文章目录
本周三公司的yarn集群出现故障,导致两台ResourceManger频繁易主,并且许多提交到集群的任务状态为 NEW_SAVING,无法执行。这里对此次的故障排查进行一个总结。
一、故障现象
- 两个节点的ResourceManger频繁在active和standby角色中切换。不断有active易主的告警发出
- 许多任务的状态没能成功更新,导致一些任务状态卡在NEW_SAVING无法进入调度(还有许多资源空闲)
看了下ResourceManger的日志,发现大量以下错误:
org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss
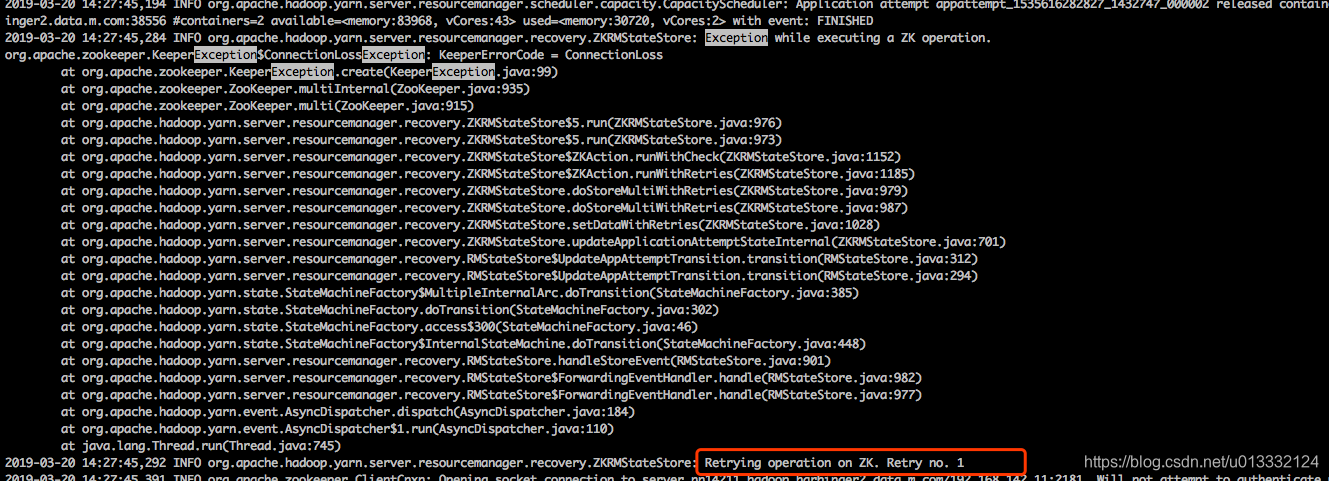
从日志可以看出是在操作zk时出现了错误,并且会进行重试。RM在重试1000次后才会放弃尝试。并且从日志可以看出,这是在更新任务appattempt_1535616282827_1432747_000002的状态时发生的异常。
紧接着后面还发现另外一条日志,表示此时RM的状态进入了standby:
2019-03-20 14:37:48,914 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioning to standby state
RM进入standby状态前会将对应的ZK节点/yarn/ActiveStandbyElectorLock删除,然后再转到standby状态。这时两台RM同时开始竞争尝试新建/yarn/ActiveStandbyElectorLock节点,谁竞争到谁就是active。
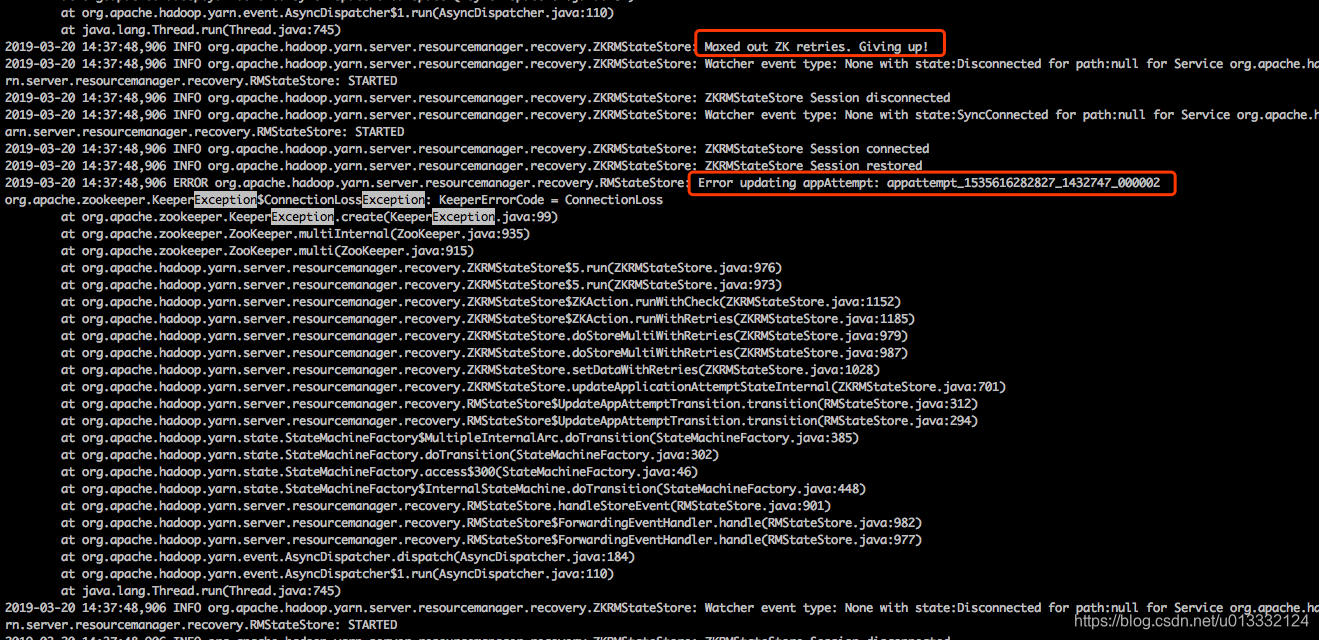
成为active的节点又收到appattempt_1535616282827_1432747_000002的状态更新,就尝试更新zk节点的数据,然后又发生上面的错误,重试1000次后转为standby。如此一直重复下去,直到人为介入kill了该任务,集群才恢复正常。
因为是zk操作的问题,所以看了下zk的日志,也发现了异常:
2019-03-20 14:37:40,141 [myid:1] - WARN [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@362] - Exception causing close of session 0x16324e8243d0003 due to java.io.IOException: Len error 2186401
