一、在yarn-site.xml文件中添加日志监控支持
该配置中添加下面的配置:
<!-- 开启日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志时长 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
</property>
<!-- 日志聚合目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/usr/container/logs</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
</property>
二、在mapred-site.xml文件中添加日志服务的配置
该配置文件中添加如下配置:若是有了的话,无需再次添加
<property>
<!-- 表示提交到hadoop中的任务采用yarn来运行,要是已经有该配置则无需重复配置 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--日志监控服务的地址,一般填写为nodenode机器地址 -->
<name>mapreduce.jobhistroy.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistroy.webapp.address</name>
<value>master:19888</value>
</property>
scp 命令将配置文件拷贝覆盖到其他机器
四、重新启动集群的Hdfs和Yarn服务
./start-all.sh
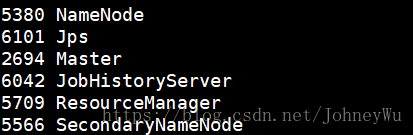
五、 开启日志监控服务进程
在nodenode机器上执行 sbin/mr-jobhistory-daemon.sh start historyserver 命令,执行完成后使用jps命令查看是否启动成功,若启动成功则会显示出JobHistoryServer服务