1、基本概念
我们需要先了解清楚的数据的概念,才能学习数据结构。
1.1、数据
数据就是一个描述客观世界的符号。例如,整型、浮点型的数字、字符以及声音、图像、视频等。
1.2、数据元素
数据元素是组成有一定意义的基本单位。例如,在人类中,人就是数据元素;鱼类中,鲫鱼、鲤鱼、草鱼等都是鱼类的数据元素。
1.3、数据项
数据项是指一个数据元素可以由若干个数据项组成。比如,数据元素是人,那么人可以有五官、四肢这些数据项,也可以有身高、体重、生日、姓名、年龄、电话等等数据项。
数据项是数据不可分割的最小单位。但是真正解决问题时,数据元素才是建立数据模型的着眼点,就像我们看一部电影,重点看的是电影角色这个[数据元素],而不是去看电影角色的姓名或生日这个[数据项]。
1.4、数据对象
数据对象是性质相同的数据元素的集合。
性质相同指集合中的数据元素具有相同数量、类型的数据项,比如我们上大学填写的学生信息表,每个人数据项的数量、类型都相同,仅是内容不同,所有人的学生信息表的集合就是数据对象。
在实际应用中,我们处理的数据元素的集合通常都具有相同性质,所以我们平时开发所说的数据指的就是数据对象。
1.5、总结

2、数据结构
结构,简单理解就是关系。严格而言,结构是指各个组成部分相互搭配和排列的方式。例如分子结构,就是指一种或多种分子组成原子的排列方式。
那数据结构呢?相互之间存在一种或多种特定关系的数据元素的集合。
数据元素是具有内在联系的集合,为了写出有效且高效的程序,需要分析待处理对象的特性及各处理对象之间的关系,这就是数据结构的意义。而在此之后,对问题提出解决方案则是算法的意义。
2.1、逻辑关系结构
逻辑关系结构就是数据对象中数据元素之间的关系。
逻辑关系结构是针对具体问题的,在对问题理解的基础上,我们需要选择一个合适的逻辑关系结构来表示数据元素之间的逻辑关系。
逻辑关系结构有以下四种:
(1)线性结构:数据元素之间是一对一的有先后顺序的平行关系。
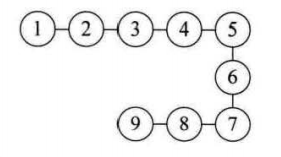
(2)树形结构:数据元素之间是一对多的有层次的关系。
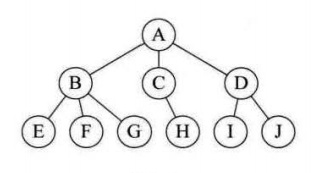
(3)图形结构:数据元素之间是多对多的平行关系。

(4)集合结构:类似数学中的集合,各个数据元素之间除了同属于一个集合外,无其他关系。各个数据元素之间是平等的。

2.2、物理存储结构
物理存储结构是指数据的逻辑结构在计算机内部中的存储方式。
数据的存储结构应正确反映数据元素之间的逻辑关系,这才是最关键的。
物理存储结构有以下两种:
(1)顺序存储结构:把数据元素存放在内存地址连续的存储单元里,其数据间的逻辑关系和存储关系一致。具体表现形式为数组。
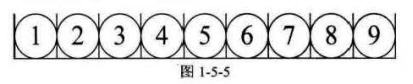
(2)链式存储结构:把数据元素存放在任意的存储单元里,这样的存储关系不能反映其逻辑关系,因此数据元素需要使用指针来存放后续数据元素的地址,使数据元素之间形成关联,以此来反映其逻辑关系。具体表现形式为链表。

