识别网站所用技术
构建网站所使用的技术类型也会对我们如何爬取产生影响,有一个十分有用的工具可以检查网站的技术类型——builtwith模块。
模块安装方法 pip install builtwith(下载并在高级中设置path才能运行的)
import builtwith
print(builtwith.parse('http://home.sise.cn'))
运行结果:
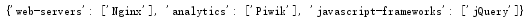
寻找网站所有者
import whois
print(whois.whois('http://home.sise.cn'))
BeautifulSoul
创建一个网络爬虫来抓取 http://www.pythonscraping.com/pages/warandpeace.html
这个网页。
我们可以抓出整个页面,然后创建一个 BeautifulSoup 对象
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen('http://www.pythonscraping.com/pages/warandpeace.html')
bsobj=BeautifulSoup(html)
通过 BeautifulSoup 对象,我们可以用 findAll 函数抽取只包含在 </
span> 标签里的文字,这样就会得到一个人物名称的 Python 列表( findAll 是一个非常灵活的函数,我们后面会经常用到它):
namelist=bsobj.findAll('span',{'class':'green'})
for name in namelist:
print(name.get_text())
什么时候使用 get_text() 与什么时候应该保留标签?
.get_text() 会把你正在处理的 HTML 文档中所有的标签都清除,然后返回
一个只包含文字的字符串。假如你正在处理一个包含许多超链接、段落和标
签的大段源代码,那么 .get_text() 会把这些超链接、段落和标签都清除掉,
只剩下一串不带标签的文字。
用 BeautifulSoup 对象查找你想要的信息,比直接在 HTML 文本里查找信
息要简单得多。通常在你准备打印、存储和操作数据时,应该最后才使
用 .get_text() 。一般情况下,你应该尽可能地保留 HTML 文档的标签结构。
两个函数非常相似,BeautifulSoup 文档里两者的定义就是这样:
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
标签参数 tag 前面已经介绍过——你可以传一个标签的名称或多个标签名称组成的 Python列表做标签参数。例如,下面的代码将返回一个包含 HTML 文档中所有标题标签的列表:
.findAll({"h1","h2","h3","h4","h5","h6"})
属性参数 attributes 是用一个 Python 字典封装一个标签的若干属性和对应的属性值。例
如,下面这个函数会返回 HTML 文档里红色与绿色两种颜色的 span 标签:
.findAll("span", {"class":{"green", "red"}})
递归参数 recursive 是一个布尔变量。你想抓取 HTML 文档标签结构里多少层的信息?如果recursive 设置为 True , findAll 就会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签。如果 recursive 设置为 False , findAll 就只查找文档的一级标签。 findAll默认是支持递归查找的( recursive 默认值是 True );一般情况下这个参数不需要设置,除非你真正了解自己需要哪些信息,而且抓取速度非常重要,那时你可以设置递归参数。
文本参数 text 有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。假如我们想查找前面网页中包含“the prince”内容的标签数量,我们可以把之前的 findAll 方法换成下面的代码:

nameList = bsObj.findAll(text="the prince")
print(len(nameList))
还有一个关键词参数 keyword ,可以让你选择那些具有指定属性的标签。例如:
allText = bsObj.findAll(id="text")
print(allText[0].get_text())
正则表达式
* 匹配前面的字符、子表达式或括号里的字符 0 或多次 a*b* aaaaaaaa,aaabbbbb,bbbbbb
+ 匹配前面的字符、子表达式或括号里的字符至少1 次 a+b+ aaaaaaab,aaabbbbb,
[] 匹配任意一个字符(相当于“任选一个”) [A-Z]* APPLE,CAPITALS,QWERTY
() 表达式编组(在正则表达式的规则里编组会优先运行) (a*b)* aaabaab,abaaa,ababaaaaab
{m,n} 匹配前面的字符、子表达式或括号里的字符 m 到n 次(包含 m 或 n)a{2,3}b{2,3} aabbb,aaabbb,aabb
[^] 匹配任意一个不在中括号里的字符 [^A-Z]* apple,lowercase,qwerty
| 匹配任意一个由竖线分割的字符、子表达式(注意是竖线,不是大字字母 I)b(a|i|e)d bad,bid,bed
. 匹配任意单个字符(包括符号、数字和空格等) b.d bad,bzd,b$d,b d
^ 指字符串开始位置的字符或子表达式 ^a apple,asdf,a
\ 转义字符(把有特殊含义的字符转换成字面形式) \.\ | \\ . | \
$ 经常用在正则表达式的末尾,表示“从字符串的末端匹配”。如果不用它,每个正则表达式实际都带着“. * ”模式,只会从字符串开头进行匹配。这个符号可以看成是 ^ 符号的反义词 [A-Z]*[a-z]*$ ABCabc,zzzyx,Bob
?! “不包含”。这个奇怪的组合通常放在字符或正则表达式前面,表示字符不能出现在目标字符串里。这个符号比较难用,字符通常会在字符串的不同部位出现。如果要在整个字符串中全部排除某个字符,就加上 ^ 和 $ 符号 ^((?![A-Z]).)*$ no-caps-here,$ymb0lsa4e f!ne
正则表达式re.S的用法
在Python的正则表达式中,有一个参数为re.S。它表示“.”(不包含外侧双引号,下同)的作用扩展到整个字符串,包括“\n”。看如下代码:
复制代码
import re
a = '''asdfsafhellopass:
234455
worldafdsf
'''
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print 'b is ' , b
print 'c is ' , c
复制代码
运行结果如下
b is []
c is ['pass:\n\t234455\n\t']
正则表达式中,“.”的作用是匹配除“\n”以外的任何字符,也就是说,它是在一行中进行匹配。这里的“行”是以“\n”进行区分的。a字符串有每行的末尾有一个“\n”,不过它不可见。
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
获取属性
对于一个标签对象,可以用下面的代码获取它的全部属性
myTag.attrs
要注意这行代码返回的是一个 Python 字典对象,可以获取和操作这些属性。比如要获取图片的资源位src ,可以用下面这行代码:
myImgTag.attrs["src"]