【CS231n】斯坦福大学李飞飞视觉识别课程笔记
CS229 Lecture notes
Andrew Ng
CS229 Lecture notes:Principal components analysis - 原文
Principal components analysis
在讨论因子分析的时候,我们给出了一个模型数据 “大约”躺在一些k-维子空间,其中k ≪ n。具体地说,我们认为每个点 被创建是通过先生成一些 躺在k-维仿射空间 ,然后添加Ψ-协方差噪音。因子分析是基于概率模型的,参数估计则是采用迭代EM算法。
在这一系列笔记中,我们将开发一种方法,主成分分析(PCA),它也试图确定数据近似所在的子空间。然而,PCA将更直接地做到这一点,并且只需要一个特征向量计算(在Matlab中使用 函数很容易),不需要求助于EM。
假设我们有一个数据集 表示m种不同类型汽车的属性,如最大车速、转弯半径等。对于每个 ,令 。但是我们不知道的是,有两种不同的属性——某些 和 ——分别给出一辆车的最高车速(以英里每小时为单位)和最高车速(以公里每小时为单位)。因此,这两个属性几乎是线性相关的,直到四舍五入到最近的 或者 时,才引入了很小的差异。因此,数据实际上近似地位于一个 维的子空间上。我们如何能够自动检测到这种冗余,并可能消除这种冗余?
举一个不那么做作的例子,考虑一个数据集,该数据集来自一个对遥控直升机飞行员的调查,其中
表示飞行员
的驾驶技能,
表示他/她有多喜欢飞行。因为遥控直升机很难飞行,只有那些最投入的学生,那些真正喜欢飞行的学生,才能成为优秀的飞行员。因此,这两个属性
和
是紧密相关的。事实上,我们可以假设数据实际上喜欢沿着某个对角线轴(
方向)捕捉一个人内在的驾驶“业力”,而这个轴上只有少量的噪声。(见图)。我们怎么能自动计算这个
方向?

我们将很快开发PCA算法。但在运行PCA之前,我们通常先对数据进行预处理,使其均值和方差标准化,具体如下:
1.

2. 用
替换每一个
3.
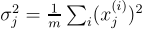
4. 用
替换每一个
步骤(1-2)将数据的均值归零,对于已知均值为零的数据(如语音或其他声学信号对应的时间序列)可以省略。步骤(3-4)将每个坐标重新缩放到具有单位方差,这确保了不同的属性都在相同的“scale”上处理。例如,如果 是汽车每小时的最高速度(取高于10或低于100的值), 是座位的数量(取2-4左右的值),那么这种重新归一化对不同的属性进行重新排序,使它们更具可比性。如果我们事先知道不同的属性都在同一个尺度上,那么步骤(3-4)可以省略。其中一个例子是,如果每个数据点都表示一个灰度图像,并且每个 都取{0,1,…,255}中的一个值,对应图像 的像素 的强度。
现在,在进行了归一化之后,我们如何计算“主方差轴”u——也就是数据近似所在的方向?提出这个问题的一种方法是找到单位向量u,这样当数据投影到与u对应的方向上时,投影数据的方差最大。直观地说,数据开始时包含一些方差/信息。我们想要选择一个方向u,这样如果我们要将数据近似为在与u对应的方向/子空间中,就可以尽可能多地保留这个方差。
考虑以下数据集,我们已经对其进行了归一化步骤:

