前言
在经过历时四个月的学习,把利用Python进行数据分析一书已经全部看完,作为Python以及数据分析刚入门的我,这本书对我帮助很大。在此,我将在学习此书的过程总结起来,以便日后的复习使用。
在看这本书之前我已经读过了《Python编程从入门到实践》一书,所以看这本书的时候我是从第三章开始读起的,我使用的是Jupyter Notebook工具执行的Python语句。下面会按照章节的小结来进行总结。
目录
1.元组
2.列表
3.字典
4.集合
5.列表、集合和字典的推导式(难点)
6.文件操作系统
正文
1.元组
元组的定义
元组是一种固定长度,不可变的Python对象序列(引自《利用Python进行数据分析》一书第54页)
在这里有个特殊的例子就是,当元组中的一个对象本身是可变类型的时候,可以对这个可变类型对象进行修改,这是作为子对象的内部修改,不违背元组的定义。
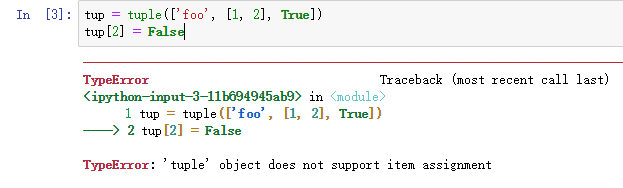
这里的修改报错
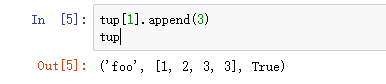
这里的修改是可行的
在定义元组的时候有一个问题需要注意
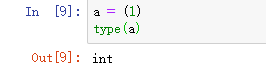
这里的a变量并不是一个元组类型的变量。
Python为了区别元组和整型变量,在定义只有一个整型元素的元组的时候,需要在数字后面加上逗号
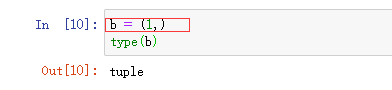
元组的拆包
元组的拆包个人认为是Python中一个很有趣的实现
tup = (4, 5, 6)
a, b, c = tup
a =4
2.列表
列表在Python中的应用可谓是非常之多。
利用append方法可以将元素添加到列表的尾部,insert方法可以将元素插入到指定的列表的位置,使用in关键字可以检查一个值是否在列表中
与字典、集合相比,检查列表中是否包含一个值是非常缓慢的。这是因为Python在列表中进行了线性逐个扫描。
利用sort和sorted可以对列表进行排序
IN [] : a = [9, 2, 3, 1, 0]
a.sort()
a
[Out]: [0, 1, 2, 3, 9]
IN [] : a = [9, 2, 3, 1, 0]
sorted(a)
[Out]: [0, 1, 2, 3, 9]
IN [] : a
[Out]: [9, 2, 3, 1, 0]
从上面的三段代码中我们可以看出sort函数对列表进行排序将列表本身也改变了,而sorted函数排序之后生成了一个拷贝列表,没有改变原列表。
切片
切片的使用使得对列表型元素的访问变得十分方便。基本形式是start: stop
返回的子集中包含start位置的元素,不包括stop位置的元素
zip
zip将列表、元组或其他序列的元素配对,新建一个元组构成的列表
IN [] : seq1 = ['foo', 'bar', 'baz']
seq2 = ['one', 'two', 'three']
zipped = zip(seq1, seq2)
list(zipped)
[out]: [('foo', 'one'), ('bar', 'two'), ('baz', 'three')]
3. 字典
与java的HashMap以及json格式的字符串十分类似,Python中的字典也是键值对形式的数据结构
可以使用del关键字或pop方法删除值,pop方法会在删除的同时返回被删除的值
删除均是按照键删除对应的值
4. 集合
集合是一种无序且元素唯一的容器。你可以认为集合也像字典,但是只有键没有值。
集合可以通过set函数来创建
set([2, 2, 2, 1, 3, 3])
{1, 2, 3}
集合保证的元素的唯一性
5. 列表、集合和字典的推导式
列表推导式是最受欢迎的Python语言特性之一。它允许你过滤一个容器的元素,用一种简明的表达式转换传递给过滤器的元素,从而生成一个新的列表。
IN [] : strings = ['a', 'as', 'bat', 'car', 'dove', 'python']
[x.upper() for x in strings if len(x) > 2]
[Out] : ['BAT', 'CAR', 'DOVE', 'PYTHON']
这里推导式可以解读为:遍历strings列表中的元素,将长度大于2的元素全部转为大写,然后生成一个新的列表
在遇到更为复杂的推导式的时候,我们要逐步解读推导式要哪些元素,并且对这些元素做什么操作
6.文件与操作系统
在以后的数据分析中,我们的数据源会以各种形式的方式存储下来,比如txt格式、csv格式、xlsx格式等等。Python提供了许多高级工具从硬盘中读取数据转换为Python数据格式
IN [] : path = 'segismundo.txt'
f = open(path)
lines = [x.rstrip() for x in f]
lines
[Out]: ['Sue帽a el rico en su riqueza,',
'que m谩s cuidados le ofrece;',
'',
'sue帽a el pobre que padece',
'su miseria y su pobreza;',
'',
'sue帽a el que a medrar empieza,',
'sue帽a el que afana y pretende,',
'sue帽a el que agravia y ofende,',
'',
'y en el mundo, en conclusi贸n,',
'todos sue帽an lo que son,',
'aunque ninguno lo entiende.',
'']