本片博客根据工作经验以及源码分析,根据博主自己的理解分析所得。了解之前小二建议先了解Hadoop入门及HDFS底层运行原理讲解https://blog.csdn.net/Mirror_w/article/details/89288212,
一、hadoop HA架构的角色分析
1、namenode
存储元数据,与client客户端进行交互,当服务启动时加载fsimage镜像文件和edits.log文件到自己的内存。在整个架构中,分别有处于active状态的nameNode,和处于standby状态的namenode,standby也是时刻启动的,一致在通过journalnode与actived的namenode进行数据同步,这样来保持,当active的nameNode宕机时,处于standby状态的nameNode会立即改变自己的状态为active继续工作。
2、datanode
数据储存的节点,在集群进行启动时时刻与namenode保持心跳,并且将自己节点上的数据的位置信息向namenode进行注册(只是集群启动时进行注册),datanode将自己的数据位置信息,会向两台namenode都进行注册(一台是active的,另一台是standby的)。
3、ZKFC
ZKFC是用来监听namenode运行状态的进程,当nemenode出现宕机时,zkfc会立即向zookeeper汇报,并且kill掉自己监控的出现宕机的namenode(这个机制在hadoop中称为fencing)。当出现nameNode宕机时,监控standby状态的nameNode的ZKFC,会收到zookeeper的信息,当ZKFC收到信息时,ZKFC会启动自己监控的nameNode。
4.journalnode
用于储存edits.log文件,用户储存namenode发送过来的edits.log数据信息。当客户端与namenode进行交互时,产生的edits.log文件会向journalnode进行发送,一般journalnode会是奇数台(用户自己设置,奇数台用于过半原则的高效性,这里配置3台journal),namenode产生edits.log文件时,会向3台journalnode进行发送数据(这里发送的是同一份数据),当三台里面的数据有两台发送成功(当过半的journalnode发送成功)时,表示这edits.log文件发送成功。当journalnode数据接收成功后,处于standby的nameNode会一致监控journalnode是否有数据,当journalnode上有数据时,standby的namendoe会立即将journalnode同步到自己的节点上。
5.zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
zookeeper在这里着作用是用于管理namenode的状态,来控制集群中那台只有一台namenode是处于active的。当集群启动时会通知ZKFC,让namenode来自己的znode下注册自己信息,然后zookeeper这里就可以使用自己的选举机制和投票机制来决定哪台是active的namenode了。所以所,zookeeper在这里起的作用是,通过自己的投票选举机制,选出哪台是master即哪个namenode是active状态的。
二、hadoop 2.x HA的工作原理
hadoop 2.x的框架图:

当集群开始开始启动时,namenode会将fsimage和edits.log合并并且加载到内存,然后datanode启动时将自己信息发送给standby的namenode和active的nameNode,namenode将所有的datanode注册的信息加载到内存进行运行,在namenode进行启动时伴随着自己的监控进程ZKFC开始启动,ZKFC随着namnode开始启动,namenode的ZKFC会向zookeeper进行注册namenode信息,在znode下注册信息,这是zookeeper会通过自己的投票选举机制选出哪台namenode是active的。这里集群初始化的任务开始执行完毕。
