Go Tool学习(一)scanner(1)TestScan方法
先看几个全局变量
- fset:源码文件信息集合
- special、literal、operator、keyword:标识Token类别
- tokens:用于测试的token集合
- whitespace:用于测试的空白符
- source:根据tokens和whitespace拼接而成的字节流,具体实现:
var source = func() []byte {
var src []byte
for _, t := range tokens {
src = append(src, t.lit...) // t.lit就是token的文本字符串,这里用...操作符将其展开
src = append(src, whitespace...)
}
return src
}()
开始scan之前
1.首先统计whitespace中有多少个换行符,这个值后面有用
whitespace_linecount := newlineCount(whitespace)
2.创建一个error handler,后面初始化scanner时作为初始化参数
eh := func(_ token.Position, msg string) {
t.Errorf("error handler called (msg = %s)", msg)
}
3.创建scanner。这里先往fset中添加一个匿名文件,然后fset.AddFile方法会返回一个file。ScanComments标识comment也会作为token被识别,dontInsertSemis标识不要自动在每行末尾插入分号
var s Scanner
s.Init(fset.AddFile("", fset.Base(), len(source)), source, eh, ScanComments|dontInsertSemis)
4.创建epos,epos表示expected postition,用来在每次scan结束后与scanner当前的position相比较以检测是否scan过程有bug
epos := token.Position{
Filename: "",
Offset: 0,
Line: 1,
Column: 1,
}
5.创建index,index表示当前在tokens中的位置,tokens[index]则是正在处理的token,每一轮scan后index自增
index := 0
进入循环,开始scan
1.首先scan一次,pos是这次scan结束后在source中的position,tok是token,lit是token原始文本
pos, tok, lit := s.Scan()
2.check position,验证pos是否和epos相同。如果tok是token.EOF的话,则重新设置epos的值
if tok == token.EOF {
// correction for EOF
epos.Line = newlineCount(string(source)) // 直接统计source中有多少行
epos.Column = 2 // 这里的2我这样理解的:首先column是从1开始的,然后column=1处的字符应该是EOF(即-1),而scanner每次scan后Offset都会指向下一个字符,所以这里column的值为2才是正确的
}
checkPos(t, lit, pos, epos) // 这里的t是*testing.T
贴上checkPos源码:
func checkPos(t *testing.T, lit string, p token.Pos, expected token.Position) {
pos := fset.Position(p)
if pos.Filename != expected.Filename { // 比较文件名
t.Errorf("bad filename for %q: got %s, expected %s", lit, pos.Filename, expected.Filename)
}
if pos.Offset != expected.Offset { // 比较Offset
t.Errorf("bad position for %q: got %d, expected %d", lit, pos.Offset, expected.Offset)
}
if pos.Line != expected.Line { // 比较行号
t.Errorf("bad line for %q: got %d, expected %d", lit, pos.Line, expected.Line)
}
if pos.Column != expected.Column { // 比较列号
t.Errorf("bad column for %q: got %d, expected %d", lit, pos.Column, expected.Column)
}
}
3.check token,声明一个变量e,并从tokens中取出正在处理的token或者创建一个EOF Token赋值给它,然后与scanner.Scan返回的tok相比较
e := elt{token.EOF, "", special}
if index < len(tokens) {
e = tokens[index]
index++
}
if tok != e.tok {
t.Errorf("bad token for %q: got %s, expected %s", lit, tok, e.tok)
}
4.check token class
if tokenclass(tok) != e.class {
t.Errorf("bad class for %q: got %d, expected %d", lit, tokenclass(tok), e.class)
}
这里直接贴上tokenclass源码:
func tokenclass(tok token.Token) int {
switch {
case tok.IsLiteral():
return literal
case tok.IsOperator():
return operator
case tok.IsKeyword():
return keyword
}
return special
}
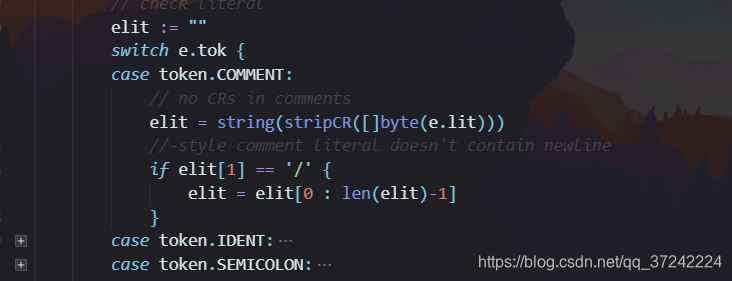
5.check literal,即比较token原始字符串是否相同。首先创建一个elit(exptected literal),这里用了一个switch代码块,针对不同的token,对e.lit进行处理后再与scanner返回的lit相比较。比如tokens[3]:{token.COMMENT, "//\r\n", special},这里的literal中包含了一个’\r’和’\n’,首先用stripCR删除\r’,然后elit = elit[0 : len(elit)-1]删除’\n’。switch代码块很长,这里就不贴出来了。
6.判断tok是不是token.EOF,是的话就结束循环
if tok == token.EOF {
break
}
7.如果没有退出循环,则更新epos的值
epos.Offset += len(e.lit) + len(whitespace)
epos.Line += newlineCount(e.lit) + whitespace_linecount