基础:EM算法和高斯混合模型、EM算法
EM算法是一种迭代算法,用于含有隐变量的概率模型的极大似然估计,或者说是极大后验概率估计。
1、EM算法
EM算法的具体流程如下:
输入:观测变量数据Y,隐变量数据Z,联合分布P(Y, Z|θ),条件分布P(Z|Y, θ)
输出:模型参数θ
1)选择参数θ的初始值θ(0),开始迭代
2)E步:记θ(i)次迭代参数为θ的估计值,在第i+1次迭代的E步,计算(基于当前求得的模型参数θ猜测隐变量的期望值,因此E步也称为期望步)
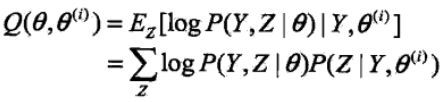
3)M步:求使得Q函数极大化的θ值,确定第i+1次迭代的参数的估计值θ(i+1)
![]()
4)重复2, 3步直至收敛
注意:EM算法是对初始化参数敏感的
5、总结
期望最大算法(EM算法)是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。
2、高斯混合模型(GMM)
用EM算法来估计高斯混合模型的参数,在这里参数θ = (α1,α2,...,αk;θ1,θ2,...,θk),在估计之前我们得预先明确隐变量。
因此就引出了我们的隐变量,隐变量的具体表达式如下:

γjk是0-1随机变量,确定了观测变量和隐变量之后,那么完全数据就是
![]()
之后就可以用EM算法去估计参数θ,具体流程如下
1)初始化θ值,开始迭代
2)E步:依照当前的模型参数,计算
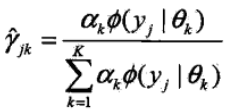
3)M步:计算新一轮迭代的模型参数

4)重复2, 3步直至算法收敛
其实高斯混合模型和K-means(也可以用EM算法描述)方法很相似,简单来说,K-means的结果是每个数据点被分配到其中某一类中,而高斯混合模型是给出这些点被分配给某一类的概率,可以看作是软聚类(也就是允许两个类之间有重合区域)。高斯混合模型是对初始值敏感的,也就是说如果运气不好,选取的初始值不好,最终的模型结果也不会很好,因此很多时候我们会用K-means做预训练,获得较好的结果,然后再用高斯混合模型进行训练进一步优化预测结果(高斯混合模型也是要给出聚类的簇数K值,在初始化参数时给出的)具体的做法就是:先用K-means粗略的估计出簇心,然后将簇心作为高斯混合模型的初始均值(μ值),然后再去估计高斯混合模型中的参数。