进程创建
-
如何创建一个子进程
通过复制调用进程,创建一个新的进程,我们称这个新的进程为子进程。
复制的是父进程的PCB,因此父进程与子进程的关系就为代码共享,数据独有。 -
具体实现方法
通过调用fork()函数 函数原型 pid_t fork(void) -
返回值
创建子进程成功,则有了两个进程,那我们如何对这两个进程进行区分呢,那便是通过fork()函数的返回值来判断,对于父进程返回的是子进程的pid,pid>0,而对于子进程返回值为0,若创建失败,返回-1。
代码实现创建一个子进程

循环创建n个子进程
- 是不是一个for()循环就可以解决问题了呢?答案肯定不是,因为我们如果把fork()函数直接放在循环里,那么产生的子进程还会产生子进程,那么进程就会成指数增长如下:
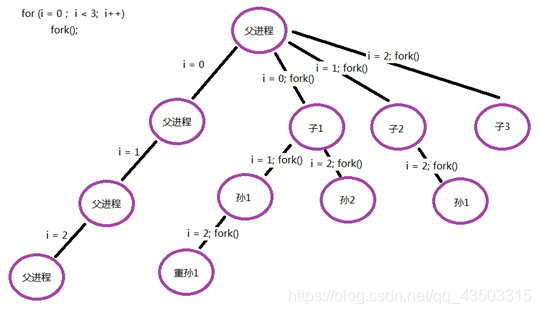
从上图我们可以很清晰的看到,当n为3时候,循环创建了(2^n)-1个子进程,而不是N的子进程。需要在循环的过程,保证子进程不再执行fork ,因此当(fork() == 0)时,子进程应该立即break;才正确。
- 假如通过命令行参数指定创建进程的个数,那么我们如何实现呢?直接上代码
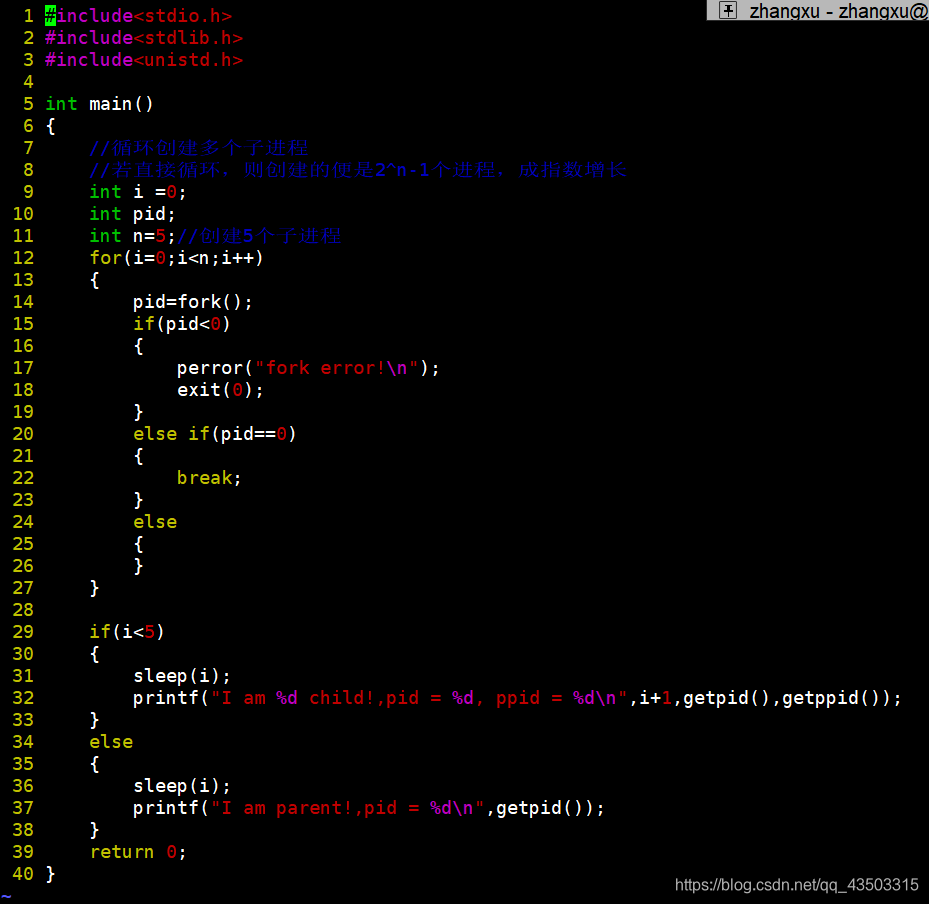
结果如下:
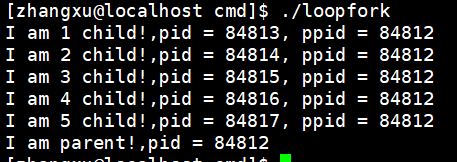
进程共享
父子进程之间在fork后。有哪些相同,那些相异之处呢?
刚fork之后:
- 父子相同处: 全局变量、.data、.text、栈、堆、环境变量、用户ID、宿主目录、进程工作目录、信号处理方式…
- 父子不同处: 1.进程ID 2.fork返回值 3.父进程ID 4.进程运行时间 5.闹钟(定时器) 6.未决信号集
似乎,子进程复制了父进程0-3G用户空间内容,以及父进程的PCB,但pid不同。真的每fork一个子进程都要将父进程的0-3G地址空间完全拷贝一份,然后在映射至物理内存吗?
当然不是!父子进程间遵循读时共享写时复制的原则。这样设计,无论子进程执行父进程的逻辑还是执行自己的逻辑都能节省内存开销。
注:特别的,fork之后父进程先执行还是子进程先执行不确定。取决于内核所使用的调度算法。