原文地址:
https://blog.csdn.net/jiangpeng59/article/details/72867368
作者:PJ-Javis
来源:CSDN
------------------------------------------------------------------------------------------------------
1.实验环境
C
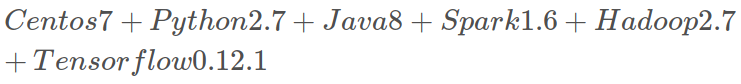
Spark和Hadoop的集群搭建网上教程比较多,这里以最简洁的方法配置集群,针对tensorflow添加的额外配置,我会进行强调(其实地上本没有坑,跌的人多了,也便成了Keng)
1>系统环境环境变量
export JAVA_HOME=/hadoop/jdk1.8.0_65 export HADOOP_HOME=/hadoop/hadoop-2.7.0 export SPARK_HOME=/hadoop/spark-1.6.0 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$SPARK_HOME/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
在/etc/profile或者~/.bashrc中配置都行,CLASSPATH不能少(Keng1)
2>hadoop集群
需修改的配置文件都在$HADOOP_HOME/hadoop-2.7.0/etc/hadoop目录下
(1)修改hadoop-env.sh 文件
export JAVA_HOME=/hadoop/jdk1.8.0_65
(2)修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop-2.7.0/tmp</value>
</property>
</configuration>
注意这里我把hdfs的namenode也设置在master节点上,hadoop.tmp.dir为hadoop的绝对路径
(3)修改文件hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/hadoop-2.7.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/hadoop-2.7.0/dfs/data</value>
</property>
</configuration>
(4)修改slaves文件,配置DataNode节点地址
这里的hosts我已经配置好,所以输入你对应的hostname就行了
slave01
slave02
slave03
(5)格式化namenode并启动hdfs
hdfs namenode -format
$HADOOP_HOME/sbin/start-dfs.sh
3>Spark集群
Spark集群Standalone的配置非常简单,修改2个文件即可,在此之前记得重命名去掉template
(1)配置spark-env.sh
export JAVA_HOME=/hadoop/jdk1.8.0_65 export HADOOP_CONF_DIR=/hadoop/hadoop-2.7.0/etc/hadoop export HADOOP_HDFS_HOME=/hadoop/hadoop-2.7.0 SPARK_MASTER_IP=master SPARK_WORKER_CORES=4 SPARK_WORKER_MEMORY=12G SPARK_EXECUTOR_MEMORY=8G
核数和内存根据自己的机器进行设置,环境变量HADOOP_CONF_DIR和HADOOP_HDFS_HOME不能少(Keng2)
(2)配置slaves
slave01
slave02
slave03
(3)启动spark集群
$SPARK_HOME/sbin/start-all.sh
Worker Id Cores Memory
worker1 4 (0 Used) 12.0 GB (0.0 B Used)
worker2 4 (0 Used) 12.0 GB (0.0 B Used)
worker3 4 (0 Used) 12.0 GB (0.0 B Used)
集群总共3个worker-instance,每个worker4核12G,总12核,所有的环境配置均和master节点一致(Keng3)
------------------------------------------------------------------------------------------------------