2.3、逻辑关系结构与物理存储结构的关系
逻辑关系结构是面向问题的,物理存储结构是面向计算机的,其基本目标就是将数据及其逻辑关系存储到计算机内存中。
而具体问题的数据结构则是指逻辑关系结构和物理存储结构之间的搭配方式,就会有八种搭配方式。
例如,可以使用数组(顺序存储结构)来实现线性结构,也可以使用链表(链式存储结构)来实现线性结构。
3、算法
算法就是一组完成任务的指令,用于解决具体问题,任何解决一个具体问题的完整代码都可以视为一种算法,而平时只有比较难的问题解决方式,我们才以某某算法相称,而一些简单的问题解决方式,我们则会忽略它是算法。
把大象装进冰箱分为几步?第一步:打开冰箱门,第二步:把大象放进去,第三步:关上冰箱门。没错,这就应该是一个完整的算法。
算法的定义:算法是解决特定问题的求解步骤的描述,在计算机中表现为指令的有限序列。
算法的特性:
(1)输入和输出:算法具有零个或多个的输入,一个或多个的输出。
(2)有穷性:算法在执行有限步骤后会自动结束而不会无限循环,并且每步执行时间应在可接受的范围内。
(3)确定性:算法的每一步都具有确定的含义,不会出现二义性或无法衡量。错误示范:你好漂亮,我有点喜欢你,请问有点喜欢是多喜欢?计算机:这TM怎么衡量。
(4)可行性:算法每一步都必须是可行的,能够通过执行有限次数完成。
算法的设计要求:
(1)正确性:算法具有输入、输出和加工处理无歧义性,首要目的是能够正确反映问题需求或得到问题的正确答案。
(2)可读性:算法设计的另一个重要目的是为了便于阅读、理解和交流。
(3)健壮性:当输入不合理时,算法也能做出处理,而不是出现异常或崩溃。
(4)时间效率高和存储量低:在生活中,人们都希望花最少的钱、用最少的时间,完美的去做一件事。算法同样如此,用最少的时间、最小的存储空间去解决问题。但有时二者不可兼得,我们需要进行取舍,鉴于计算机性能的提升,基本会用空间来换时间。
3.1、算法效率度量
谈算法不谈算法效率==耍流氓
算法效率,也称算法时间复杂度,没有特殊说明,一般指时间效率,使用大O表示法来表示。
算法效率主要受执行的指令条数影响。
我们举个栗子来说明大O表示法。
写一个求1+2+3+4+...+100结果的程序。
(1)第一种算法,这是我们第一时间会得出的算法:
int i, sum = 0, n = 100; /*执行1次*/
for (i = 1; i <= n; i++) /*执行n+1次*/
{
sum = sum + i; /*执行n次*/
}
printf(" %d ", sum); /*执行1次*/(2) 高斯算法,本问题效率最高的算法:
int i,n = 100; /*执行1次*/
sum = (1 + n) * n / 2; /*执行1次*/
printf(" %d ", sum); /*执行1次*/第一种算法执行了2n+3次;第二种算法执行了3次。事实上,两个算法的定义和输出是一样的,且这是必要的无法省略,所以我们只需要关注真正实现功能的中间部分。那么两个算法就是2n+1次和1次的区别,算法效率差别显而易见。
使用大O表示法来表示这两个算法的效率为:O(n)和O(1)。
你可能会问不应该是O(2n+1),O(1)吗?
那么我们来看一个表格:
| 次数 | O(n) | O(2n+1) | O(n²) |
|---|---|---|---|
| n=1 | 1 | 3 | 1 |
| n=2 | 2 | 5 | 4 |
| n=10 | 10 | 21 | 100 |
| n=100 | 100 | 201 | 10000 |
| n=10000 | 10000 | 20001 | 100000000 |
| n=1000000 | 1000000 | 2000001 | 1000000000000 |
从这个表格我们可以看出,O(n)和O(2n+1)随着n的增大,两者之间的差别并不是很大,并且加法常数几乎可以省略;O(n)或O(2n+1)与O(n²)相比较,在n=10之后,差别开始越来越大。在这样的比较中,O(n)和O(2n+1)中的最高次项相乘的常数,对比较结果而言几乎没有影响。同理,如果是O(n²)与O(n²+2n+1)相比较,其中2n+1的影响也微乎其微,同样可以省略。
所以我们得出结论:使用大O表示法只关注最高项,最高项的相乘常数和其他次要项都可以忽略。大O表示法可以用来估计算法随着规模的增大,算法效率或算法时间复杂度的增长趋势。
常用时间复杂度所耗费的时间从小到大:
O(1)<O(㏒n)<O(n)<O(n㏒n)<O(n²)<O(n³)<O(2ⁿ)<O(n!)<O(nⁿ)

对于O(n³)而言,n稍微增大一些就是噩梦了,何况O(2ⁿ)、O(n!)和O(nⁿ),哪怕n只等于100,得到结果时人类都毁灭了。所以我们平时最多能接受O(n²)及以下的的时间复杂度。
下面来学习一下各阶时间复杂度是如何推导出来的,由于常数阶和线性阶比较好理解,且上述栗子已有不说明。
对数阶:count乘2是翻倍靠近N,也就是有多少个2相乘后大于N,可以得到2ⁿ=N => n=㏒N,所以其时间复杂度是O(㏒n)。代表算法为二分查找。
int count = 1, N = 100;
while (count < N)
{
count *= 2;
/*其他时间复杂度为O(1)的步骤*/
}
平方阶:平方阶也比较好理解,双重循环嵌套,且循环次数都为n。双重循环嵌套存在很多变式,不一一演示推导过程,但是它们的时间复杂度通常也是平方阶。代表算法为冒泡排序。
int i, j, n = 100;
for (i = 1; i <= n; i++)
{
for (j = 1; j <= n; j++)
{
/*时间复杂度为O(1)的步骤*/
}
}
4、数据结构与算法
程序设计=数据结构+算法
学过或看过数据结构与算法课程或者书籍,应该看到过上面这句话。数据结构与算法是相生相伴的,就比如梁山伯与祝英台、罗密欧与朱丽叶的关系。如果只谈数据结构,不谈算法,就像去话剧院看《梁山伯》,因为祝英台演员生病请假了,话剧变成梁山伯的独角戏,讲诉梁山伯的心路历程,感觉非常怪异。数据结构在算法中体现价值。
参考文献:《大话数据结构》《算法图解》