2019-03-20 14:37:40,142 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@1007] - Closed socket connection for client /192.168.142.10:23412 which had sessionid 0x16324e8243d0003
从日志上看,只有appattempt_1535616282827_1432747_000002这个任务状态会更新失败,其他任务的状态都可以正常更新,有一些任务会因为zk连接被关闭而更新失败,这个后面解释原因。
二、问题分析
RM的HA机制分析
之前一直以为RM只有在和zk失联,/yarn/ActiveStandbyElectorLock节点断开后才会进行易主。但是这次的异常却颠覆了我的认知。于是去跟了下yarn的源码。发现还有一种情况可能导致RM从active状态切换到standby状态。
RM在进行任务状态更新时,会进行对应的zk操作,也就是将任务的相关信息存储到zk。如果这个失败,RM会进行重试,这个重试的次数可以通过yarn.resourcemanager.zk-num-retries配置,默认是1000次。当对应的zk操作失败重试达到1000次,RM就会将状态切换到standby。
具体可能导致active切换成standby的操作有以下这些:
- storeApplicationStateInternal
- updateApplicationStateInternal
- removeApplicationStateInternal
- storeApplicationAttemptStateInternal
- updateApplicationAttemptStateInternal
- storeRMDelegationTokenState
- removeRMDelegationTokenState
- updateRMDelegationTokenState
- storeRMDTMasterKeyState
- removeRMDTMasterKeyState
- storeOrUpdateAMRMTokenSecretManagerState
所以我们上面的故障很明显就是在某个任务的updateApplicationAttemptStateInternal操作出现异常后,才导致active在两个RM节点间不断切换的。
如果配置了多个RM,客户端根据yarn-site.xml的配置会采用round-robin的方式逐个去连接RM,直到找到active 节点位置。所以即使active节点切换,在运行中的客户端也能通过这种方式重新找到新的Active RM进行连接。
ZK问题分析
上面的故障其实归根结底还是zk的问题。zk的这条日志Exception causing close of session 0x16324e8243d0003 due to java.io.IOException: Len error 2186401也很明确的表明是由于客户端发来的请求包太大,zk主动关闭了连接。
上网搜了下zk的Len error的问题,发现也有一些人碰到过。甚至找到两个相关的issue,一个是yarn的,一个是zookeeper的:
https://issues.apache.org/jira/browse/YARN-3469
https://issues.apache.org/jira/browse/ZOOKEEPER-706
其中zk的issue是说如果一个请求要注册的watcher太多,会导致Len error的问题。因此这个issue的patch是将这些watcher分成多个请求发送,这样就不会导致请求过大的问题了。刚好修复版本是3.4.7,而我们集群用的zk版本是3.4.6。
yarn的issue是说之前的版本设置了过多无用的watcher,导致某个请求太大,出现Len error的问题。因此yarn这边做的修复是不在注册无用的watcher。修复版本是2.6.0,我们集群用的版本是2.7.4,因此我们集群应该不会有这个问题。
因为排查时已经无法找到那个请求包的具体内容,这两个issue看上去又很有说服力。虽然yarn已经修复了注册过多无用watcher的,但是可能还有一些地方还有类似的问题呢。
本来以为问题大概就是这样了,我们已经准备升级zk版本了。突然又想到失败的zk操作是updateApplicationAttemptStateInternal,它底层的zk操作是setData,而setData是不会注册任何watcher的。因此这个问题和watcher没有任何关系。
后面继续排查,发现下面这篇博客:
https://www.jishuwen.com/d/2BBc/zh-hk#tuit
和我们的故障现象很像,于是追到了博客提到的yarn的issue:
https://issues.apache.org/jira/browse/YARN-2368
ResourceManager failed when ZKRMStateStore tries to update znode data larger than 1MB。也就是我们遇到的问题。就是要更新的任务信息过大导致的,和watcher没有关系。
这issue并没有修复的版本,看了下它的patch,就是加了一个配置,用来指定jute.maxbuffer,也就是通过调大zk的阀值来避免出现该问题。
部分任务状态更新失败问题分析
从日志看,只有appattempt_1535616282827_1432747_000002这个任务因为更新内容过大导致zk操作失败。但是故障时看到的现象确实许多任务状态都卡在NEW_SAVING无法更新。这是为什么呢?
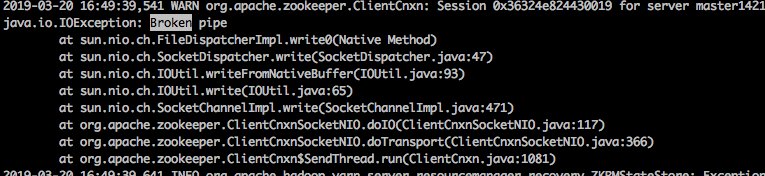
通过分析日志,可以很容易得出结论。RM在更新appattempt_1535616282827_1432747_000002状态失败时,zk服务端主动断掉了连接,RM在下次重试时就会再次尝试建立连接。
因为任务状态更新用的zk连接可能是同一个,如果要更新时刚好连接被关闭了,任务肯定无法成功更新。因此才会有部分任务状态可以更新,部分任务状态无法更新的现象。
在RM的日志中我们也可以看到许多下面的Broken pipe异常:
三、解决和优化方案
1. 调大 jute.maxbuffer 参数
通过调大jute.maxbuffer来让zk可以接受更大的请求包而不会抛出IOException。这个参数的默认值是1M。
注意,这个不是在zk的配置文件中设置。而是作为java参数在启动zk时设置,也就是-Djute.maxbuffer=xxxx的方式。
另外,根据zk的文档,这个参数在所有的客户端和zk服务端都要设置,否则会有更多的问题产生。也就是说,我们需要在yarn这边也设置这个参数。
这种方式有点治标不治本,因为我们无法知道任务信息最大可能到多少。设置过大的值也不是个好主意。最重要的是这个方案要同时对yarn和zk进行重启,风险略高。
2. 修改yarn的源码
虽然知道了问题的原因所在,但是我们还不知道为什么那个任务会产生那么大的任务信息。所以我们对zk的端口进行抓包查看正常的任务信息的请求都有多大:
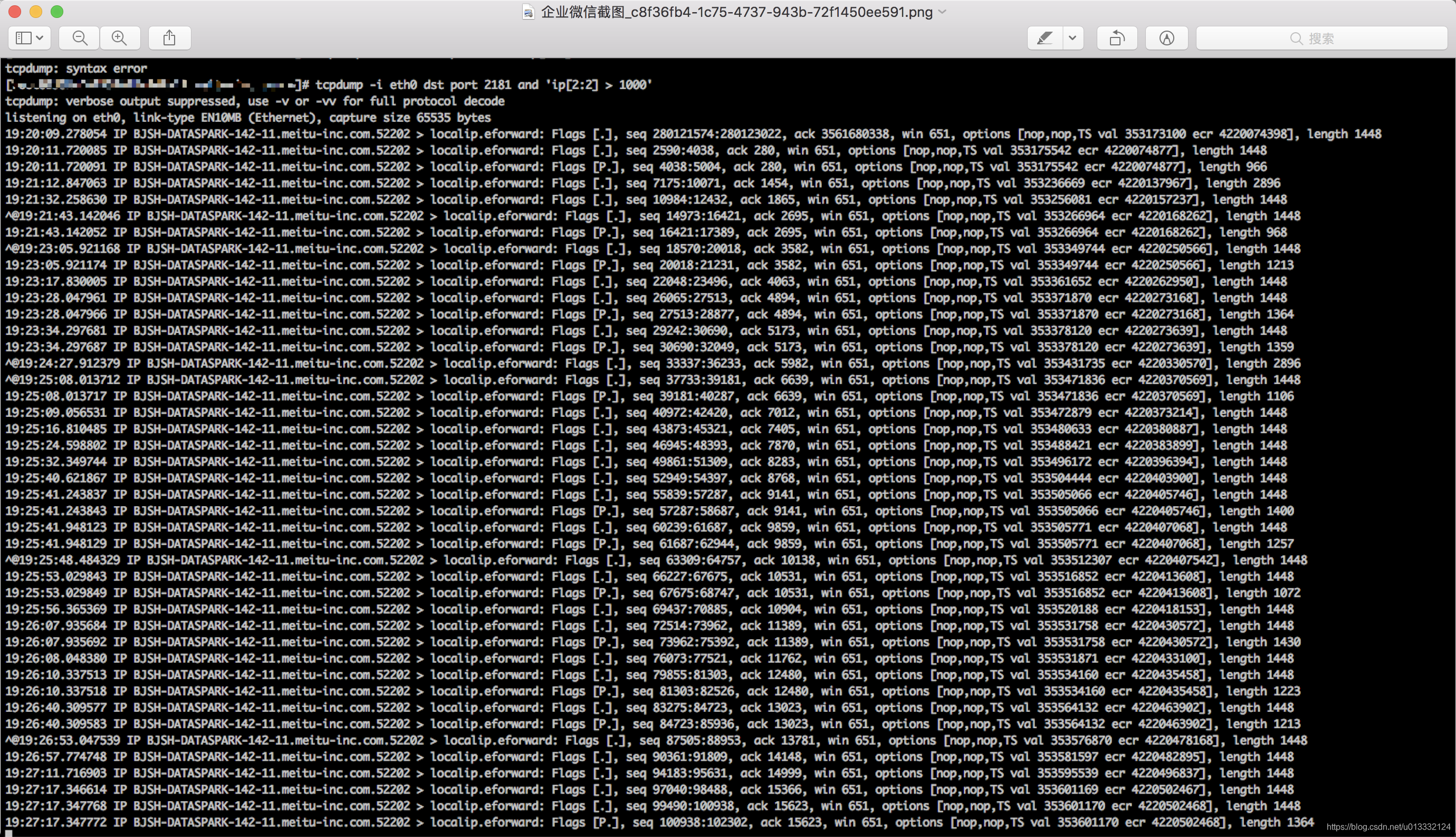
通过抓包的结果,我们发现正常任务包的大小其实都只有几K,最高不会超过5K。所以我们打算修改yarn的源码过滤掉那些大小超过1M的任务更新请求,同时把这些大于1M的请求内容打印出来。
这样做一方面是为了避免后面因为某个任务的更新失败又导致集群出现问题,另一方面也可以观察到为什么有的任务会产生那么大的信息。
附上更新的代码,ZKRMStateStore#updateApplicationAttemptStateInternal()
byte[] attemptStateData = attemptStateDataPB.getProto().toByteArray();
//测试环境可以加上下面这个日志,实时观察各个任务信息的大小
LOG.info(String.format("attempId:%s,len:%s",attemptStateDataPB.getAttemptId(),attemptStateData.length));
//如果任务信息超过了950K,就打出error日志,输出任务信息,同时直接返回,不再往zk发送请求
if(attemptStateData.length > 972800){
LOG.error(String.format("attemptStateData len larger than 1M.len:%s,nodeUpdatePath:%s,data:%s,attemptId:%s,Diagnostics:%s,traceUrl:%s,container%s",
attemptStateData.length,nodeUpdatePath,String.valueOf(attemptStateData),attemptStateDataPB.getAttemptId(),attemptStateDataPB.getDiagnostics(),
attemptStateDataPB.getFinalTrackingUrl(),attemptStateDataPB.getMasterContainer()));
return;
}
//往zk发送请求更新任务信息
if (existsWithRetries(nodeUpdatePath, false) != null) {
setDataWithRetries(nodeUpdatePath, attemptStateData, -1);
} else {
createWithRetries(nodeUpdatePath, attemptStateData, zkAcl,
CreateMode.PERSISTENT);
LOG.debug(appAttemptId + " znode didn't exist. Created a new znode to"
+ " update the application attempt state.");
}
3. 快速让集群恢复稳定的方法
如果集群又发生了类似的问题,可以找到任务的ApplicationMaster所在的Container,然后上目标服务器将对应的Container进程kill掉,后面RM就不会再更新该任务的信息,而是将任务直接转为Kill状态。
四、总结
此次故障大概持续了2个半小时才恢复,还是刚好业务同学手动kill了那个任务的container进程,最终才没有一直切换下去。
因为之前对yarn只有原理上的认知,并没有看过yarn的代码,对yarn状态机的相关知识也了解不多。所以在故障发生时有点手足无措,不知道从何下手排查。
此刻回想起来真的很侥幸,因为这个故障不是重启一下RM就能恢复的。如果业务同学没有刚好kill那个container进程,可能我们要一直排查到分析出问题的根本原因为止,至少要多半天的时间。
后面还是要多看看集群各个组件的源码,深入了解他们的架构,争取出现问题时能更快的定位到问题并修复。