3.1
式3.2 $f(x)=\omega ^{T}x+b$ 中,$\omega ^{T}$ 和b有各自的意义,简单来说,$\omega ^{T}$ 决定学习得到模型(直线、平面)的方向,而b则决定截距,当学习得到的模型恰好经过原点时,可以不考虑偏置项b。偏置项b实质上就是体现拟合模型整体上的浮动,可以看做是其它变量留下的偏差的线性修正,因此一般情况下是需要考虑偏置项的。但如果对数据集进行了归一化处理,即对目标变量减去均值向量,此时就不需要考虑偏置项了。
3.2
对区间[a,b]上定义的函数f(x),若它对区间中任意两点x1,x2均有$f(\frac{x1+x2}{2})\leq \frac{f(x1)+f(x2)}{2}$,则称f(x)为区间[a,b]上的凸函数。对于实数集上的函数,可通过二阶导数来判断:若二阶导数在区间上非负,则称为凸函数,在区间上恒大于零,则称为严格凸函数。
对于式3.18 $y=\frac{1}{1+e^{-(\omega ^{T}x+b)}}$,有
$\frac{dy}{d\omega ^{T}}=\frac{1}{(1+e^{-(\omega ^{T}x+b)})^{2}}e^{-(\omega ^{T}x+b)}(-x)=(-x)\frac{1}{1+e^{-(\omega ^{T}x+b)}}(1-\frac{1}{1+e^{-(\omega ^{T}x+b)}})=xy(y-1)=x(y^{2}-y)$
$\frac{d}{d\omega ^{T}}(\frac{dy}{d\omega ^{T}})=x(2y-1)(\frac{dy}{d\omega ^{T}})=x^{2}y(2y-1)(y-1)$
其中,y的取值范围是(0,1),不难看出二阶导有正有负,所以该函数非凸。
3.3
对率回归即Logis regression
西瓜集数据如图所示:
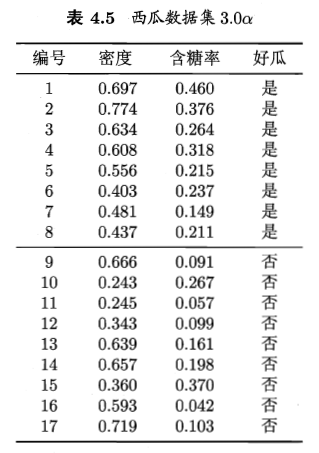
将好瓜这一列变量用0/1变量代替,进行对率回归学习,python代码如下:


import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
dataset = pd.read_csv('/home/zwt/Desktop/watermelon3a.csv')
#数据预处理
X = dataset[['密度','含糖率']]
Y = dataset['好瓜']
good_melon = dataset[dataset['好瓜'] == 1]
bad_melon = dataset[dataset['好瓜'] == 0]
#画图
f1 = plt.figure(1)
plt.title('watermelon_3a')
plt.xlabel('density')
plt.ylabel('radio_sugar')
plt.xlim(0,1)
plt.ylim(0,1)
plt.scatter(bad_melon['密度'],bad_melon['含糖率'],marker='o',color='r',s=100,label='bad')
plt.scatter(good_melon['密度'],good_melon['含糖率'],marker='o',color='g',s=100,label='good')
plt.legend(loc='upper right')
#分割训练集和验证集
X_train,X_test,Y_train,Y_test = model_selection.train_test_split(X,Y,test_size=0.5,random_state=0)
#训练
log_model = LogisticRegression()
log_model.fit(X_train,Y_train)
#验证
Y_pred = log_model.predict(X_test)
#汇总
print(metrics.confusion_matrix(Y_test, Y_pred))
print(metrics.classification_report(Y_test, Y_pred, target_names=['Bad','Good']))
print(log_model.coef_)
theta1, theta2 = log_model.coef_[0][0], log_model.coef_[0][1]
X_pred = np.linspace(0,1,100)
line_pred = theta1 + theta2 * X_pred
plt.plot(X_pred, line_pred)
plt.show()
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
dataset = pd.read_csv('/home/zwt/Desktop/watermelon3a.csv')
#数据预处理
X = dataset[['密度','含糖率']]
Y = dataset['好瓜']
good_melon = dataset[dataset['好瓜'] == 1]
bad_melon = dataset[dataset['好瓜'] == 0]
#画图
f1 = plt.figure(1)
plt.title('watermelon_3a')
plt.xlabel('density')
plt.ylabel('radio_sugar')
plt.xlim(0,1)
plt.ylim(0,1)
plt.scatter(bad_melon['密度'],bad_melon['含糖率'],marker='o',color='r',s=100,label='bad')
plt.scatter(good_melon['密度'],good_melon['含糖率'],marker='o',color='g',s=100,label='good')
plt.legend(loc='upper right')
#分割训练集和验证集
X_train,X_test,Y_train,Y_test = model_selection.train_test_split(X,Y,test_size=0.5,random_state=0)
#训练
log_model = LogisticRegression()
log_model.fit(X_train,Y_train)
#验证
Y_pred = log_model.predict(X_test)
#汇总
print(metrics.confusion_matrix(Y_test, Y_pred))
print(metrics.classification_report(Y_test, Y_pred))
print(log_model.coef_)
theta1, theta2 = log_model.coef_[0][0], log_model.coef_[0][1]
X_pred = np.linspace(0,1,100)
line_pred = theta1 + theta2 * X_pred
plt.plot(X_pred, line_pred)
plt.show()
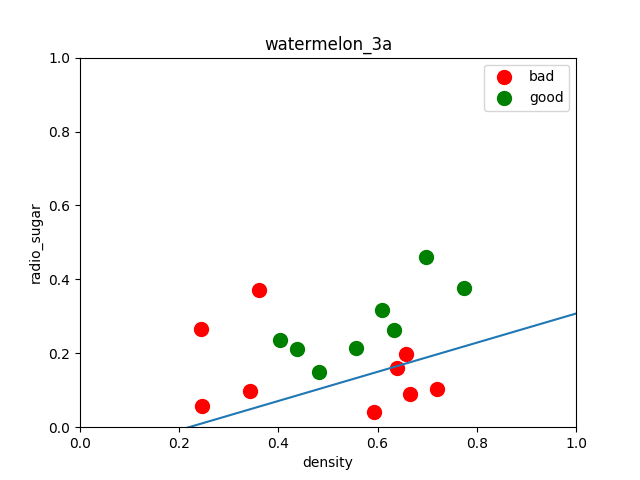
模型效果输出(查准率、查全率、预测效果评分):
precision recall f1-score support
Bad 0.75 0.60 0.67 5
Good 0.60 0.75 0.67 4
micro avg 0.67 0.67 0.67 9
macro avg 0.68 0.68 0.67 9
weighted avg 0.68 0.67 0.67 9
也可以输出验证集的实际结果和预测结果:
密度 含糖率 Y_test Y_pred
1 0.774 0.376 1 1
6 0.481 0.149 1 0
8 0.666 0.091 0 0
9 0.243 0.267 0 1
13 0.657 0.198 0 0
4 0.556 0.215 1 1
2 0.634 0.264 1 1
14 0.360 0.370 0 1
10 0.245 0.057 0 0
3.4
3.5
3.6
对于非线性可分的数据,要想使用判别分析,一般思想是将其映射到更高维的空间上,使它在高维空间上线性可分进一步使用判别分析。
3.7
3.8
理论上的(纠错输出码)ECOC码能理想纠错的重要条件是每个码位出错的概率相当,因为如果某个码位的错误率很高,会导致这位始终保持相同的结果,不再有分类作用,这就相当于全0或者全 1的分类器。
3.9
书中提到,对于OvR,MvM来说,由于对每个类进行了相同的处理,其拆解出的二分类任务中类别不平衡的影响会相互抵消,因此通常不需要专门处理。以ECOC编码为例,每个生成的二分类器会将所有样本分成较为均衡的二类,使类别不平衡的影响减小。当然拆解后仍然可能出现明显的类别不平衡现象,比如一个超级大类和一群小类。
3.10