个参数都设置为它的默认值
B. 合适的训练尺寸
我们首先以训练集默认大小1000像素来训练Faster R-CNN。如表2所示,它的运行结果并不好,在中等难度的车辆示例中只取得了64.02%的准确率,而所公布的最优结果为90.03%。

Faster R-CNN
待续