当client客户端开始提交请求任务时,Client会通过RPC(远程过程调用服务)进行与处于active的nameNode进行通信,这时namenode接收到请求后会进行请求的执行,若是文件的数据的上传,则分配datanode节点的信息返回给客户端,用于数据的储存,若是读请求,则返回请求信息中需要的数据的元信息。在nameNode进行工作的过程中,产生的edits.log文件会发送给journalnode(这里有三台journalnode,用户可以自定义,用于过半原则),当过半的journalndoe收到namenode的edits.log文件时,数据表示上传成功,这时standby的namenode会监听到,会从journal将数据拉取到自己的节点上,达到与active的数据通过状态,这样即使active的namenode宕机,也不会担心元数据的丢失,只需另一台nameNode启动即可。
1.HA架构所解决的问题
-解决了hadoop 1.x中namenode单点故障的问题,在hadoop1.x中只有一台nameNode这样当namenode宕机时,则整个集群也就处于瘫痪状态,hadoop 2.x 很好滴解决了这件事。
-hadoop2.x 还提出了hadoop federation 联邦机制,来解决namendoe内存受限的问题。
-namenode内存受限问题:整个集群中向外提供元数据服务的只有namenode,这样过多的服务会使各个服务之间的工作受限,当多个客户端进行提交请求时,namenode只能逐一对各个请求进行服务,这样造成了很大的工作效率问题。第二是namenode处理大量的请求时,由于nameNode只有一台,它的内存是一定了,处理大量的元数据信息,也有一定的限制。这样当数据进行请求交互的时候也是一个很大的问题。而这样的问题hadoop 2.x引入了联邦机制来横向扩展了namenode,增加了多台namenode。下面将详述hadoop federation联邦机制。
-namenode在内存中维护着文件系统中每个文件元数据和块的映射关系,对于一个拥有很多文件的大集群内存会成为系统扩展的限制因素。
2.hadoop federation联邦机制
hadoop联邦架构图
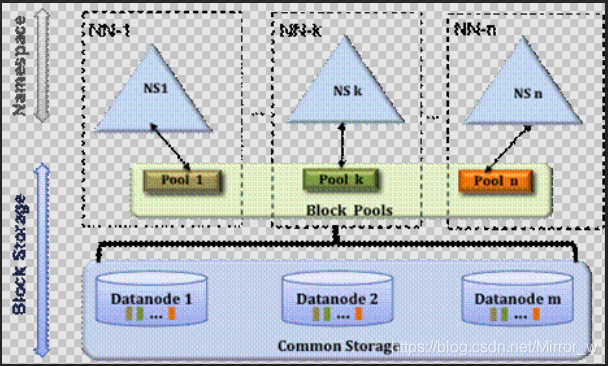
hadoop联邦机制,横向扩展了namenode,各个namenode之间进行了工作任务的分配,解决了client客户端的并发访问的难题,也解决了namenode的内存受限的问题。联邦机制扩展了多台namenode,多台namenode之间各司其职,互不影响。不同的namenode之间负责解决不同的工作。当联邦中其中一台namenode宕机时不影响其他namenode的工作。而当集群启动时,datanode会向所有的namenode进行注册数据节点信息,各个namenode会将自己所负责的数据节点注册到自己的节点上。
对于hadoop 联邦,每个nameNode管理者一个命名空间卷,该卷包含命名空间的元数据信息,和一个block池,该block池保存着该命名空间中所有的block块信息。每个命名空间是相互独立的,意味着每个nameNode不要彼此通信,同时一个命名空间的失效不会影响其他命名空间。
基于路由器的HDFS联邦:HDFS基于路由器的联邦添加了一个RPC路由层,该层提供多个HDFS命名空间的联合视图。 这与现有的ViewFs和HDFS联合功能类似,不同之处在于安装表由路由层而不是客户端在服务器端进行管理, 简化了对现有HDFS客户端对联邦群集的访问
四、hadoop 3.x的新特性
1.Yarn中的资源类型:
通过扩展yarn的资源类型,支持cpu和内存之外的其他资源 ,如GPU,FPGA.本地储存等。
2.MapReduce任务级别的本地优化:
对map阶段的输出收集器增加了本地实现,对于洗牌密集型工作提高了30%以上的性能。
3.支持两个以上的namenode:
在hadoop 2.x中只有一个active的name和一个standBy的namenode,解决了namenode单点故障的问题。在hadoop 3.x中允许多个standby的namenode,以达到高效的容错目的。
4.datanode内部的数据平衡器:
单个DataNode管理多个磁盘。 在正常写入操作期间,磁盘将被均匀填充。 但是,添加或替换磁盘可能会导致DataNode内的严重数据偏斜。 旧的HDFS平衡器不能处理,旧的HDFS平衡器处理DN之间而非内部的数据偏斜。
5.基于路由器的HDFS联邦:
HDFS基于路由器的联邦添加了一个RPC路由层,该层提供多个HDFS命名空间的联合视图。 这与现有的ViewFs和HDFS联合功能类似,不同之处在于安装表由路由层而不是客户端在服务器端进行管理, 简化了对现有HDFS客户端对联邦群集的访问。
小二推荐博文:大数据技术篇,大数据入门篇
IT时讯:「IT之家开箱」华为P30、P30 Pro图赏:穿手机外衣的时尚魔头