现在,假设我们选择u来对应下图所示的方向。圆圈表示原始数据在这条直线上的投影。
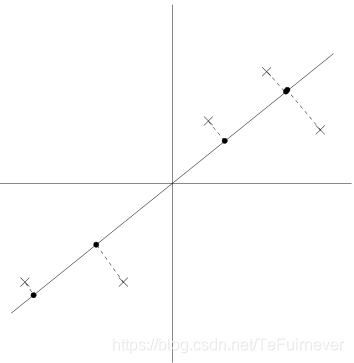
我们看到,预测的数据仍然有相当大的方差,而且这些点往往远离零。相反,假设选择了以下方向:
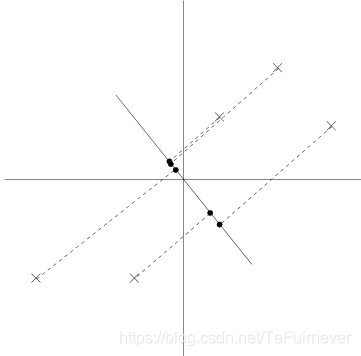
这里,投影的方差要小得多,而且更接近原点。
我们想要自动选择方向u对应的两个图中的第一个在上面显示。为了形式化,注意给定单位向量
和点
,
在
上的投影的长度由
给出。即,如果
是数据集中的一个点(图中的一个叉),那么它在
上的投影(图中对应的圆)就是
到原点的距离。因此,为了使投影的方差最大,我们选择一个单位长度
,从而使:
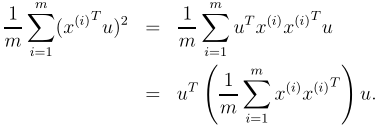
我们很容易认识到最大化这一主题
给
的主要特征向量,也就是数据的经验协方差矩阵(假设它具有零均值)。
总而言之,我们发现,如果我们希望发现一维子空间近似数据,我们应该选择 作为 的主要特征向量。更一般地说,如果我们希望将数据投影到 维子空间(k < n),我们应该选择 作为 的最高 特征向量。 现在形成了一个新的,正交的数据基。
然后,为了在这个基底中表示
我们只需要计算对应的向量
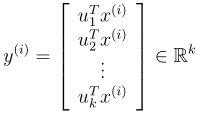
因此,尽管
,向量
现在给出了一个更低的k维近似/表示
。因此PCA也被称为降维算法。向量
称为数据的前
个主成分。
Remake. 虽然我们只是在k = 1的情况下正式地展示了它,但是使用已知的特征向量的性质,它很简单地展示了所有可能的正交基 ,我们选择的最大化 。因此,我们对基的选择保留了原始数据中尽可能多的可变性。
在problem set 4中,你会发现PCA也可以通过选择最小化,由于将数据投影到由它们张成的k维子空间而产生的近似误差,的基来得到。
PCA有很多应用;我们将用几个例子来结束我们的讨论。首先,压缩——用较低维数 s表示 s——是一个明显的应用。如果我们把高维数据减少到 k = 2或3维,那么我们也可以画出 s来可视化数据。例如,如果我们要将汽车数据缩减到二维,那么我们可以将其绘制成图(图中的一个点对应于一种汽车类型),以查看哪些汽车彼此相似,以及哪些汽车组可能聚集在一起。
另一个标准应用程序是在运行以 s为输入的监督学习学习算法之前,对数据集进行预处理以减小其维数。除了计算上的好处,减少数据的维数还可以减少所考虑的假设类的复杂性,并有助于避免过度拟合(例如,在较低维数的输入空间上的线性分类器将具有较小的VC维度)。
最后,在我们的RC试点例子中,我们也可以把PCA看作是一种降噪算法。在我们的例子中,它从驾驶技能和享受的嘈杂度量中估计了内在的“驾驶业力”。
在课堂上,我们也看到了这一思想在人脸图像中的应用,产生了特征脸法。其中,每个点 为10000维向量,每个坐标对应一张100x100的人脸图像的像素强度值。使用PCA,我们用一个更低维的 表示每个图像 。在这样做的过程中,我们希望我们发现的主要成分能够保留有趣的、系统的面部变化,这些变化能够捕捉到一个人的真实面貌,而不是由细微的光线变化、稍微不同的成像条件等引起的图像中的“噪音”。然后,我们通过在降维中计算 来测量面 和面 之间的距离。这就产生了一个非常好的人脸匹配和检索算法。