第八章 数据压缩与归档
8.1 zlib:GNU zlib压缩
zlib模块为GNU项目zlib压缩库中的很多函数提供了底层接口。
8.1.1 处理内存中的数据
使用zlib最简单的方法要求把所有将要压缩或解压缩的数据存放在内存中:
import zlib
import binascii
original_data = b'This is the original text.'
print('Original :',len(original_data),original_data)
compressed = zlib.compress(original_data)
print('Compressed :',len(compressed),
binascii.hexlify(compressed))
decompressed = zlib.decompress(compressed)
print('Decompressed :',len(decompressed),decompressed)
compress()和decompress()函数都取一个字节序列参数,并且返回一个字节序列。
运行结果:

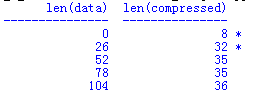
从前面的例子可以看到,少量数据的压缩版本可能比未压缩的版本还要大。具体的结果取决于输入数据,不过观察小数据集的压缩开销很有意思。
import zlib
original_data = b'This is the original text.'
template = '{:>15} {:>15}'
print(template.format('len(data)','len(compressed)'))
print(template.format('-' * 15,'-' * 15))
for i in range(5):
data = original_data * i
compressed = zlib.compress(data)
highlight = '*' if len(data) < len(compressed) else ''
print(template.format(len(data),len(compressed)),highlight)
输出中的*突出显示了哪些行的压缩数据比未压缩版本占用的内存更多。
运行结果:
zlib支持不同的压缩级别,允许在计算成本和空间缩减量之间有所平衡。默认压缩级zlib.Z_DEFAULT_COMPRESSION为-1,这对应着一个硬编码值,表示性能和压缩结果之间的一个折中。当前这对应级别6。
import zlib
input_data = b'Some repeated text.\n' * 1024
template = '{:>5} {:>5}'
print(template.format('Level','Size'))
print(template.format('-----','----'))
for i in range(0,10):
data = zlib.compress(input_data,i)
print(template.format(i,len(data)))
压缩级别为0意味着根本没有压缩。级别9要求的计算最多,同时会生成最小的输出。如下面的例子所示,对于一个给定的输入,可能多个压缩级别得到的空间缩减量是一样的。
运行结果:
