Azkaban简述
1,什么是 Azkaban?
- Azkaban是 Linkedin(领英)公司推出的一个开源的批量工作流任务调度
- 用于在一个工作流内以一个特定的顺序运行一组工作和流程。
- 使用 Job 配置文件建立任务之间的依赖关系,并提供一个易于使用的 Web 用户界面维护和跟踪你的工作流。
2,为什么需要工作流调度器?
- 1,一个完整的数据分析系统通常都是由大量任务单元组成:Shell 脚本程序、Java 程序、MapReduce 程序、Hive 脚本等。
- 2,各任务单元之间存在时间先后及前后依赖关系。
- 3,为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。
3,工作流调度实现方式
- 1,简单的任务调度
直接使用 Linux 的 crontab 来定义; - 2 ,复杂的任务调度
开发调度平台或使用现成的开源调度系统,比如 Ooize、Azkaban 等。
4,Azkaban 与 Oozie 对比
Ooize 相比 Azkaban 是一个重量级的任务调度系统,功能全面,但是 Ooize 配置工作流的过程需编写大量的 XML 配置,而且代码复杂度比较高,不易于二次开发。
若不在意某些功能的缺失,轻量级调度器 Azkaban 是很不错的候选对象
5,Azkaban 特点
- 1,兼容所有 Hadoop 版本(1.x,2.x,CDH)
- 2,提供功能清晰,简单易用的 Web UI 界面
- 3,可以通过 UI 配置定时调度
- 4,提供 Job 配置文件快速建立任务和任务之间的依赖关系
- 5,提供模块化和可插拔的插件机制,原生支持command、Java、Hive、Pig、Hadoop
- 6 ,可以重试失败的 Job
- 7 ,基于 Java 开发,代码结构清晰,易于二次开发
Azkaban2.5.0 安装
Azkaban 运行模式
1,三个重要组件

| 关系型数据库(目前仅支持MySQL) |
|---|
| Web管理服务器-Azkaban Web Server |
| 执行服务器-Azkaban Executor Server |
2,运行模式
| solo server mode | two server mode | multiple executor mode |
|---|---|---|
| 单机模式 | 使用MySQL数据库 | 使用MySQL数据库 |
| 数据库使用内置的 H2 数据库 | Web Server 和 Executor Server 运行在不同进程中 | Web Server 和 Executor Server 可运行在不同的服务器中 |
| Web Server 和 Executor Server 运行在同一个进程中 | 该模式适用于大规模应用 | Executor Server 可以有多个 |
| 任务量不大的项目可以采用此模式 |
其实在单机模式中,AzkabanSingleServer 进程只是把 AzkabanWebServer 和 AzkabanExecutorServer 合到一起启动而已。
3.0版本增加的运行模式,适合分布式部署,能够1个 Web Server 对应多 Executor Server
2.5版本,都不适合分布式部署,不能实现 1个 Web Server 对应多 Executor Server
2,Azkaban2.5.0 安装详解
1,前期准备
-
(1)版本选择
由于 Azkaban3.0 以上没有相应的安装包,需要从源码进行编译。所以呢,在这里我们2.5版本,使用 Azkaban 第二种运行模式,Web 管理服务器(Web Server)、执行服务器(Executor Server)分进程,但在同一台主机上。 -
2,下载安装包
下载地址:http://azkaban.github.io/downloads.html
版本号:Azkaban Executor 执行服务器 azkaban-executor-server-2.5.0.tar.gz Azkaban Web 服务器 azkaban-web-server-2.5.0.tar.gz Azkaban 初始化脚本文件 azkaban-sql-script-2.5.0.tar.gz -
3,上传并解压
-
(1)将 Azkaban 安装包上传到 Linux 服务器,最好上传到安装 Hive、Sqoop 的机器上,方便命令的执行。
-
(2)解压到相应目录
1,创建文件夹mkdir /home/theone/Desktop/software/azkaban-2.5.02,解压 Excutor 执行服务器
tar -zxvf azkaban-executor-server-2.5.0.tar.gz -C /home/theone/Desktop/software/azkaban-2.5.0/3,解压 Web 服务器
tar -zxvf azkaban-web-server-2.5.0.tar.gz -C /home/shiny/Desktop/software/azkaban-2.5.0/4,解压初始化脚本文件
tar -zxvf azkaban-sql-script-2.5.0.tar.gz -C /home/shiny/Desktop/software/azkaban-2.5.0/
-
2,数据库设置
- 1,安装MySQL
- 2,设置 MySQL 账户
-
1,进入 MySQL
mysql -u用户 -p密码 -
2,设置
(1)为 Azkaban 创建数据库,数据库名字不一定是 azkabanmysql> CREATE DATABASE azkaban;(2)创建 Azkaban 数据库的用户,并为用户设置密码
mysql> CREATE USER 'shiny'@'%' IDENTIFIED BY '123456'; shiny:用户名 %:所有主机 123456:密码(3)增加用户对 azkaban 数据库的所有权限
mysql> GRANT ALL PRIVILEGES ON azkaban.* TO 'theone'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION; azkaban.*:数据库.表(*代表该数据库下所有表)(4)刷新
mysql> FLUSH PRIVILEGES;
-
3,创建 Azkaban 的表
-
1,sql文件位置
表创建语句都在 azkaban-sql-script-2.5.0.tar.gz
-
2,在 MySQL 中运行sql文件
(1)使用数据库mysql> USE azkaban;(2)导入sql文件
mysql> SOURCE /home/theone/Desktop/software/azkaban-2.5.0/azkaban-2.5.0/create-all-sql-2.5.0.sql;(3)验证
mysql> SHOW TABLES;
4,获取 MySQL JDBC 驱动包
- 检查 azkaban-web-2.5.0 和 azkaban-executor-2.5.0 的 lib 目录下是否有 MySQL JDBC 驱动包

3,设置 Azkaban Web Server
1,生成 Jetty SSL 密钥文件
-
1,创建密钥文件 keystore
- (1)进入 Azkaban 的安装目录:[theone@hadoop01 ~]$ cd Desktop/software/azkaban-2.5.0
- (2)创建密钥文件 keystore:[theone@hadoop01 azkaban-2.5.0]$ keytool -keystore keystore -alias jetty -genkey -keyalg RSAkeytool 是一个密钥和证书管理工具 -keystore 指定密钥仓库文件名称及其位置 -alias 产生别名,每个keystore都关联这一个独一无二的alias,不区分大小写 -genkey 创建一个密钥仓库文件,并产生相应别名 -keyalg 指定密钥的算法,默认为DSA -
2,移动位置
在当前目录生成一个 keystore 文件。将 keystore 拷贝到 Azkaban Web Server 目录中。

2,修改配置文件 azkaban.properties
-
1,进入 azkaban-web-2.5.0/conf 目录下,并编辑
[theone@hadoop01 ~]$ cd /home/theone/Desktop/software/azkaban-2.5.0/azkaban-web-2.5.0/conf [theone@hadoop01 conf]$ vim azkaban.properties -
2,修改时区
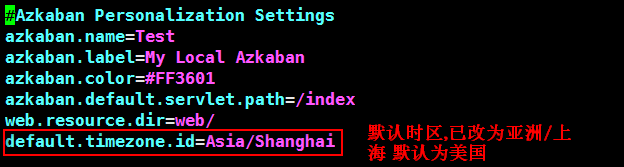
-
3,建立 UserManager
Azkaban 使用 UserManager 提供身份验证和用户角色。

默认,Azkaban 使用 XmlUserManager,并从 azkaban-users.xml 文件获取用户名/密码以及角色。 -
4,修改 MySQL 数据库配置

目前,MySQL 是 Azkaban 唯一支持的数据存储类型。所以 dse.type 应该永远是 MySQL。 -
5,修改 Jetty 服务器属性,包括 keystore 的相关配置

3,用户配置 azkaban-users.xml
-
1,进入azkaban-web-2.5.0/conf 目录下,并编辑
cd /home/theone/Desktop/software/azkaban-2.5.0/azkaban-web-2.5.0/conf vim azkaban-users.xml -
2,增加管理员用户

-
4,启动 Azkaban Web Server
(1)进入azkaban-web-2.5.0/目录cd Desktop/software/azkaban-2.5.0/azkaban-web-2.5.0/(2)启动进程 AzkabanWebServer
bin/azkaban-web-start.sh

4,设置 Azkaban executor Server
1,修改配置文件 azkaban.properties
-
1,进入azkaban-executor-2.5.0/conf 目录下,并编辑
[theone@hadoop01 ~]$ cd /home/theone/Desktop/software/azkaban-2.5.0/azkaban-executor-2.5.0/conf [theone@hadoop01 conf]$ vim azkaban.properties -
2,修改时区

-
3,修改 MySQL 数据库配置

2,启动 Azkaban executor Server
-
1,进入azkaban-executor-2.5.0/目录
cd Desktop/software/azkaban-2.5.0/azkaban-executor-2.5.0/ -
2,启动进程AzkabanExecutorServer
bin/azkaban-executor-start.sh

