
Mapreduce 计算框架
如果将Hadoop比做一头大象,那么MapReduce就是那头大象的电脑。MapReduce是 Hadoop 核心编程模型。
在 Hadoop 中,数据处理核心就是 MapReduce 程序设计模型。
本章内容:
1) MapReduce 编程模型
2) MapReduce 执行流程
3) MapReduce 数据本地化
4) MapReduce 工作原理
5) MapReduce 错误处理机制
1. MapReduce 编程模型
Map和Reduce的概念是从函数式变成语言中借来的,整个MapReduce计算过程分为 Map 阶段和 Reduce阶段, 也称为映射和缩减阶段, 这两个独立的阶段实际上是两个独立的过程,即 Map 过程和 Reduce 过程,在 Map 中进行数据的读取和预处理,之后将预处理的结果发送到 Reduce 中进行合并。
我们通过一个代码案例,让大家快速熟悉如何通过代码,快速实现一个我们自己的MapReduce。
案例:分布式计算出一篇文章中的各个单词出现的次数, WordCount。
1) 创建 map.py 文件,写入以下代码:
#!/usr/bin/env python
import sys
word_list = []
for line in sys.stdin:
word_list = line.strip().split(' ')
if len(word_list) <= 0:
continue
for word in word_list:
w = word.strip()
if len(w) <= 0:
continue
print '\t'.join([w, "1"])该代码主要工作是从文章数据源逐行读取,文章中的单词之间以空格分割,word_list = line.strip().split(' ')
这块代码是将当前读取的一整行数据按照空格分割,将分割后的结果存入 word_list 数组中,
然后通过 for word in word_list 遍历数组,取出每个单词,后面追加“1” 标识当前 word 出现 1 次。
#!/usr/bin/env python
import sys
cur_word = None
sum_of_word = 0
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
word = ss[0].strip()
count = ss[1].strip()
if cur_word == None:
cur_word = word
if cur_word != word:
print '\t'.join([cur_word, str(sum_of_word)])
sum_of_word = 0
cur_word = word
sum_of_word += int(count)
print '\t'.join([cur_word, str(sum_of_word)])
sum_of_word = 0该代码针对 map 阶段的数组进行汇总处理,map 到 reduce 过程中默认存在 shufflepartition 分组机制,
保证同一个 word 的记录,会连续传输到 reduce 中, 所以在 reduce阶段只需要对连续相同的 word 后面
的计数进行累加求和即可。
本地模拟测试脚本
cat big.txt | python map.py | sort -k1 | python reduce.py
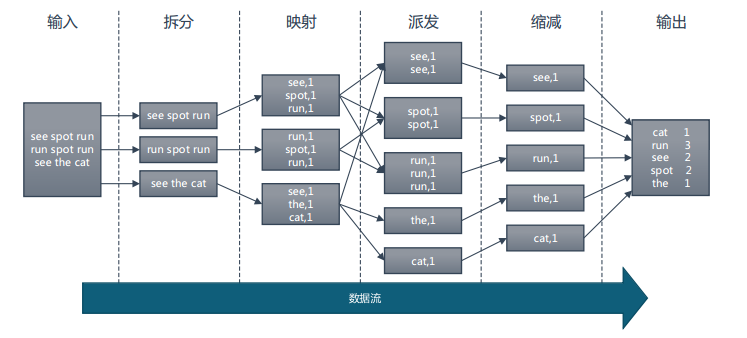
2. MapReduce 执行流程
上面的例子属于 MapReduce 计算框架的一般流程,经过整理总结: