版权声明:本文为博主原创文章,未经许可不得转载。 https://blog.csdn.net/u014765410/article/details/88919362
下面提及的处理方法都可以用于data preprocessing中,要懂借鉴!
比如:搜索text1中“最常出现50个单词”,“最长的50个单词”,…,通过挖掘这些信息,可以挖出text1中主题。
1、搜索文本
>>>import nltk
>>>nltk.download() #下载资源
>>>from nltk.book import * #可以导入book中的所有数据条
text2: Sense and Sensibility by Jen Austen 1811
>>>text2
Text:Sense and Sensibility by Jen Austen 1811>
>>>text1.concordance("monstrous") #查看文本text1中,单词“monstrous”出现的次数
>>>text1.similar("monstrous") #查看与单词“monstrous”拥有相似上下文的 单词
>>>text1.common_contexts(["monstrous","very"]) #返回2个单词共同(有)的上下文
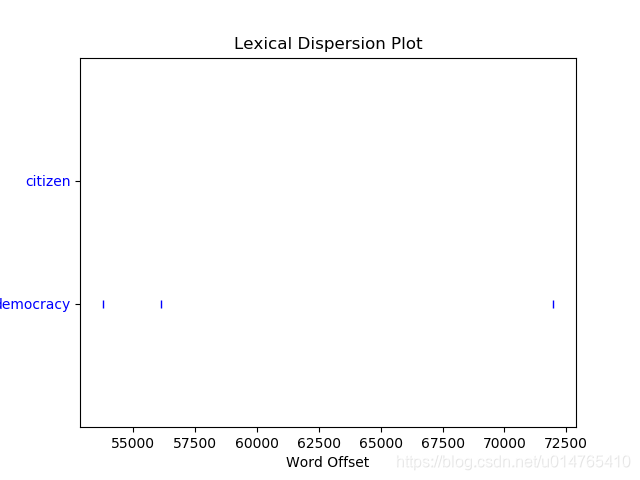
>>>text1.dispersion_plot(["citizen","democracy"]) #绘出两个单词在text1文本中的离散图(Lexical Dispersion Plot),每一行代表一个文本(text1),每个竖线为一个单词,图表示了在文本中的word之前有多少单词;
>>>text1.generate() #产生text1风格的文本;出错;原因:我使用的是nltk3.2.4和Python3.4.4,该版本下generate函数被注释了,所以无法使用。而《python自然语言处理时》书中用的是NLTK2.0版本。
2、词汇计数
>>>len(text1) #记录的出现的 标识符 的总数
>>>len(set(text1)) #记录vocabulary的长度
>>>from __future__ import division #引入精确除法,python3中不用此句
>>>len(text1)/len(set(text1))
>>>text1.count('smoke') #返回text1中smoke出现次数
>>>text1.count('smoke')/len(text1) #smoke在dictionary中占比例
#关于链表的一些知识点
>>>[length1] + [length2] #两个链表可以直接相加
>>>list.index('awaken') #返回该word的指针
#关于string的一些知识点
>>>a='string'
>>>a * 2
'stringstring'
>>>a + '!'
'string!'
>>>''.join(['Monty','Python'])
'MontyPython'
>>>'this is a book'.split()
['this', 'is', 'a', 'book']
3、简单的统计
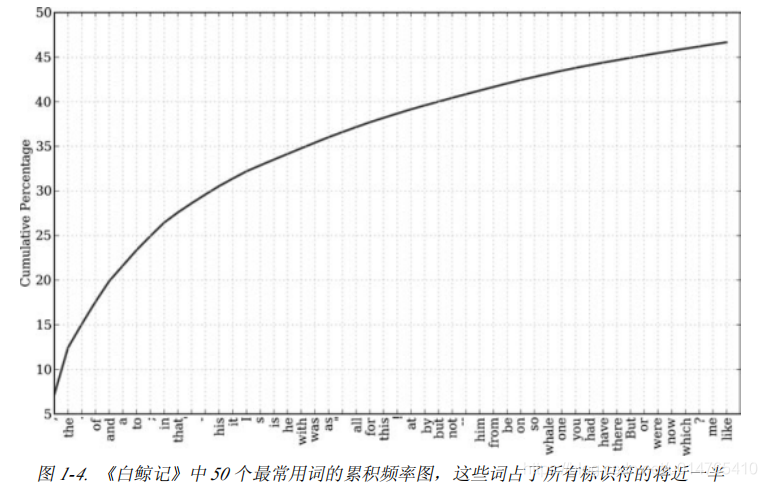
>>>fdist1 = FreqDist(text1) #返回一个dict,key为word,value为其在文本中出现的频次
>>>fdist1.plot(50,cumulative=True) #见图(1-4)
#光看“高频词汇” 和 “低频词汇” 是无法抓住text的主题的,因为这些词可能为stopwords,也可能为rare words;为找到text主题,我们在更细的粒度上去分析word
#细粒度的选择词
>>>long_words = [x for x in vocab if len(x) > 15 and fdist1[x] > 7] #返回长度>15,出现频率>7的words;book中利用该法可以有效从text中提取出主题相关信息,不过这种做法,因text而异;
#词语搭配和双连词
>>>list(bigrams(['this','is','a','book'])
[('this', 'is'), ('is', 'a'), ('a', 'book')]
>>>text1.collocations() #给出text1中经常出现的“双连词”;注:text1是nltk自带book;其它的text不能用collocations()
>>>[len(w) for w in text1] #给出文本中词长的分布
>>>fdist = FreqDist([len(w) for w in text1])
>>>fdist.items()
[(3, 50223), (1, 47933), (4, 42345), (2, 38513), (5, 26597), (6, 17111), (7, 14399),(8, 9966), (9, 6428), (10, 3528), (11, 1873), (12, 1053), (13, 567), (14, 177),(15, 70), (16, 22), (17, 12), (18, 1), (20, 1)]
>>>fdist.freq(3) #给出word length=3的词出现的频率
0.19255882431878046
>>>sorted([w for w in set(text1) if w.endswith('t')]) #写作方法
>>>[w.upper() for w in set(text1)]
#词汇计数的逐步精进
>>>len(set(text1))
>>>len(set([w.lower() for w in set(text1)]) #在词汇计数时,将word都小写并不是正确做法
>>>len(set([w.lower() for w in set(text1) if w.isalpha()]))



4、自动理解自然语言
(1)词意消歧:指的是“在不同的句子中,同一个单词有不同的意思”;
下图中,by的意思可通过“斜体单词”判断;

(2)指代消解:“代词指代的是句子中哪一部分”;
下图中代词they,究竟指代的是哪个先行词?

(3)机器翻译
>>>babelize_shell() #随机返回一段sentence的两种语言多次“互相翻译”的结果
(4)图灵测试:一个响应用户文本输入的对话系统能否表现的自然到我们无法区分它是人工生成的响应?
>>>import nltk
>>>nltk.chat.chatbots() #聊天机器人

(5)文本含义识别(Recognizing Textual Entailment 简称 RTE)
RTE任务是,给定一个Text和一个hypothesis,判定text是否能支撑hypothesis;

NLP局限性:语言理解系统仍不能进行常识推理或以一种一般的可靠的方式描绘这个世界的知识。
图书推荐:
