这个算法说是很牛逼,可是看了一些材料说的很多都是应用,对于原理说得不清楚,找到两篇,说得还算不错,不过还是没有完全清楚细节,若干年后学会了再补充。
概述
做自然语言处理的时候很多时候会用的WordEmbedding,目前我常用的方法是word2vec算法训练词向量。不过训练词向量的方法有很多,今天介绍GloVe算法。
GloVe:Global Vectors。
模型输入:语料库 corpus
模型输出:每个词的表示向量
基本思想
要讲GloVe模型的思想方法,我们先介绍两个其他方法:
一个是基于奇异值分解(SVD)的LSA算法,该方法对term-document矩阵(矩阵的每个元素为tf-idf)进行奇异值分解,从而得到term的向量表示和document的向量表示。此处使用的tf-idf主要还是term的全局统计特征。
另一个方法是word2vec算法,该算法可以分为skip-gram 和 continuous bag-of-words(CBOW)两类,但都是基于局部滑动窗口计算的。即,该方法利用了局部的上下文特征(local context)
LSA和word2vec作为两大类方法的代表,一个是利用了全局特征的矩阵分解方法,一个是利用局部上下文的方法。
GloVe模型就是将这两中特征合并到一起的,即使用了语料库的全局统计(overall statistics)特征,也使用了局部的上下文特征(即滑动窗口)。为了做到这一点GloVe模型引入了Co-occurrence Probabilities Matrix。
首先引入word-word的共现矩阵XX,


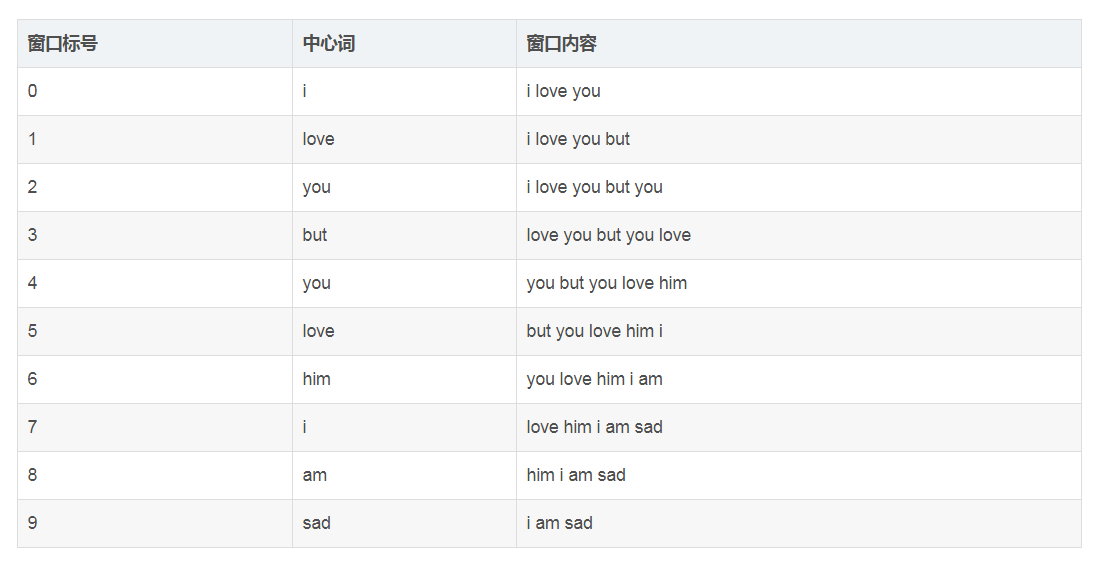
讲到这里,没有一个例子来说明,那就真是一件很遗憾的事情了,所以必须来个实例,实例永远是帮助理解最好的方式。
统计共现矩阵


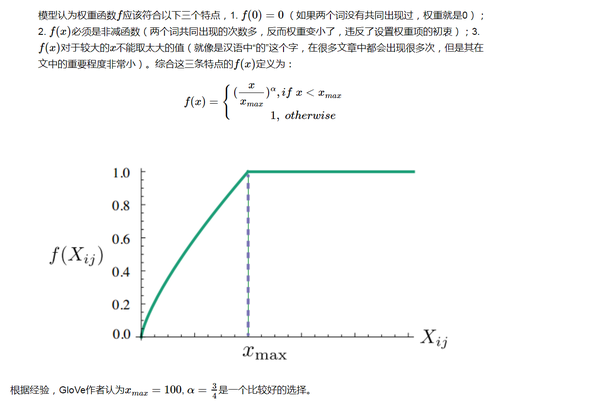
模型推导
以下内容看似公式很多,其实挺容易理解的,耐心看