5,验证
1,登录页面

在浏览器中输入 https://服务器IP地址:8443
登录中输入管理员用户名及密码
2,主页信息

如果能够看到 Azkaban 的主页,就说明你已经将 Azkaban 安装成功了,congratulations!!!
Azkaban 实战演示
1,界面功能说明

| Projects | 每个独立的 Flows 都对应一个 Projects,Flows 将在 Projects 中运行 |
|---|---|
| Scheduling | 显示定时执行任务 |
| Executing | 显示正在执行的任务 |
| History | 显示历史执行任务 |
2,Command 类型任务流编写
在 Azkaban 中,一个 project 包含一个或多个 flows,一个 flow 包含多个 job。job 是你想在 Azkaban 中运行的一个进程,可以是 Command,也可以是一个 Hadoop 任务。当然,如果你安装相关插件,也可以运行插件。一个 job 可以依赖于另一个 job,这种多个 job 和它们的依赖组成的图表叫做 flow。本文介绍如何在 Azkaban上编写 Command 类型任务流。
1,单一 job 示例
-
1,创建 job 描述文件 command.job
-
编辑
[theone@hadoop01 test]$ vim command.job -
内容
#command.job type=command command=echo 'hello'type:运行的类型
command:一条 Linux 命令
-
-
2,将 job 资源文件打成 zip 包

[theone@hadoop01 test]$ zip command.zip command.job -
3,复制到 windows 本地
[theone@hadoop01 test]$ sz command.zip -
4,通过 Azkaban 的 Web 管理平台创建 project 并上传 job 压缩包
(1)创建 project


(2)上传 zip


(3)启动 job



(4)查看结果


2,多 job 工作流 flow
-
1,创建有依赖关系的多个 job 描述
-
第一个job:stepone.job
#stepone.job type=command command=echo 'stepone' -
第二个job:steptwo.job 依赖 stepone.job
#steptwo.job type=command dependencies=stepone command=echo 'steptwo'dependencies:设置依赖关系。定义该文件依赖的文件,值为被依赖文件的文件名,多个目标以逗号分隔。
dependencies=stepone:指的是 steptwo 依赖于 stepone,即需要等待 stepone.job 执行完成才能执行steoptwo.job。
-
-
2,将所有的资源打成一个 zip 包
[theone@hadoop01 test]$ zip dependencies.zip stepone.job steptwo.job -
3,复制到 windows 本地
[theone@hadoop01 test]$ sz dependencies.zip -
4,创建 project 并上传 job 压缩包
(1)上传 zip
(2)启动工作流 flow

(3)分别查看结果

stepone 执行结果

steptwo 执行结果

3,操作 HDFS 任务
-
1,创建 job 描述文件 hdfs.job
#hdfs.job type=command command=hadoop fs -mkdir -p /azkaban/hdfs -
2,将 job 资源文件打成 zip 包
[theone@hadoop01 test]$ zip hdfs.zip hdfs.job
-
3,复制到 windows 本地
[theone@hadoop01 test]$ sz hdfs.zip
创建 project 并上传 job 压缩包
(1)上传 zip
(2)启动 job
(3)查看结果


执行结果
(4)HDFS验证

- 5,设置调度时间
- 创建 project 并上传 job 压缩包

- 设置调度时间

- 查看

- 创建 project 并上传 job 压缩包
4,操作 MapReduce 任务
-
1,创建 job 描述文件 mapreduce.job
#mapreduce.job type=command command=hadoop jar /home/theone/Desktop/software/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 10 10 -
2,将 job 资源文件打成 zip 包
[theone@hadoop01 test]$ zip mapreduce.zip mapreduce.job
-
3,复制到 windows 本地
[theone@hadoop01 test]$ sz mapreduce.zip -
4,创建 project 并上传 job 压缩包
(1)上传 zip
(2)启动 job
(3)查看结果

执行结果

4,操作 Hive 脚本任务
-
1创建 Hive 脚本 hive.sql
CREATE DATABASE azhive; USE azhive; CREATE TABLE azstudent(id INT,name STRING,age INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; LOAD DATA LOCAL INPATH '/home/theone/Desktop/test/student.txt' INTO TABLE azstudent; SELECT * FROM azstudent;
注意放置路径
-
2,创建 job 描述文件
#hivef.job type=command command=hive -f '/home/theone/Desktop/test/hive.sql' -
3,将 job 资源文件打成 zip 包
[theone@hadoop01 test]$ zip hivef.zip hivef.job -
4,student.txt 内容
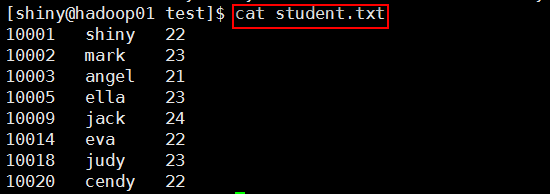
注意放置路径 -
5,复制到 windows 本地
[theone@hadoop01 test]$ sz hivef.zip -
6,创建 project 并上传 job 压缩包
(1)上传 zip
(2)启动 job
(3)查看结果
